当前位置:网站首页>Spark读取多目录
Spark读取多目录
2022-08-09 13:11:00 【南风知我意丿】
项目场景:
上游任务按类型生成json文件存放到hdfs上,会生成很多目录。
下游任务需要读取这些目录下得文件,生成df进行处理。
解决方案:
目录结构:
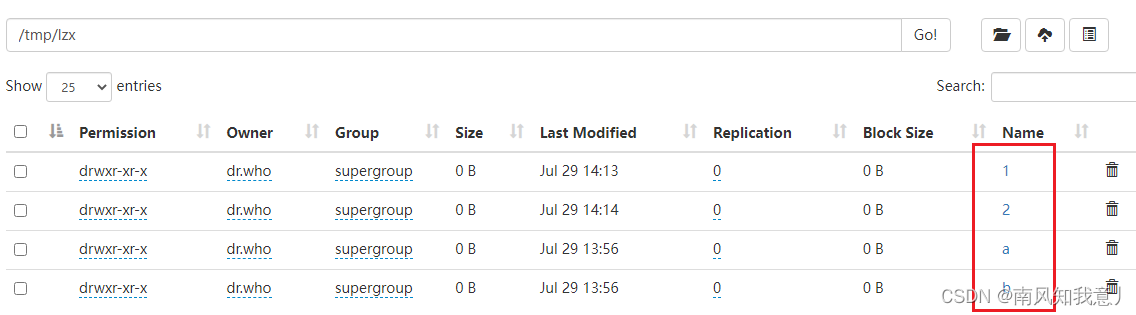
1.sparkContext
方式一
val session: SparkSession = SparkSession.builder().master("local[*]").appName("read_Muti_catalogue").getOrCreate()
val sc: SparkContext = session.sparkContext
import session.implicits._
//方式一:
sc.textFile("/tmp/lzx/a,/tmp/lzx/b").toDF().show(false)
方式二
val session: SparkSession = SparkSession.builder().master("local[*]").appName("read_Muti_catalogue").getOrCreate()
val sc: SparkContext = session.sparkContext
import session.implicits._
//2.1.方式二:匹配字符
val path1 = "/tmp/lzx/[a]"
val path2 = "/tmp/lzx/[b]"
val arryPath: Array[String] = Array(path1, path2)
val rdds: Array[RDD[String]] = arryPath.map(sc.textFile(_))
sc.union(rdds).toDF().show(false)
//2.2.方式二:匹配数字
val path3 = "/tmp/lzx/*1"
val path4 = "/tmp/lzx/*2"
val arryPath2: Array[String] = Array(path3, path4)
val rdds2: Array[RDD[String]] = arryPath2.map(sc.textFile(_))
sc.union(rdds2).toDF().show(false)
session.close()
2.sparkSession
//3.SparkSession
println("3.SparkSession-----------------------")
val path5 = "/tmp/lzx/*1"
val path6 = "/tmp/lzx/*2"
val arryPath3: Array[String] = Array(path5, path6)
// :_* 作为一个整体,一般可以用于获取一个数组的全部字段
//spark.read.textFile方法返回只有一列value的DataSet表。
val ds: Dataset[String] = session.read.textFile(arryPath3: _*)
ds.show()
//spark.read.text方法返回只有一列value的DataFrame表。
val df: DataFrame = session.read.text(arryPath3: _*)
