当前位置:网站首页>缓存和数据库一致性问题
缓存和数据库一致性问题
2022-08-09 13:01:00 【蹊源的奇思妙想】
缓存和数据库一致性问题
前言
在我们生产的过程中,我们会发现我们80%的业务是由20%的数据来驱动的,这20%的数据往往被我们称为热数据,这种现象也被称为二八定律。这种数据访问不均匀的现象,使得我们可以采用最有效的技术——缓存来提升我们整个系统的性能,但是用到缓存我们不可避免地要考虑一个问题缓存和数据库数据一致性的问题。
分布式下的数据一致性问题 可参考我的博客:分布式下的数据一致性问题
正文
缓存和数据库一致性问题
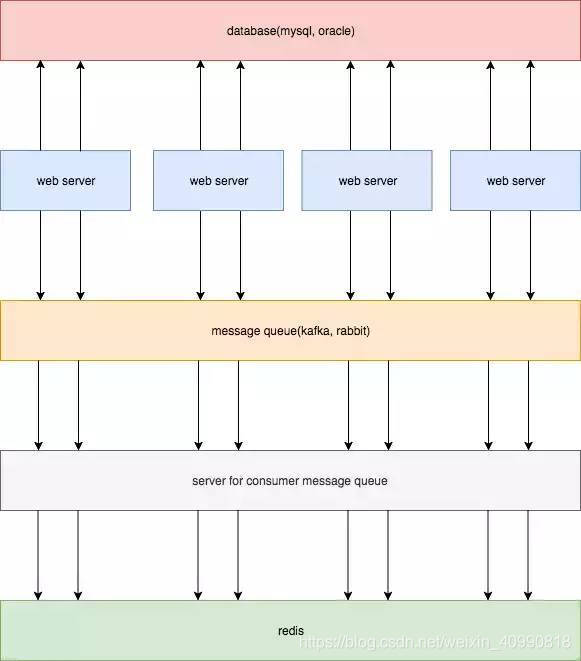
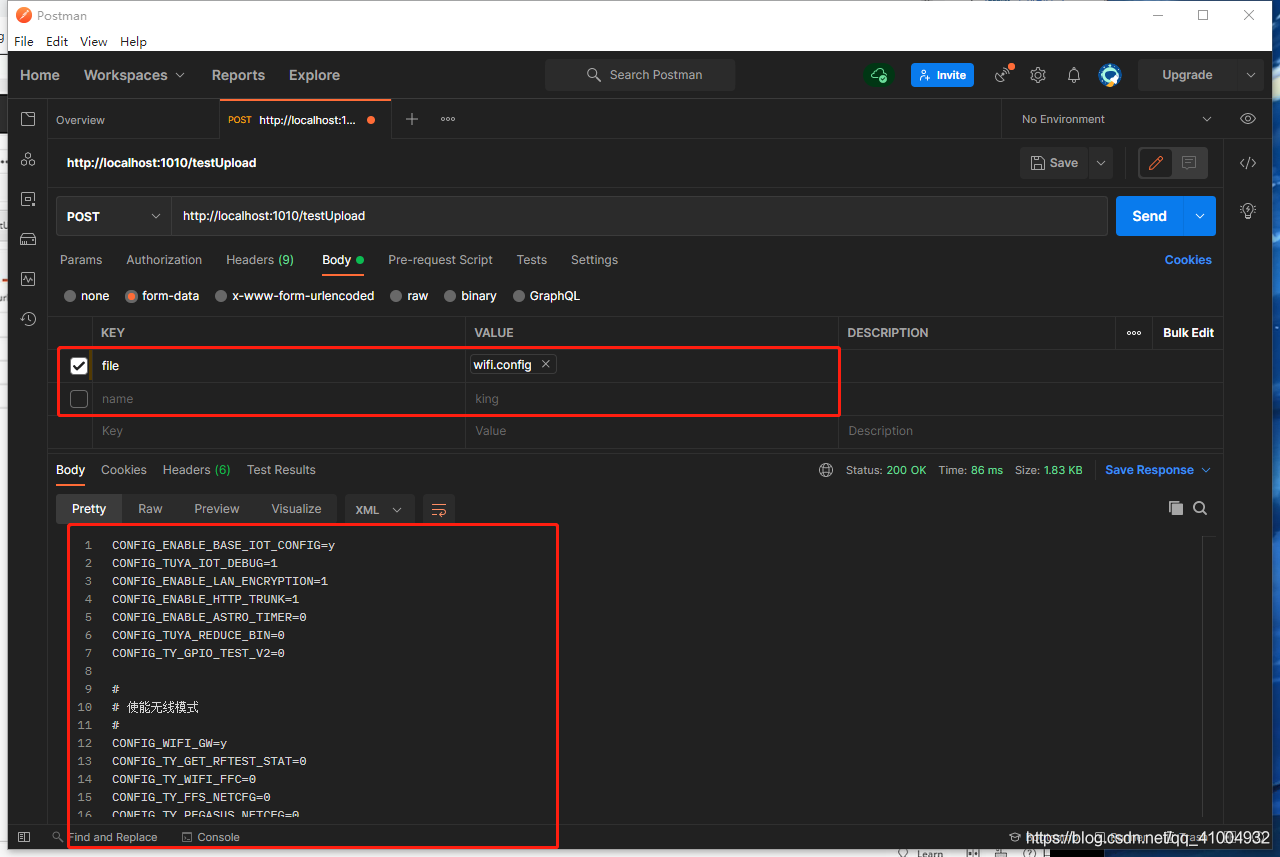
缓存和数据库双写一致性问题
- 强一致性:缓存和数据库数据始终保持一致
- 最终一致性:缓存和数据库数据有一段时间不一致,单不影响查询结果。
解决缓存一致性的解决方案
- 延时双删策略
- 通过消息队列来更新缓存
- 通过
binlog来同步mysql数据库到redis中
延时双删策略
延时双删策略一个写操作会进行以下流程:
- 先淘汰缓存
- 再写数据库
- 休眠1秒,再次淘汰缓存
接着我们要明确为什么要采用先淘汰缓存,再写数据库的策略。
先写数据库再更新缓存的弊端
1.线程安全方向(为什么要先操作缓存,再操作数据库)
同时有请求A和请求B进行更新操作,那么会出现:
- 线程A更新了数据库;
- 线程B更新了数据库;
- 线程B更新了缓存;
- 线程A更新了缓存;(A出现网络波动)
这就出现请求A更新缓存应该比请求B更新缓存早才对,但是因为网络等原因,B却比A更早更新了缓存。这就导致了脏数据。
并且这种情况只能等缓存失效,才能够得到解决,这样的话很大程度会对业务产生比较大的影响。
2.业务方向(为什么选择淘汰缓存,而不是更新缓存)
- 缓存的意义就是为了提升读操作的性能,如果你写操作比较频繁,频繁更新缓存且没有读操作,会造成性能浪费,所以应该由读操作来触发生成缓存,故而在写操作的时候应采用淘汰缓存的策略。
- 有的时候我们在存入缓存可能也会做一些其他转化操作,但是如果又立马被修改,也会造成性能的浪费。
