当前位置:网站首页>数据库索引原理
数据库索引原理
2022-08-09 07:04:00 【white_156】
总所周知索引由B树实现,通过B树实现对部分的字段的快速查找。假设B树的高度为 h h h,那么一次数据的查找只需要 O ( h ) O(h) O(h)次访问。此外,索引之所以会选用B树,而不是其他平衡树,像AVL树和红黑树,是考虑到数据库进行IO操作的次数。如果表中数据能全部加载到内存中,毫无疑问B树并不是最优选择,但是通常来说,表中数据无法全部加载内存中,只能从磁盘中读取部分数据加载,所以此时IO的次数成为了性能瓶颈。为此B树的实现上,增加非叶节点中的数据,使一次IO获得更多的信息。
B树的结构如下所示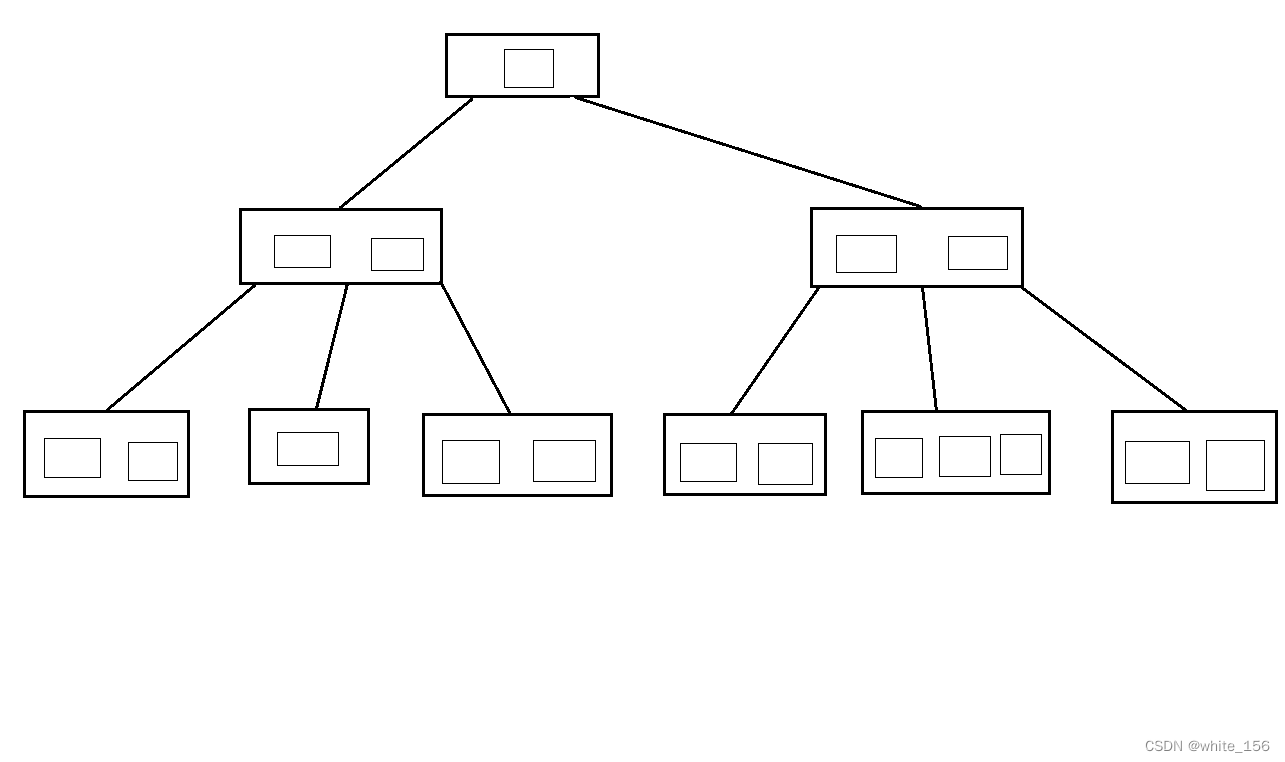
这里姑且不谈论B树insert以及其复杂的平衡操作,只是关注于如何查询索引。
与二叉树的查询过程类似,只不过二叉树每个节点只有一个值,而B树的非叶节点则有多个。

B树节点指示了子树的数据范围,所以查询时只需要顺序遍历节点中元素,并按指针地址去磁盘中寻找下一次需要加载到内存中的数据块,不断重复直到叶结点。
关于聚合索引(clustered index)和非聚合索引(nonclustered index)
聚合索引的叶结点所存储的就是数据本身,例如oracle中主键;而非聚合索引的叶结点仅记录能够标识数据的唯一标识,如果需要获取数据,则需要根据这个唯一标识进行回表查询
关于clustered 和 nonclustered index更加详细区别和应用场景,推荐阅读聚合索引(clustered index) / 非聚合索引(nonclustered index)
对于复合索引(compound index)来说,其实现仍然是B树,只是重载了比较运算。假设我们在列col1,col2,col3上建立复合索引,其排序逻辑如下
compare(a,b) {
if a.col1!=b.col1
return a.col1>b.col1
else if a.col2!=b.col2
return a.col2>b.col2
else if ...
