当前位置:网站首页>源码剖析Redis中如何使用跳表的
源码剖析Redis中如何使用跳表的
2022-04-23 05:10:00 【神技圈子】
前言
阿里云今年春招校招面试题,面试官问Redis在是如何使用跳表的?让很多同学赶到很头疼。今天我们就来讲一讲吧。
Sorted Set的结构
redis的数据类型中有序集合(sorted set)使用非常广泛,本身具有集合的功能,同时又可以支持集合带权重,并且按权重排序。它可以通过ZRANGEBYSCORE按照元素权重返回一个范围内的元素,或者通过ZSCORE返回某个元素的权重值。它能以常数复杂度返回元素的权重,相信很多童鞋都能想到是采用了哈希表索引。而能支持范围查询如何做到的呢?那就得说到今天的重点跳表了。而且大家再想一想,它们两个又是如何结合的呢?
先来看一看sorted set的结构
typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset;
从结构中,可以看到使用跳表的目的是为了高效支持范围查询(比如ZRANGBYSCORE操作),而高效单点查询则使用的是哈希结构(比如ZCORE)操作。接下来看下Redis的跳表是如何实现的。
跳表的设计与实现
跳表(skiplist)其实是一种多层有序链表。跳表从低到高排序,最低下一层level0,往上依次是level1,level2等。是在 O(log(n)) 时间内完成增加、删除、搜索操作的数据结构。它可以说是平衡树的一种替代结构,但是不同于红黑树的是,它对于平衡树的实现是基于一种随机化的算法的。
下面我们来看下zskiplist的实现
typedef struct zskiplistNode {
sds ele;
//权重
double score;
//后向指针
struct zskiplistNode *backward;
level数组
struct zskiplistLevel {
//前向指针
struct zskiplistNode *forward;
//跨度,记录跨越了level0上的几个结点
unsigned long span;
} level[];
} zskiplistNode;
由于sorted set即要保存数据,又要保存权重值。所以在zkiplistNode定义中看到sds 类型的变量 ele,以及 double 类型的变量 score。ele保存了元素,score保存了权值。此外,为了便于从跳表的尾结点往前进行查找,每个跳表结点还保存了指针backward,它指向前一个结点。
此外,刚才提到过跳表本身是一个多层有序链表,所以每一层都是多个结点通过指针连接起来。因此在结构中还包括了一个zskiplistLevel结构体类型的level数组。level数组中的每一个元素定义了一个前向指针(forward)和后续结点连接起来。跨度则是用来记录了在某一层上foward指针和该指针指向的结点之间跨越了level0上的几个结点。举个例子, 比如下面这张图

