当前位置:网站首页>Redis持久化方案RDB详解
Redis持久化方案RDB详解
2022-08-11 05:22:00 【?671】
一、什么是Redis的持久化?
学过Redis的同学都知道Redis的数据都是在内存当中的,因此Redis必须要有持久化策略,如果没有持久化策略,你关闭Redis或者之后,你的数据有可能全部都丢失了。我们每再一次登录Redis访问上一次数据的时候,我们都看到了原来的数据,就是得益于Redis的持久化。Redis的持久化简单说就是,将Redis存在内存中的值存储到可以永久存储的地方(磁盘等)
二、Redis的持久化方案
- RDB Redis DataBase
- AOF Append Only File
三、RDB模式详解
1、RDB快照模式原理
RDB 即快照模式,它是 Redis 默认的数据持久化方式,它会将数据库的快照保存在 dump.rdb 这个二进制文件中。提示:所谓“快照”就是将内存数据以二进制文件的形式保存起来。
我们知道 Redis 是单线程的,也就说一个线程要同时负责多个客户端套接字的并发读写,以及内存数据结构的逻辑读写。
Redis 服务器不仅需要服务线上请求,同时还要备份内存快照。在备份过程中 Redis 必须进行文件 IO 读写,而 IO 操作会严重服务器的性能。那么如何实现既不影响客户端的请求,又实现快照备份操作呢,这时就用到了多进程。
Redis 使用操作系统的多进程 COW(Copy On Write) 机制来实现快照持久化操作。
RDB 实际上是 Redis 内部的一个定时器事件,它每隔一段固定时间就去检查当前数据发生改变的次数和改变的时间频率,看它们是否满足配置文件中规定的持久化触发条件。当满足条件时,Redis 就会通过操作系统调用 fork() 来创建一个子进程,该子进程与父进程享有相同的地址空间。
Redis 通过子进程遍历整个内存空间来获取存储的数据,从而完成数据持久化操作。注意,此时的主进程则仍然可以对外提供服务,父子进程之间通过操作系统的 COW 机制实现了数据段分离,从而保证了父子进程之间互不影响。
2、RDB持久化触发策略
RDB 持久化提供了两种触发策略:一种是手动触发,另一种是自动触发。
1) 手动触发策略
手动触发是通过SAVAE命令或者BGSAVE命令将内存数据保存到磁盘文件中。如下所示:
127.0.0.1:6379> SAVE OK 127.0.0.1:6379> BGSAVE Background saving started 127.0.0.1:6379> LASTSAVE (integer) 1611298430
上述命令BGSAVE从后台执行数据保存操作,其可用性要优于执行 SAVE 命令。
SAVE 命令会阻塞 Redis 服务器进程,直到 dump.rdb 文件创建完毕为止,在这个过程中,服务器不能处理任何的命令请求。BGSAVE命令是非阻塞式的,所谓非阻塞式,指的是在该命令执行的过程中,并不影响 Redis 服务器处理客户端的其他请求。这是因为 Redis 服务器会 fork() 一个子进程来进行持久化操作(比如创建新的 dunp.rdb 文件),而父进程则继续处理客户端请求。当子进程处理完后会向父进程发送一个信号,通知它已经处理完毕。此时,父进程会用新的 dump.rdb 文件覆盖掉原来的旧文件。
因为SAVE命令无需创建子进程,所以执行速度要略快于BGSAVE命令,但是SAVE命令是阻塞式的,因此其可用性欠佳,如果在数据量较少的情况下,基本上体会不到两个命令的差别,不过仍然建议您使用 BGSAVE命令。
注意:LASTSAVE 命令用于查看 BGSAVE 命令是否执行成功。
2) 自动触发策略
自动触发策略,是指 Redis 在指定的时间内,数据发生了多少次变化时,会自动执行BGSAVE命令。自动触发的条件包含在了 Redis 的配置文件中,如下所示:
上图所示, save m n 的含义是在时间 m 秒内,如果 Redis 数据至少发生了 n 次变化,那么就自动执行BGSAVE命令。配置策略说明如下:
- save 900 1 表示在 900 秒内,至少更新了 1 条数据,Redis 自动触发 BGSAVE 命令,将数据保存到硬盘。
- save 300 10 表示在 300 秒内,至少更新了 10 条数据,Redis 自动触 BGSAVE 命令,将数据保存到硬盘。
- save 60 10000 表示 60 秒内,至少更新了 10000 条数据,Redis 自动触发 BGSAVE 命令,将数据保存到硬盘。
只要上述三个条件任意满足一个,服务器就会自动执行BGSAVE命令。
注意:每次创建 RDB 文件之后,Redis 服务器为实现自动持久化而设置的时间计数和次数计数就会被清零,并重新开始计数,因此多个策略的效果不会叠加。
3、RDB是怎么实现持久化的
RDB是按照规则来触发持久化存储的,在我们的redis.conf中我们可以看到如下的几个配置:

上图所示, save m n 的含义是在时间 m 秒内,如果 Redis 数据至少发生了 n 次变化,那么就自动执行BGSAVE命令,生成一个快照文件dump.rdb,当Redis再次启动时就会通过该文件加载上次关闭时Redis的数据。
4、快照文件dump.rdb
RDB 是 Redis 默认的持久化方案。当满足一定条件的时候,会把当前内存中的数据写入磁盘,生成一个快照文件 dump.rdb。Redis 重启会通过加载 dump.rdb 文件恢复数据。dump.rdb是我们redis文件当中的一个,dump.rdb的位置可通过redis.conf文件进行设置,如下图:

