当前位置:网站首页>深度学习——特征工程小总结
深度学习——特征工程小总结
2022-04-23 19:19:00 【努力不躺平】
对于机器学习而言,一般步骤:
数据搜集—数据清洗—特征工程—数据建模
我们知道,特征工程包括特征构建,特征提取和特征选择。特征工程其实就是把原始数据转化为模型,以此来训练数据的过程。
特征构建
https://zhuanlan.zhihu.com/p/424518359 其他博主对于归一化的解释
在特征构建中,首先给我一堆数据,又多又乱,肯定要先给它数据规范化,让数据分布成我希望看到的样子。然后规范了之后,就需要数据预处理,特别是缺失值的处理、分类型特征处理、连续型特征的处理。
数据规范化:归一化处理:最大最小标准化、Z-Score标准化
那么他们两个最大的区别在哪呢?在于改不改变特征数据的分布。
最大最小标准化:会改变特征数据的分布
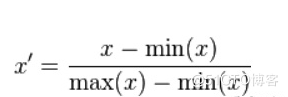
Z-Score标准化:不改变特征数据分布
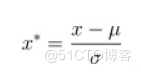
最大最小标准化:
- 线性函数将原始数据线性化的方法转换到[0 1]的范围, 计算结果为归一化后的数据,X为原始数据
- 本归一化方法比较适用在数值比较集中的情况
- 缺陷:如果max和min不稳定,很容易使得归一化结果不稳定,使得后续使用效果也不稳定。实际使用中可以用经验常量来替代max和min
- 应用场景:在不涉及距离度量、协方差计算、数据不符合正太分布的时候,可以使用第一种方法或其他归一化方法(不包括Z-score方法)。比如图像处理中,将RGB图像转换为灰度图像后将其值限定在[0 255]的范围
Z-Score标准化:
- 其中,μ、σ分别为原始数据集的均值和方法。
- 将原始数据集归一化为均值为0、方差1的数据集
- 该种归一化方式要求原始数据的分布可以近似为高斯分布,否则归一化的效果会变得很糟糕。
- 应用场景:在分类、聚类算法中,需要使用距离来度量相似性的时候、或者使用PCA技术进行降维的时候,Z-score standardization表现更好。
特征提取
那么在特征提取方法中,我们首先学到了数据划分:包括数据集是什么?给你一堆数据,你的拆分方法是什么?还有比较重要的降维方法:PCA,其实还有其他的方法,比如ICA,但是针对我的期末考试,就不重点记录了哈哈哈。
数据集:训练集、验证集、测试集
- 训练集:训练数据,调整模型参数、训练模型权重,构建机器学习模型
- 验证集:从训练集中分出的数据来验证模型的性能,作为评价模型性能指标
- 测试集:用新的数据输入训练集,来验证已经训练好的模型的好坏
拆分方法:留出法、K-折交叉验证法
- 留出法:将数据集划分为互斥的集合,保持拆分后集合数据的一致性
- K-折交叉验证法:将数据集拆分为K个大小相似的互斥子集,保证自己数据分布的一致性
为了把原始数据转换成有明显物理/统计意义的特征,就需要构建新的数据,采用的方法通常有PCA、ICA、LDA等。
那么为嘛要进行特征降维呢
- 消除噪声
- 进行数据压缩
- 消除数据的冗余
- 提高算法的精度
- 将数据维度减少至2维或3维,保持数据的可视性
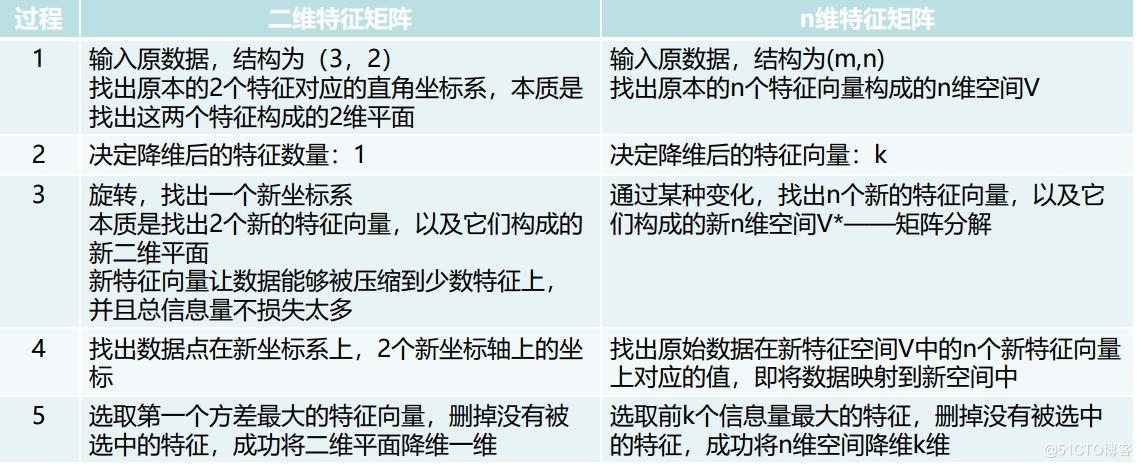
PCA(主成分分析):通过坐标轴的转换;寻找数据分布的最优子空间
- 输入原数据,结构为(m,n),找出原本的n个特征向量构成的n维空间
- 决定降维后的特征向量:K
- 通过某种变化,找出n个新的特征向量,以及它们构成的新的n维空间V*——矩阵分解
- 找出原始数据在新特征空间V中的n个新特征向量对应的值,即将数据映射到新空间
- 选取前K个信息量最大的特征,删掉未选中的特征,成功将n维空间降维K维
对于特征选择,有以下几种方法:过滤式、包裹式、嵌入式(了解即可)
最后,我们来了解一下超参数和参数的区别:
- 超参数:在开始学习模型之前设置的参数,人为设定,比如padding、stride、k-means的k、深度、卷积核个数和大小、学习率
- 参数:通过一系列的模型训练得到的参数,比如权重w和wx+b里的b。
版权声明
本文为[努力不躺平]所创,转载请带上原文链接,感谢
https://blog.51cto.com/u_15567091/5248722