这个例子中结点30的level数组有三个元素,分别对应了三层level指针,此外,level2,level1,level0分别对应的跨度是3、2、1。而且,因为跳表中的结点都是按序排列的,所以可以根据各个结点在forward指针上的跨度做一个累加。这个累加值可以用来计算该结点在整个跳表中的顺序。
接下来,了解下跳表的定义,跳表结构中定义了跳表的头结点和尾结点,跳表的长度以及跳表的最大层数。定义如下:
typedef struct zskiplist {
//跳表的头结点和尾结点
struct zskiplistNode *header, *tail;
//最大长度
unsigned long length;
//最大层数
int level;
} zskiplist;
由于跳表中的每个结点都是用指针相连的,所以我们只需要获得链表的头结点和尾结点就可以通过结点指针查询跳表的各个结点了。
跳表的查询
那么,现在跳表已经定义好了,是不是还是像查询普通链表那样从头开始逐一查询吗?当然不用,可以用结点中的level数组加速查询。
当查询一个结点的时候,跳表会从头结点的最高层开始查找下一个结点,由于结点中保存了元素和权值,所以结点在进行比较的时候这两者都要比较。
1.当查找的结点权重比要查找的结点权重小,则会继续访问该层的下一个结点。
2.当查找的结点权重等于要查找的结点权重,那么继续比较它们的值,如果查找结点数据小于要查找的结点数据,跳表仍然会访问该层的下一个结点。
当这两个条件都不满足时,则会访问level数组的下一层指针,然后沿着下一层指针继续查找。相当于到下一层继续查找。具体代码如下:
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--) {
...
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
{
...
x = x->level[i].forward;
}
跳表中每一层结点数约是下一层的一半,这样的好处是查找过程类似于二分查找,时间复杂度从O(n)降低到O(logN),但是这种方法也会有负面问题,那就是一旦有结点要进行插入和删除。那么要插入和删除的结点以及其后面结点的层数都需要进行调整从而造成了额外的开销。
下面举个例子
假设当前跳表有4个结点,1、7、13、21.
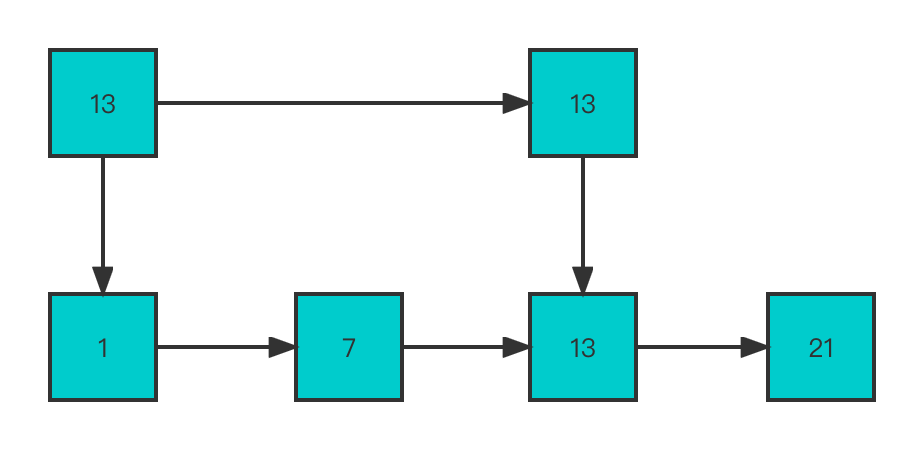
接着如果插入多个结点,如下图所示
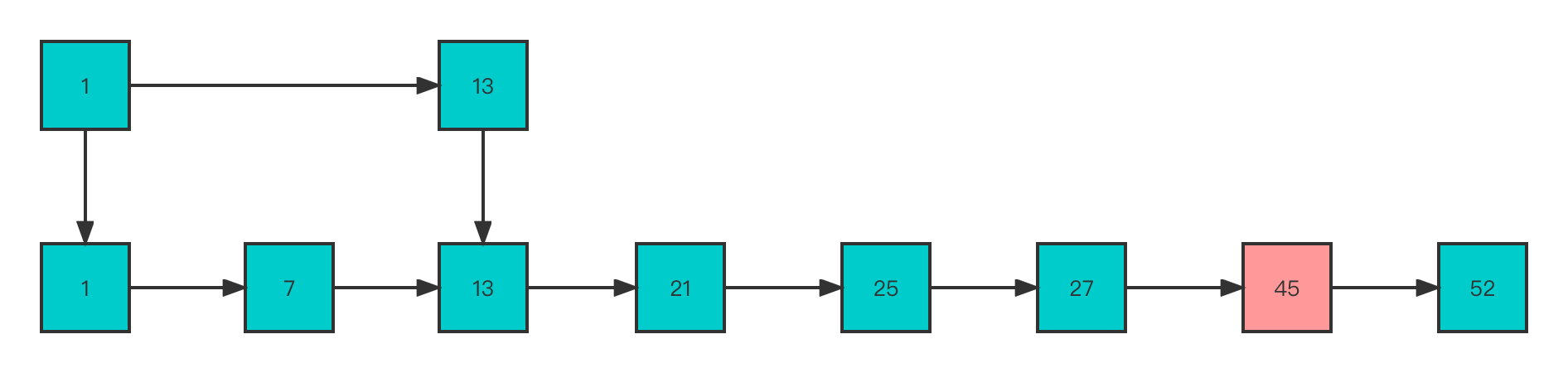
可以看到当插入多个结点后,如果是查找45这个结点则就需要在 level 0 的结点中依次顺序查找,复杂度又是 O(N) 了。现在为了维持相邻层结点数的关系修改为如下
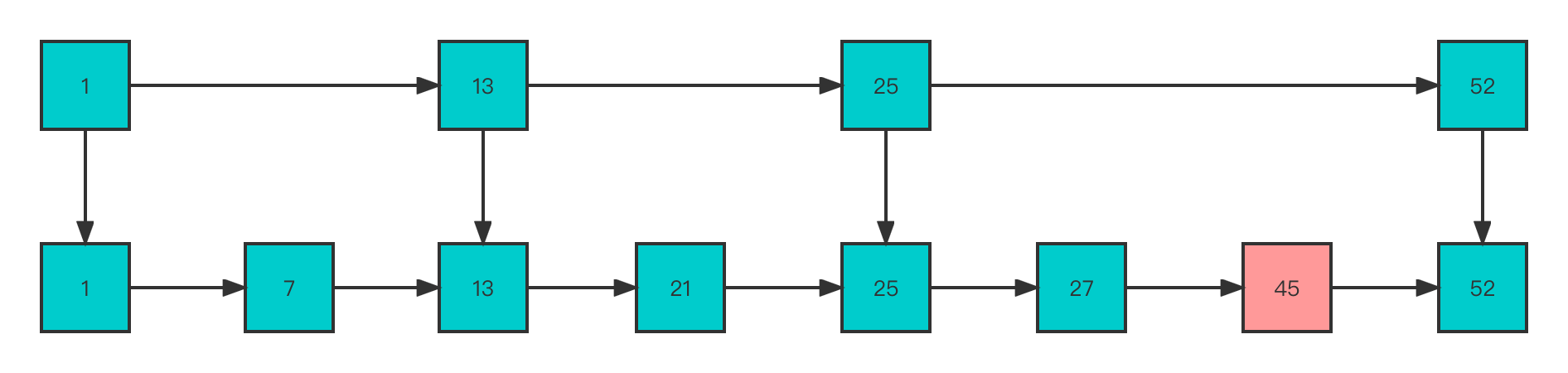
这样查找45的时间复杂度降低了,但是这样也带来了额外的开销。为了避免上述问题,跳表在创建结点的时候,采用了随机生成结点层数的方法。此时相邻层并不是严格按照2:1的方式,这样的话,当插入一个新结点时,只需修改前后结点的指针,而其它结点的层数就不需要随之改变了,这样就降低插入操作的复杂度。
在源码中,跳表结点层数是由 zslRandomLevel 函数来决定的。代码如下
int zslRandomLevel(void) {
static const int threshold = ZSKIPLIST_P*RAND_MAX;
int level = 1;
while (random() < threshold)
level += 1;
return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}
可以看到zslRandomLevel函数把层数初始化为1,这也是结点最小的层数。然后生成随机数,如果随机数小于ZSKIPLIST_P。ZSKIPLIST_P定义如下
#define ZSKIPLIST_P 0.25
它表示跳表增加层数的概率,那么层数增加1层。因为随机数取值在[0,0.25)范围内概率不会超过25%,所以这也说明了增加一层的概率不会超过25%。
# 总结
这篇文章介绍了 Sorted Set 数据类型的底层实现。Sorted Set 为了能同时支持按照权重的范围查询,以及针对元素权重的单点查询,以及针对元素权重的单点查询,在底层结构上设计了使用跳表和哈希表的组合方法。
跳表是一个多层的有序链表,在查询跳表的时候,是从最高层开始查询,层数越高节点数越少,如果高层直接查到了等于待查结点直接返回。如果查到第一个大于待查元素的结点则往下一层继续查询,然后在下一层更多结点中继续查询。跳表的这种设计方法节省了查询开销,同时,跳表采用随机的方法来确定每个结点的层数,这样就可以避免增加结点时,引起其它节点也要增加层数的连锁反应。
版权声明
本文为[神技圈子]所创,转载请带上原文链接,感谢
https://blog.csdn.net/songguangfan/article/details/124075100
边栏推荐
- Streamexecutionenvironment of Flink source code
- Kubectl command automatic replenishment
- How to exit VIM
- Cross border e-commerce | Facebook and instagram: which social media is more suitable for you?
- Introduction to load balancing
- JS engine loop mechanism: synchronous, asynchronous, event loop
- QPushButton slot function is triggered multiple times
- 【数据库】MySQL多表查询(一)
- MySQL uses or to query SQL, and SQL execution is very slow
- Basic concepts of multithreading (concurrency and parallelism, threads and processes) and entry cases
猜你喜欢

