Leetcode using AI
🤖
GPT-2 Model for Leetcode Questions in python New demo here: https://huggingface.co/spaces/gagan3012/project-code-py
Note: the Answers might not make sense in some cases because of the bias in GPT-2 Current accuracy is capped at 90%.
Contribtuions: If you would like to make the model/UI better contributions (Issues/PRs) are welcome Check out CONTRIBUTIONS
How I built this : Linkedin
📢
Favour:
It would be highly motivating, if you can STAR
Model
Two models have been developed for different use cases and they can be found at https://huggingface.co/gagan3012
The model weights can be found here: GPT-2 and DistilGPT-2
The model has been trained using Weights and Biases (Wandb) and PyTorch
GPT Neo model: https://huggingface.co/gagan3012/project-code-py-neo
Example usage:
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("gagan3012/project-code-py")
model = AutoModelWithLMHead.from_pretrained("gagan3012/project-code-py")
Demo
A streamlit webapp has been setup to use the model: https://share.streamlit.io/gagan3012/project-code-py/app.py
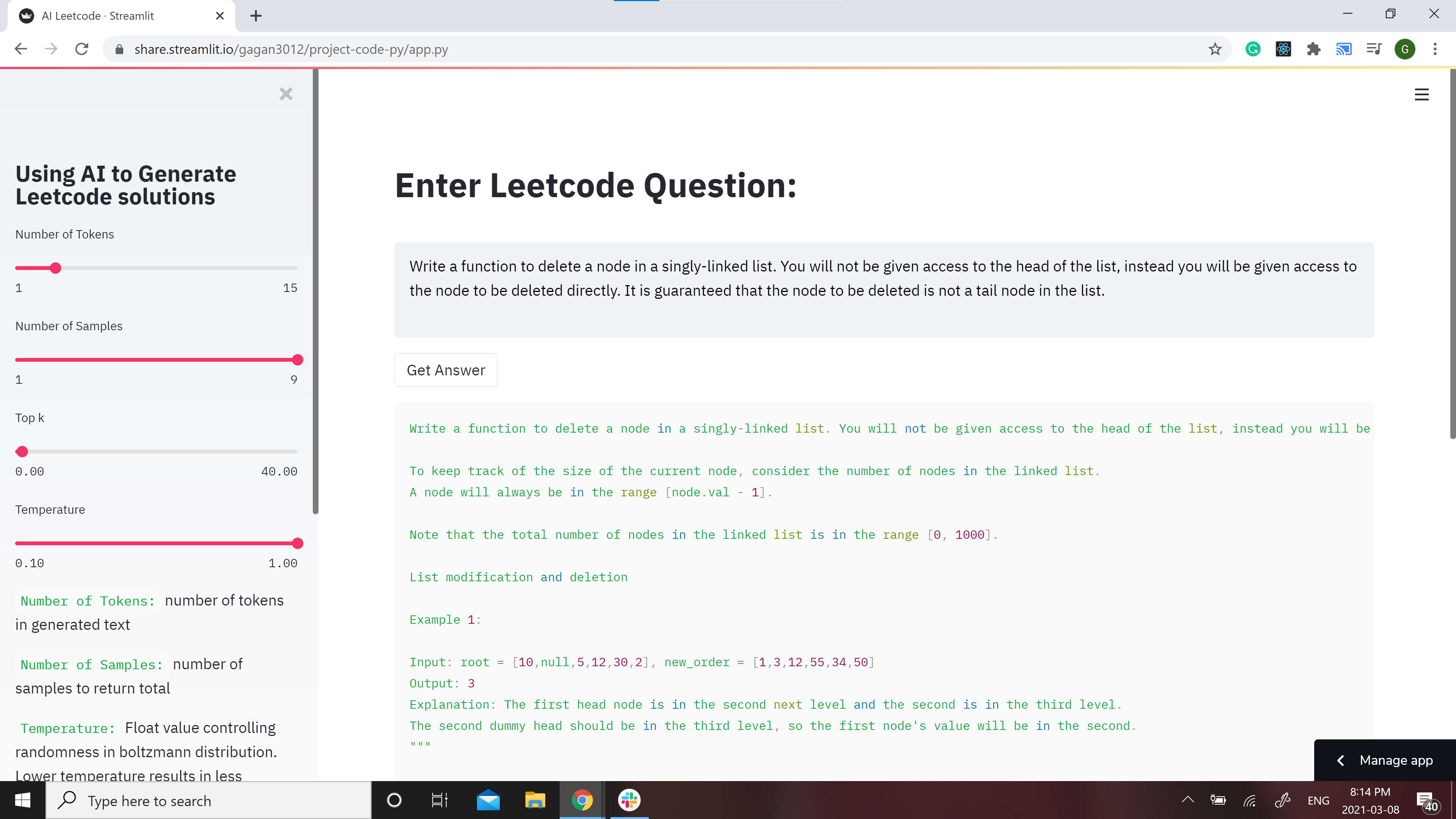
Please create an issue in this repo if the demo is not working
Example results:
Question:
Write a function to delete a node in a singly-linked list. You will not be given access to the head of the list, instead you will be given access to the node to be deleted directly. It is guaranteed that the node to be deleted is not a tail node in the list.
Answer:
""" Write a function to delete a node in a singly-linked list. You will not be given access to the head of the list, instead you will be given access to the node to be deleted directly. It is guaranteed that the node to be deleted is not a tail node in the list.