df.show()
3.通配符使用说明
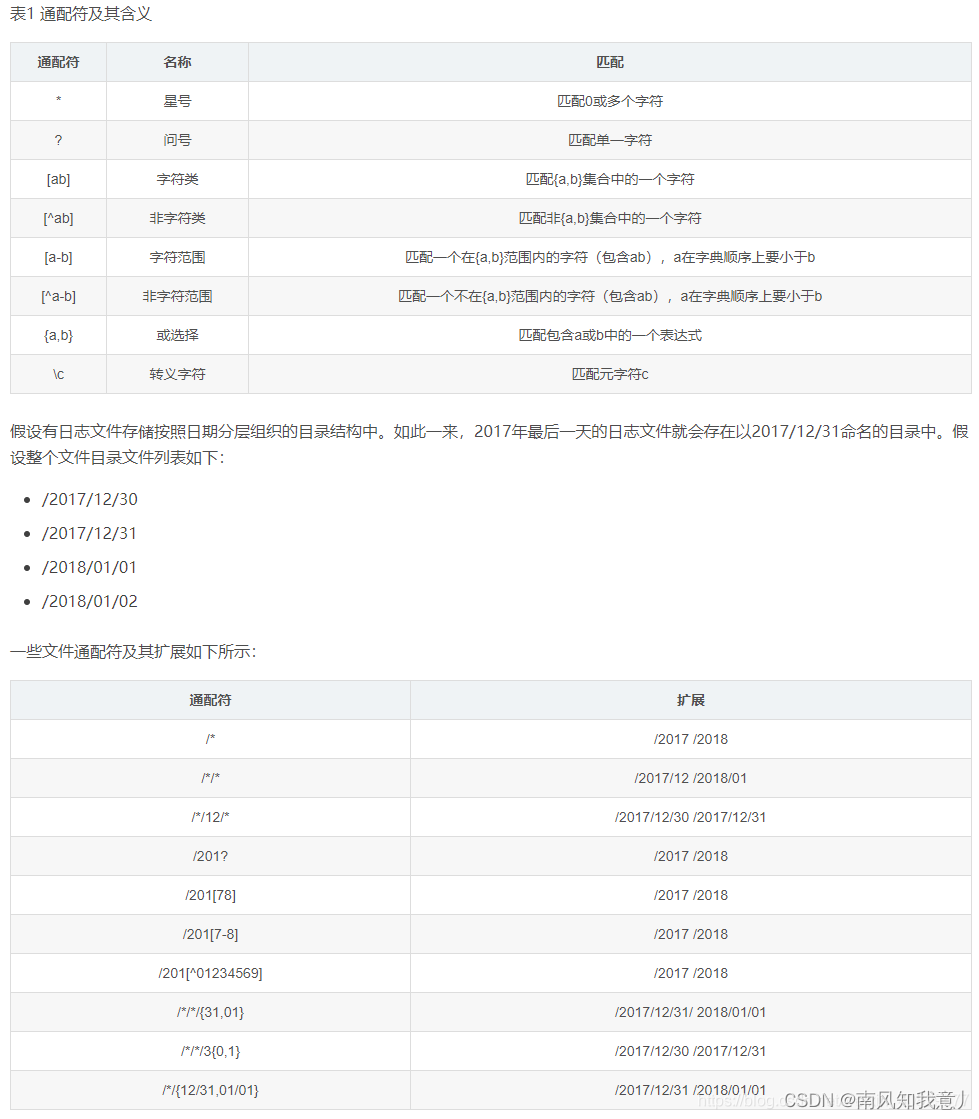
注意:
每个路径都要定位到最后一级。
路径之间不能存在包含关系。
目录与文件不要混放,即放在同一个目录下。
路径中可使用通配符
参考
https://blog.csdn.net/weixin_40829577/article/details/103847405
边栏推荐
- Professor Chen Qiang's "Machine Learning and R Application" course Chapter 13 Assignment
- 微信实现扫码支付(native)
- NC40 链表相加(二)
- Professor Chen Qiang's "Machine Learning and R Application" course Chapter 14 Assignment
- pytest 之 fixture参数化
- Q_04_07 进一步探索
- Ledong Fire Rescue Brigade was invited to carry out fire safety training for cadres
- 什么是布隆过滤器?如何使用?
- 常用函数
- group by的工作原理和优化思路
猜你喜欢
pytest 之 重运行机制与测试报告
RobotFramework 之 条件判断
RobotFramework简介
GIN Bind mode to get parameters and form validation

Unity3d_API_GPS_LocationService
微信实现扫码支付(native)

IDEA Gradle 常遇问题(一)
利用信号灯和共享内存实现进程间同步通信
error Trailing spaces not allowed no-trailing-spaces 9:14 error Unexpected trailing comma
RobotFramework 之 RF变量与标准库关键字使用
随机推荐
富媒体在客服IM消息通信中的秒发实践
客户端连接rtsp的步骤
Draw a histogram with plot_hist_numeric()
激光器如何养护才能远离结露没烦恼
FFmpeg multimedia file processing (ffmpeg prints audio and video Meta information)
The sword refers to Offer 57 - II. and is a continuous positive sequence of s (sliding window)
RTP打包发送H.264
蓝桥历届真题-门牌制作
搭建大型分布式服务(四)Docker搭建开发环境安装Mysql
R language kaggle game data exploration and visualization
vim常用命令
数据增广
处理JSON,fastjson、json-lib简单使用
RobotFramework 之 用户关键字
RobotFramework 之 条件判断
力扣解法汇总1413-逐步求和得到正数的最小值
机器学习web服务化实战:一次吐血的服务化之路 (转载非原创)
音频基础学习——声音的本质、术语与特性
opencv-matchTemplate 之使用场景为大图里面找小图
神经网络与深度学习(TensorFlow)