Restful toolkit of idea plug-in

MySQL external connection, internal connection, self connection, natural connection, cross connection
![[database] MySQL single table query](/img/27/99d174219109ea7a455cfdf55e0996.png)
[database] MySQL single table query
MySQL basics 3

Backup MySQL database with Navicat
MySQL memo (for your own query)
Details related to fingerprint payment

Sword finger offer: the median in the data stream (priority queue large top heap small top heap leetcode 295)
![[2021] Spatio-Temporal Graph Contrastive Learning](/img/7d/67a0bfa0adecee24bbe291a25ae906.png)
[2021] Spatio-Temporal Graph Contrastive Learning

Routing parameters
随机推荐
In aggregated query without group by, expression 1 of select list contains nonaggregated column
Unity C# 网络学习(四)
《2021多多阅读报告》发布,95后、00后图书消费潜力攀升
JS engine loop mechanism: synchronous, asynchronous, event loop
信息学奥赛一本通 1212:LETTERS | OpenJudge 2.5 156:LETTERS
2022/4/22
Acid of MySQL transaction
Differences between redis and MySQL
Installing kuberneters using kubedm
The 8 diagrams let you see the execution sequence of async / await and promise step by step
Discussion on flow restriction
Detailed explanation of concurrent topics
Chapter I overall project management of information system project manager summary
Various ways of writing timed tasks of small programs
[database] MySQL single table query
退出vim的方法
【数据库】MySQL基本操作(基操~)
【数据库】表的查看、修改和删除
Get the number of days between dates, get the Chinese date, get the date of the next Monday of the date, get the working day, get the rest day
[winui3] write an imitation Explorer file manager