For example,
a = 1->2->3
b = 3->1->2
t = ListNode(-1, 1)
Note: The lexicographic ordering of the nodes in a tree matters. Do not assign values to nodes in a tree.
Example 1:
Input: [1,2,3]
Output: 1->2->5
Explanation: 1->2->3->3->4, then 1->2->5[2] and then 5->1->3->4.
Note:
The length of a linked list will be in the range [1, 1000].
Node.val must be a valid LinkedListNode type.
Both the length and the value of the nodes in a linked list will be in the range [-1000, 1000].
All nodes are distinct.
"""
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, x):
# self.val = x
# self.next = None
class Solution:
def deleteNode(self, head: ListNode, val: int) -> None:
"""
BFS
Linked List
:param head: ListNode
:param val: int
:return: ListNode
"""
if head is not None:
return head
dummy = ListNode(-1, 1)
dummy.next = head
dummy.next.val = val
dummy.next.next = head
dummy.val = ""
s1 = Solution()
print(s1.deleteNode(head))
print(s1.deleteNode(-1))
print(s1.deleteNode(-1))

 70 Dec 26, 2022
70 Dec 26, 2022
 65 Dec 30, 2022
65 Dec 30, 2022
 514 Nov 17, 2022
514 Nov 17, 2022
 29 Oct 23, 2022
29 Oct 23, 2022
 1 Jan 03, 2022
1 Jan 03, 2022
 66 Jul 05, 2022
66 Jul 05, 2022
 106 Jan 01, 2023
106 Jan 01, 2023
 290 Dec 20, 2022
290 Dec 20, 2022
 678 Jan 05, 2023
678 Jan 05, 2023
 33 Dec 27, 2022
33 Dec 27, 2022
 137 Oct 26, 2022
137 Oct 26, 2022
 46 Dec 28, 2022
46 Dec 28, 2022
 315 Jan 01, 2023
315 Jan 01, 2023
 3k Jan 06, 2023
3k Jan 06, 2023
 89 Dec 18, 2022
89 Dec 18, 2022
 1 Jul 08, 2022
1 Jul 08, 2022
 1 Feb 04, 2022
1 Feb 04, 2022
 59 Dec 01, 2022
59 Dec 01, 2022
 17.1k Jan 09, 2023
17.1k Jan 09, 2023
 71 Jan 04, 2023
71 Jan 04, 2023