当前位置:网站首页>magical_spider远程采集方案
magical_spider远程采集方案
2022-08-11 07:47:00 【考古学家lx(李玺)】
magical_spider
一个神奇的蜘蛛项目,源码架构很简单,适用于数据采集任务。



index页面示例:

项目地址
https://github.com/lixi5338619/magical_spider
使用说明
1、配置settings.py,启动 flask 服务
2、测试代码参考demo文件内容,运行过程主要借助runflow.py。
import requests
host = 'http://127.0.0.1:5000'
def magical_start(project_name,base_url = 'http://www.lxspider.com'):
# 1、create browser and select session_id
result = requests.post(f'{
host}/create',data={
'name':project_name,'url':base_url}).json()
session_id,process_url = result['session_id'],result['process_url']
return session_id,process_url
def magical_request(session_id,process_url,request_url):
# 2、request browser_xhr
data = {
'session_id':session_id,'process_url':process_url,
'request_url':request_url,'request_type':'get'}
result = requests.post(f'{
host}/xhr',data=data).json()
return result['result']
def magical_close(session_id,process_url,process_name):
# 4、close browser
close_data = {
'session_id':session_id,'process_url':process_url,'process_name':process_name}
requests.post(f'{
host}/close',data=close_data).json()
3、测试代码
GET请求
from demo.runflow import magical_start,magical_request,magical_close
project_name = 'cnipa'
base_url = 'https://www.cnipa.gov.cn'
session_id,process_url = magical_start(project_name,base_url)
print(len(magical_request(session_id, process_url,'https://www.cnipa.gov.cn/col/col57/index.html')))
magical_close(session_id,process_url,project_name)
POST请求
from demo.runflow import magical_start,magical_request,magical_close
import json
project_name = 'chinadrugtrials'
base_url = 'http://www.chinadrugtrials.org.cn'
session_id,process_url = magical_start(project_name,base_url)
data = {
"id": "","ckm_index": "","sort": "desc","sort2": "","rule": "CTR","secondLevel": "0","currentpage": "2","keywords": "","reg_no": "","indication": "","case_no": "","drugs_name": "","drugs_type": "","appliers": "","communities": "","researchers": "","agencies": "","state": ""}
formdata = json.dumps(data)
print(magical_request(session_id=session_id, process_url=process_url,
request_url='http://www.chinadrugtrials.org.cn/clinicaltrials.searchlist.dhtml',
request_type='post',formdata=formdata
))
magical_close(session_id,process_url,project_name)
4、index页可以查看和管理当前运行中的任务,也能查看系统内存和磁盘使用情况。
5、demo文件夹中有任务流程汇总runflow.py,以及抖音、药监局案例,单任务和多任务示例。
linux部署
1.安装chrome (自行选择安装位置)
yum install https://dl.google.com/linux/direct/google-chrome-stable_current_x86_64.rpm
2.检查chrome的版本
google-chrome --version
3.安装对应版本的 chromedriver_linux64
比如我的chrome版本是104.0.5112.79
wget https://npm.taobao.org/mirrors/chromedriver/104.0.5112.79/chromedriver_linux64.zip
4.解压
unzip chromedriver_linux64
5.授权
chmod 777 chromedriver
6.修改项目代码settings.py中的chromedriver路径
7.安装python依赖后启动flask项目
- Python依赖 :flask、sqlite3、selenium、websockets、opencv-python、numpy
- flask启动方式:python3 server.py
8.开启服务器端口访问权限
9.运行项目测试
边栏推荐
- 零基础SQL教程: 主键、外键和索引 04
- 项目1-PM2.5预测
- 1002 Write the number (20 points)
- Mysql JSON对象和JSON数组查询
- 1.1-回归
- 如何仅更改 QGroupBox 标题的字体?