}
所以不难得出为什么复合索引使用需要遵顼左前缀匹配的原则。
可以看到,只有列col1上的数据是有序的,确切来说是只有选取包含列col1的数据组合才是有序的,如(col1),(col1,col2),(col1,col3),(col1,col2,col3);而像(col2),(col2,col3)的数据在叶结点上仍然是无序的,所以无法通过索引来快速查询,仍需要通过全表扫描查询数据。
附1:
DML对索引的影响
INSERT
当查入数据时,也需要向索引中同步插入。由于索引是通过平衡树实现,因此插入时最糟的情况就是导致平衡树不平衡,需要旋转节点,可能导致叶结点一路旋转到根节点。又因为树节点存储在磁盘而不是内存,又将导致额外IO操作。
UPDATE
在表数据更新时,会将原数据逻辑删除,并创建一个新的叶结点来保存更新后的数据。如果将索引建立经常更新的列上,就会导致表的大小不变,而索引不断增大,因此索引列的选取应当避开经常发生更新的字段
DELETE
在执行删除操作时,同样也是逻辑删除,数据库并不会立即释放该条记录的物理空间,而是将这条数据标记已删除。当插入新的数据进入某个B树节点时,数据库才会释放这个节点中被标记为删除的记录。
如果索引建立在某个自增序列上,且按序列顺序连续删除记录,由于序列自增,导致后续加入的数据不会进入到有删除标记的树节点中,从而造成索引空间不能释放,产生碎片。
或者表中数据只有删除或者更新,很少有数据插入,也会造成大量被标记的数据不能被释放,产生碎片
附2:
- 索引和表一般要创建在不同表空间,提升IO性能。否则表IO和索引IO发生竞争,影响性能
- 对于一定要使用函数(to_char)的列作为索引,可以考虑使用函数索引。函数索引的键值不是数据中列的值,而是应用了这个函数的值
- 分区表不要建立全局索引,当分区删除后会导致索引失效
- 索引的key不能太长,否则导致树的高度上升
- 复合索引建议使用区分度高的列在前
参考文献
[1]: 图解:什么是B树?(心中有 B 树,做人要虚心)一文读懂B-树
[2]: 联合索引在B+树上的存储结构及数据查找方式
[3]: mysql 联合索引 数据结构是怎样的
[4]: B树索引
边栏推荐
猜你喜欢


随机推荐
2022 年全球十大最佳自动化测试工具
Lottie系列三 :原理分析
The working principle of the transformer (illustration, schematic explanation, understand at a glance)
排序第四节——归并排序(附有自己的视频讲解)
JSONObject遍历的时候顺序不一致,导致数据对应出错
【nuxt】服务器部署步骤
dp学习笔记
【sqlite3】sqlite3.OperationalError: table addresses has 7 columns but 6 values were supplied
unity第一课
训练好的深度学习模型,多种部署方式
leetcode:55. 跳跃游戏
2017 G icpc shenyang Infinite Fraction Path BFS + pruning
TCP段重组PDU
半导体新能源智能装备整机软件系统方案设计
常用测试用例设计方法之正交实验法详解
图论,二叉树,dfs,bfs,dp,最短路专题
顺序表删除所有值为e的元素
高德地图JS - 已知经纬度来获取街道、城市、详细地址等信息
更改Jupyter Notebook默认打开目录
AD的library中 库文件后缀有.intlib .schlib .pcblib 的区别