采用先淘汰缓存,再写数据库事实上不是完美的方案,但是是相对而言最合理的方法,它有下面的特殊情况:
- 写请求A进行写操作,删除缓存;
- 读请求B查询发现缓存不存在;
- 读请求B去数据库查询得到旧值;
- 读请求B将旧值写入缓存;
- 写请求A将新值写入数据库;(这里不采取行动,会造成数据库与缓存数据不一致)
上述情况就会导致不一致的情形出现。
延时双删策略是为了解决采用先淘汰缓存,再写数据库可能造成数据不一致的问题,这个时候写请求A应采用休眠1秒,再次淘汰缓存的策略:
采用上述的做法,第一次写操作,会出现将近1秒(小于 1秒减去读请求操作时间)的数据不一致的问题,1秒后再次执行缓存淘汰,下次读操作后就会保证数据库与缓存数据的一致性了。
这里提到的1秒,是用来确保读请求结束(一般是几百ms),写请求可以删除读请求造成的缓存脏数据。
另外还存在一种极端情况是:如果第二次淘汰缓存失败,会导致数据和缓存一直不一致的问题,所以
- 缓存要设置失效时间
- 设置重试机制或者采用消息队列的方式保证缓存被淘汰。
通过消息队列来更新缓存
采用消息队列中间件的方式能够保证数据库数据与缓存数据的最终一致性。
- 实现了异步更新缓存,降低了系统的耦合性
- 但是破坏了数据变化的时序性
- 成本相对比较高
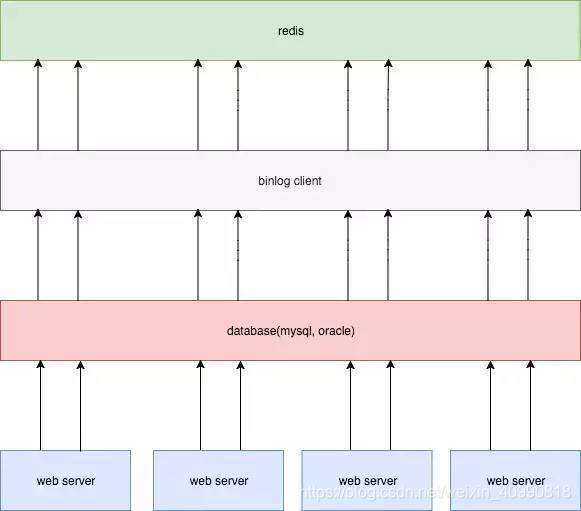
通过binlog来同步mysql数据库到redis中
Mysql数据库任何时间对数据库的修改都会记录在binglog中;当数据发生增删改,创建数据库对象都会记录到binlog中,数据库的复制也是基于binlog进行同步数据
- 在
mysql压力不大情况下,延迟较低; - 和业务完全解耦;
- 解决了时序性问题;
- 成本相对而言比较大。

边栏推荐
- NFS pays special attention to the problem of permissions
- 面试攻略系列(三)-- 高级开发工程师面试问些啥?
- 自己做了个nodejs+epxress+mysql的小项目,怎么才能让别人通过互联网访问呢?
- Record the system calls and C library functions used in this project-2