- 1046 划拳 (15 分)
- 1056 Sum of Combinations (15 points)
- Break pad source code compilation--refer to the summary of the big blogger
- Redis source code: how to view the Redis source code, the order of viewing the Redis source code, the sequence of the source code from the external data structure of Redis to the internal data structu
猜你喜欢
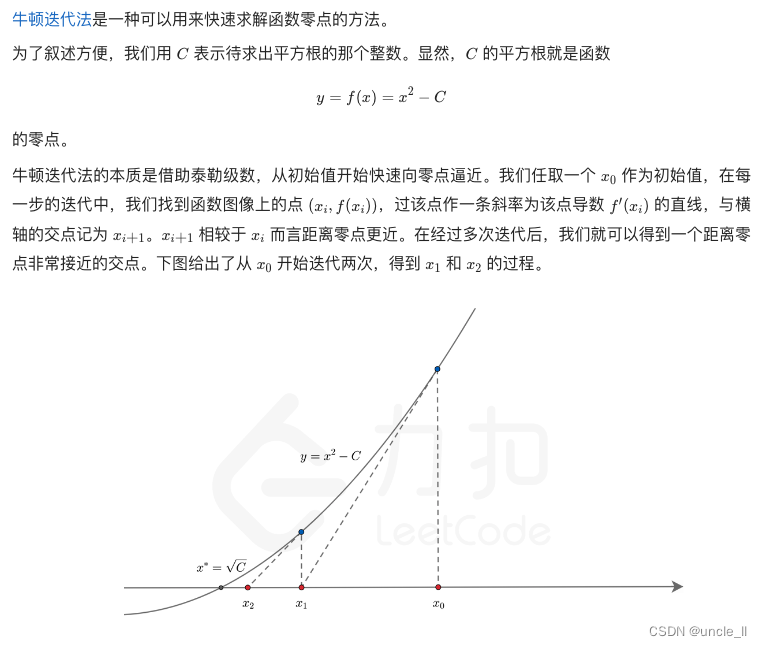
leetcode:69. x 的平方根
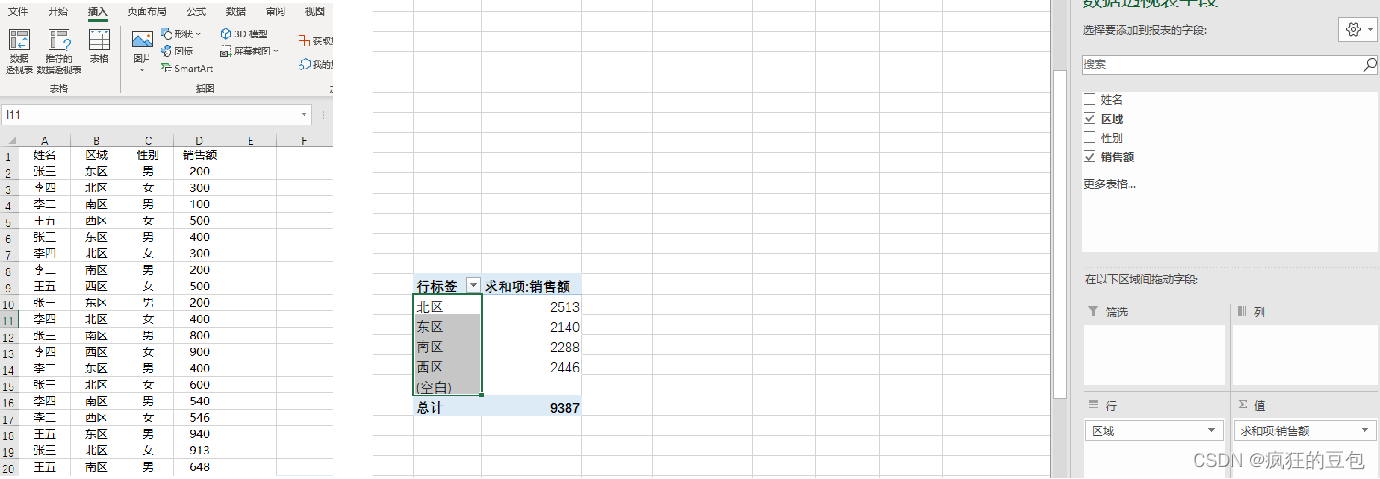
The most complete documentation on Excel's implementation of grouped summation
My creative anniversary丨Thank you for being with you for these 365 days, not forgetting the original intention, and each is wonderful
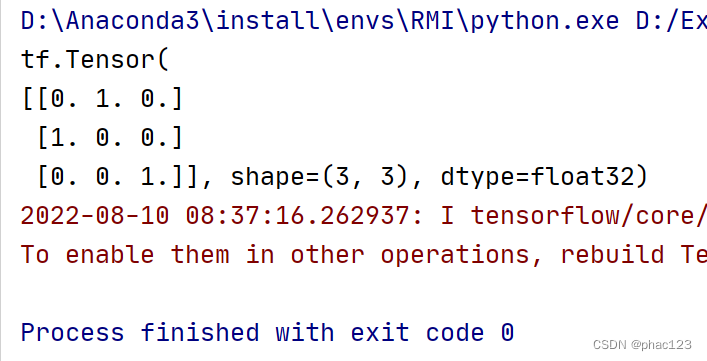
TF中的One-hot
1.1-Regression
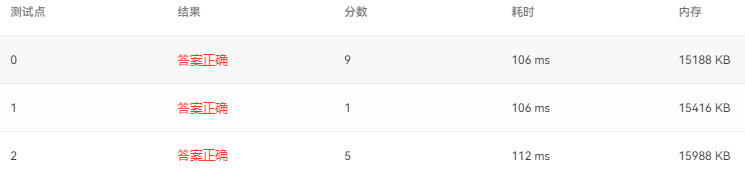
1106 2019 Sequence (15 points)
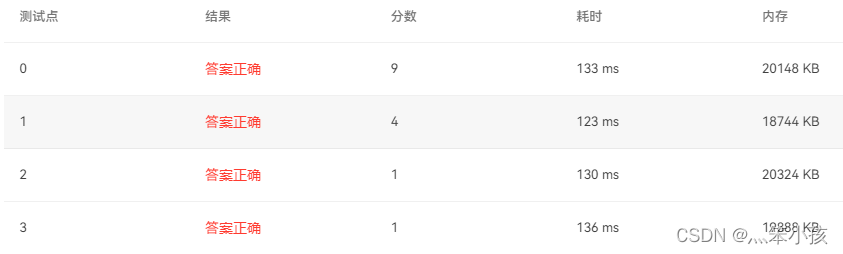
1051 Multiplication of Complex Numbers (15 points)
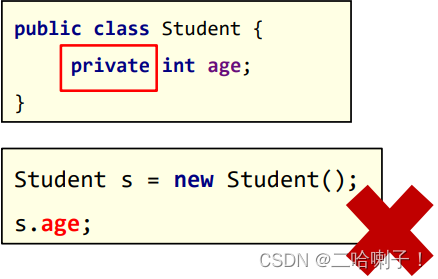
