当前位置:网站首页>目标检测——Faster-RCNN 之 RCNN
目标检测——Faster-RCNN 之 RCNN
2022-08-11 05:23:00 【壹万1w】
《Rich feature hierarchies for accurate oject detection and semantic segmentation》针对高准确度的目标检测与语义分割的多特征层级
——关于目标检测和特征分割的神将网络
作者:Ross Girshick,JeffDonahue,TrevorDarrell,Jitendra Malik
R-CNN目录
1.1意义
这篇论文发布时间是 2014 年,它具有很多比较重要的意义。
1. 在 Pascal VOC 2012 的数据集上,能够将目标检测的验证指标 mAP 提升到 53.3%,这相对于之前最好的结果提升了整整 30%.
2. 这篇论文证明了可以讲神经网络应用在自底向上的候选区域,这样就可以进行目标分类和目标定位。
3. 这篇论文也带来了一个观点,那就是当你缺乏大量的标注数据时,比较好的可行的手段是,进行神经网络的迁移学习,采用在其他大型数据集训练过后的神经网络,然后在小规模特定的数据集中进行 fine-tune 微调。
1.2 算法的步骤
RCNN算法流程可分为4个步骤
- 一张图像生成1K~2K个候选区域(使用Selective Search方法)
- 对每个候选区域,使用深度网络提取特征
- 特征送入每一类的SVM 分类器,判别是否属于该类
- 使用回归器精细修正候选框位置
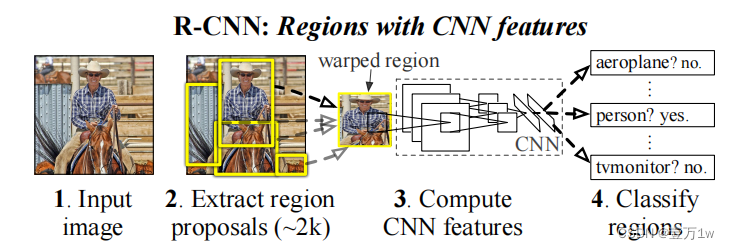
1.2.1 候选区域的生成
利用Selective Search算法通过图像 分割的方法得到一些原始区域,然后 使用一些合并策略将这些区域合并, 得到一个层次化的区域结构,而这些 结构就包含着可能需要的物体。
- 候选区域生成方法
能够生成候选区域的方法很多,比如:
objectness
selective search
category-independen object proposals
constrained parametric min-cuts(CPMC)
multi-scale combinatorial grouping
Ciresan
R-CNN 采用的是 Selective Search 算法。
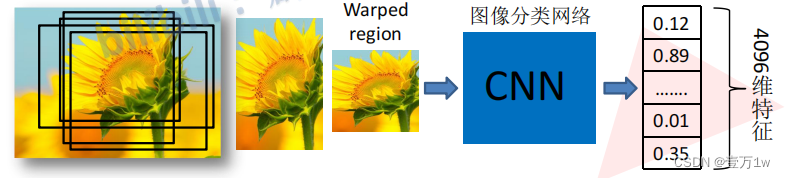
1.2.2 对每个候选区域,使用深度网络提取特征
1. 将2000候选区域缩放到 **227x227pixel**(在图像进入CNN之前,首先进行reset处理,不管是什么形状统一缩放成227*227大小)
2. 接着 将候选区域输入事先训练好的**AlexNet CNN网络** 得到对应的特征向量
3. 获取4096维的特征得到2000×4096维矩阵。(去掉了全连接层)
1.2.3 特征送入每一类的SVM分类器,判定类别
将2000×4096维特征与20个SVM组成的权值矩阵4096×20相乘
对于2000*20代表了2000个数据,20代表分类为猫、狗等等的概率
第一行就代表,第一个数据和这20类相对应的概率
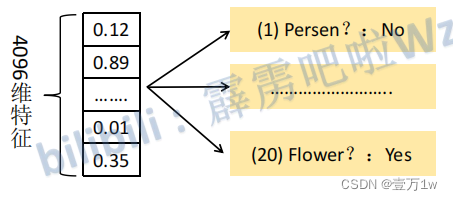
第一列就代表,这2000个数据,对应为“猫”的概率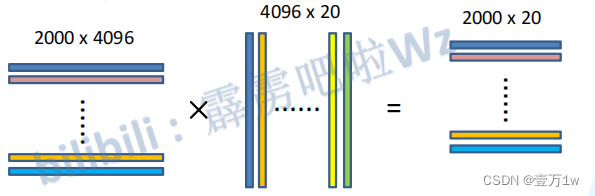