5、RDB持久化的演示
如果我们都按照正常程序走的话,我们是很难看到没有持久化,或者出现持久化问题的故障现场的。所以我们要学会持久化操作,或者只管看到持久化就需要手动触发持久化问题。这里主要演示两种情况,一种是数据正常备份,一种是数据丢失,我们恢复备份数据。
(1)正常备份
启动redis服务端和客户端,使用flushdb清空数据库,方便接下来的演示。

设置几组数据存入redis

关闭redis服务端模拟宕机

重新启动redis服务端,启动客户端查看发现数据与上次宕机时数据一致。

(2)通过 dump.rdb 文件恢复数据
清空redis方便演示

设置几组数据存入redis

关闭redis服务端 模拟宕机
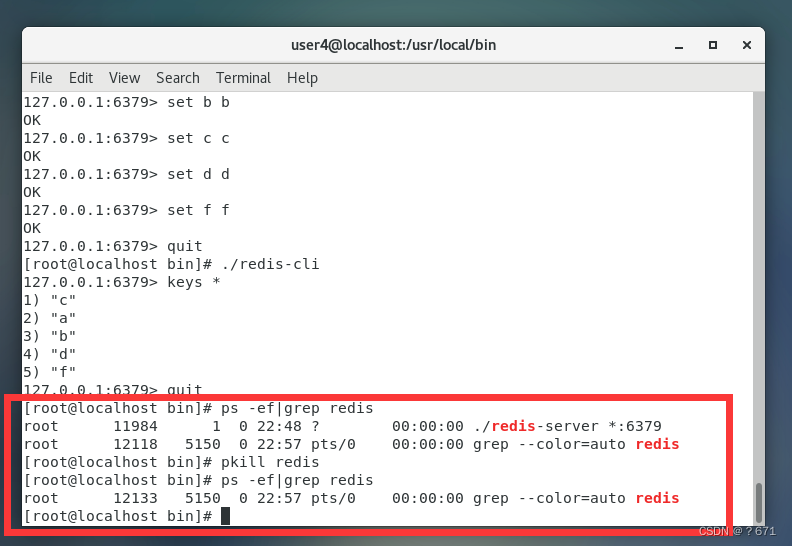
进入bin目录,将快照文件dump.rdb改名为d.rdb
 再次启动redis服务端客户端,查看上次关闭redis服务端时的数据是否存在,发现没有数据,这是因为redis找不到上次生成的快照文件dump.rdb,因此无法恢复上次宕机时redis的数据。
再次启动redis服务端客户端,查看上次关闭redis服务端时的数据是否存在,发现没有数据,这是因为redis找不到上次生成的快照文件dump.rdb,因此无法恢复上次宕机时redis的数据。

退出客户端,关闭redis服务器,将上次的d.rdb改回dump.rdb

 再次启动redis服务端客户端,查看数据
再次启动redis服务端客户端,查看数据

此时可以发现数据已经恢复与上次宕机时的数据一致了。
6、RDB方式的优缺点与适用情况
优点:
RDB 是一个紧凑的单一文件,很方便传送到另一个远端数据中心,非常适用于灾难恢复。
与AOF相比,在恢复大的数据集的时候,RDB 方式会更快一些。
缺点:
1、RDB 方式数据没办法做到实时持久化/秒级持久化。因为 bgsave 每次运行都要 执行 fork 操作创建子进程,频繁执行成本过高。
2、在 RDB 持久化的过程中,子进程会把 Redis 的所有数据都保存到新建的 dump.rdb 文件中,这是一个既消耗资源又浪费时间的操作。因此 Redis 服务器不能过于频繁地创建 rdb 文件,否则会严重影响服务器的性能。
3、RDB 持久化的最大不足之处在于,最后一次持久化的数据可能会出现丢失的情况。我们可以这样理解,在 持久化进行过程中,服务器突然宕机了,这时存储的数据可能并不完整,比如子进程已经生成了 rdb 文件,但是主进程还没来得及用它覆盖掉原来的旧 rdb 文件,这样就把最后一次持久化的数据丢失了。
适用情况:
RDB 数据持久化适合于大规模的数据恢复,并且还原速度快,如果对数据的完整性不是特别敏感(可能存在最后一次丢失的情况),那么 RDB 持久化方式非常合适。
边栏推荐
猜你喜欢
error: The following untracked working tree files would be overwritten by merge: .hbuilderx/launch

C - file operations fseek () function, ftell, rewind, rounding

《现代密码学》学习笔记——第五章 密钥分配与密钥管理
06-引入Express创建web服务器、接口封装并使用postman测试,静态资源托管
DOM破坏
NAT模式 LVS负载均衡群集部署
数组:一个存取数字的魔盒

07-JS事件:事件类型、事件对象、事件传播、事件委托

使用Go语言开发的低代码应用引擎

uniapp中设置tabBar及其窗口标题
随机推荐
为什么购买的磁盘实际空间比标注的空间少
二,八,十,十六进制转换
SQL注入
数据库基础-入门看这篇
LNMP源码搭建
工具窗口永远置顶
写博客周志
RIP综合实验
C language file operation - detailed explanation of data file type, file judgment, and file buffer
Markdown学习
ES11新增数据类型BigInt大整型
Laravel5.7反序列化
06-JS定时器:间隔定时器、延时定时器
MGRE环境下的OSPF综合实验
ES6-class类
emqx安装及mqttx连接使用
05-JS中的BOM和DOM
表单input控件数据双向绑定
云计算学习笔记——第五章 网络虚拟化
《现代密码学》学习笔记——第八章 身份鉴别