边栏推荐
- Wechat video extraction and receiving file path
- JS controls the file type and size when uploading files
- RuntimeError: Providing a bool or integral fill value without setting the optional `dtype` or `out`
- Screen right-click menu in souI
- arcgis js api dojoConfig配置
- openlayers 5.0 加载arcgis server 切片服务
- Problems caused by flutter initialroute and home
- Raspberry pie 18b20 temperature
- 什么是消息队列
- Android Development: the client obtains the latest value in the database in real time and displays it on the interface
猜你喜欢
Intuitive understanding of the essence of two-dimensional rotation
2021-2022-2 ACM集训队每周程序设计竞赛(8)题解
ArcMap publishing slicing service
Oracle configuration st_ geometry
Installation, use and problem summary of binlog2sql tool
I just want to leave a note for myself
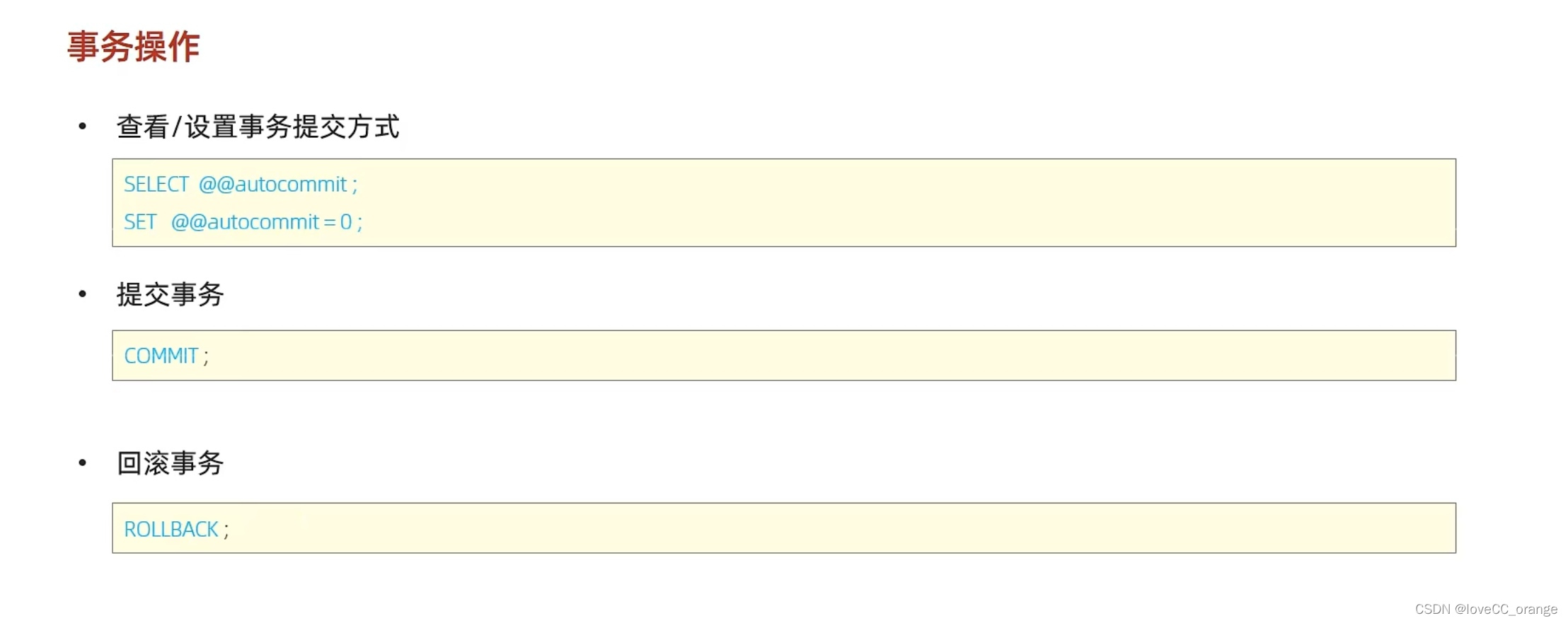
MySQL学习第五弹——事务及其操作特性详解

OpenHarmony开源开发者成长计划,寻找改变世界的开源新生力!
White screen processing method of fulter startup page
Introduction to micro build low code zero Foundation (lesson 3)
随机推荐
SQL Server database in clause and exists clause conversion
static类变量快速入门
Customize the non slidable viewpage and how to use it
SQL server requires to query the information of all employees with surname 'Wang'
12 examples to consolidate promise Foundation
The platinum library cannot search the debug process records of some projection devices
2022.04.23(LC_763_划分字母区间)
Openlayers 5.0 discrete aggregation points
Encyclopedia of professional terms and abbreviations in communication engineering
js 计算时间差
Gossip: on greed
Web Security
Class loading process of JVM
SQL of contention for system time plus time in ocrale database
Xlslib use
8266 obtain 18b20 temperature
高层次人才一站式服务平台开发 人才综合服务平台系统
Problems caused by flutter initialroute and home
FTP, SSH Remote Access and control
为何PostgreSQL即将超越SQL Server?