- ARM board adds routing function
- [MRCTF2020]套娃-1
- 陈强教授《机器学习及R应用》课程 第十四章作业
- Unicom network management protocol block diagram
- 19、学习MySQL 索引
- Flutter introduction advanced trip (5) Image Widget
猜你喜欢





随机推荐
记录本项目中用到的系统调用与C库函数-2
用plot_hist_numeric()实现画直方图
Microsoft 10/11 命令行打开系统设置页(WUAP,!WIN32)
JVM之配置介绍(一)
FFmpeg多媒体文件处理(FFMPEG日志系统)
5G China unicom 直放站 网管协议 实时性要求
Professor Chen Qiang's "Machine Learning and R Application" course Chapter 16 Assignment
Flutter Getting Started and Advanced Tour (7) GestureDetector
Explanation of RTSP protocol
【NVIDIA】Tesla V100安装NVIDIA-Driver驱动程序适配CUDA-Toolkit-11.6
正则引擎的几种分类
Jenkins API groovy calling practice: Jenkins Core Api & Job DSL to create a project
基于 R 语言的判别分析介绍与实践 LDA和QDA
glibc 内存管理模型 释放 C库内存缓存
剑指offer,剪绳子2
力扣解法汇总1413-逐步求和得到正数的最小值
Standing wave ratio calculation method
FPGA-在ISE中错误总结(更新中)
Final assignment of R language data analysis in a university
剑指 Offer 56 - II. 数组中数字出现的次数 II(位运算)