CSDN21天学习挑战赛——封装(06)

Hibernate 的 Session 缓存相关操作
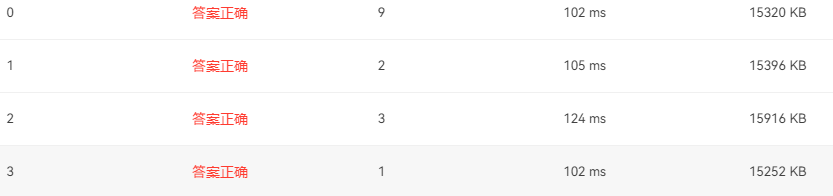
1096 大美数 (15 分)

随机推荐
迷你图书馆系统(对象+数组)
oracle数据库中列转行,列会有变化
Interaction of Pico neo3 in Unity
There may be fields that cannot be serialized in the abnormal object of cdc and sqlserver. Is there anyone who can understand it? Help me to answer
The growth path of a 40W test engineer with an annual salary, which stage are you in?
4.1-支持向量机
进阶-指针
AcWing 272. 最长公共上升子序列
[C语言] sscanf如何实现sscanf_s?
Tensorflow中使用tf.argmax返回张量沿指定维度最大值的索引
1101 How many times B is A (15 points)
1076 Wifi Password (15 points)
1003 I want to pass (20 points)
oracle19c does not support real-time synchronization parameters, do you guys have any good solutions?
关于Excel实现分组求和最全文档
1106 2019 Sequence (15 points)
Dynamic Agent Learning
Two startup methods and differences of Service
tf.cast(), reduce_min(), reduce_max()
欢迎加入sumarua网络安全交流社区