获得2000×20维的评分矩阵表示每个建议框是某个目标类别的得分。
分别 对上述2000×20维矩阵中每一列即每一类进行非极大值抑制剔除重叠建议框,得到该列即该类中得分最高的一些建议框。
- 注:SVM分类器是二分类的分类器
- 补充:非极大值抑制剔除重叠建议框(交并比)
IoU(Intersection over Union) 表示(A∩B)/(A∪B)
①对每个类别,先寻找评分最高的目标
②计算这个目标和其他目标的IOU
③删除IOU的值大于给定阈值的目标
然后对于最高的目标再重复执行这个①②③操作,我们想让他得到的是一个最完美最完整的边界框
1.2.4 使用回归器精细修正候选框位置
- 对NMS处理后剩余的建议框进一步筛选。
- 接着分别 用20个回归器 对上述20个类别中剩余的建议框进行回归操作
- 最终得到每个类别的修正后的得分最高的 bounding box(BBOX)
如图 黄色框口P:表示建议框Region Proposal
绿色窗口G:表示实际框Ground Truth
红色窗口G^:表示Region Proposal进行回归后的预测窗口
可以用 最小二乘法解决的线性回归问题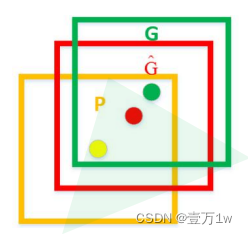
1.3 R-CNN框架

通过表格我们可以观察出,R-CNN由四部分组成
- Region proposal(Selective Search)先生成候选框
- CNN:生成的候选框放入CNN进行特征提取
- 提取来的特征经过SVM进行特征分类
- 把分好的特征,进行边框修正,得到最终完整的候选框
1.4 R-CNN存在的问题
1.测试速度慢: 测试一张图片约53s(CPU)。用Selective Search算法 提取候选框用时约2秒,一张图像内候选框之间存在大量重叠,提取特征操作冗余。
2.训练速度慢: 过程及其繁琐
3.训练所需空间大: 对于SVM和bbox回归训练,需要从每个图像中的每个目标候选框 提取特征,并写入磁盘。对于非常深的网络,如VGG16,从VOC07 训练集上的5k图像上提取的特征需要数百GB的存储空间。
边栏推荐
猜你喜欢



随机推荐
GBase 8a MPP Cluster产品高级特性
.Net6 MiNiApi +EFCore6.0高B格操作的WebApi
BGP联邦实验
四大组件之一BroadCast(其一)
梅科尔工作室-PR第三次培训笔记(效果与转场及插件使用)
Nodered系列—写入tDengine超级表,自动创建子表
微信小程序canvas画图,保存页面为海报
OSPF综合实验
AI智能图像识别的工作原理及行业应用
Redis主从复制的搭建
Realize data exchange between kernel and userspace through character device virtual file system (passed based on kernel 5.8 test)
Rethinking LiDAR Object Detection in adverse weather conditions
秦始皇到底叫嬴政还是赵政?
RIP综合实验
LiDAR Snowfall Simulation for Robust 3D Object Detection
mysql基本概念之事务
Fragment 和 CardView
>>数据管理:DAMA简介
GBase 8a语法格式
安全帽识别