当前位置:网站首页>CVPR2022——A VERSATILE MULTI-VIEW FRAMEWORK
CVPR2022——A VERSATILE MULTI-VIEW FRAMEWORK
2022-08-11 05:23:00 【zhSunw】
A VERSATILE MULTI-VIEW FRAMEWORK FOR LIDAR-BASED 3D OBJECT DETECTION WITH GUIDANCE FROM PANOPTIC SEGMENTATION
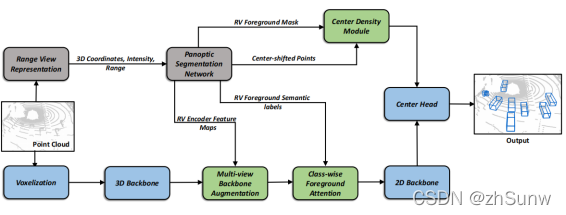
灰色表示CPSeg模块,蓝色表示CenterPoint模块
Contribution:
- 提出了一个多任务框架(全景分割+目标检测),全景分割改进目标检测。
- 框架可用于任何基于BEV的目标检测方法
- 大量实验与消融实验
Keyknowledge:
- Multi-View Backbone Augmentation
RV:特征表示密集,容易检测小物体。但是存在大小变化(近大远小)和遮挡。
BEV:不存在近大远小和遮挡的问题,容易检测密集的目标与确定边界。但稀疏性不利于检测小目标。
Cascade RV Feature Fusion Module:融合多级Range View特征
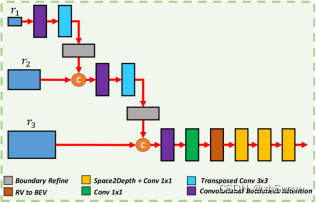
将全景分割提供的三个不同分辨率特征图从r1(最小分辨率)开始,先通过Convolutional Block Attention Module(CBAM)模块逐层对特征图进行注意力加权特征再经过反卷积上采样连接到更高分辨率的特征图直到最高分辨率的r3特征图。然后投影到BEV平面,经过Space2Depth + Conv 1x1降采样块压缩分辨率适应2D BackBone检测头。
Attention-based RV-BEV Feature Weighting Module:对RV-BEV两个特征图加权突出重要的特征值。
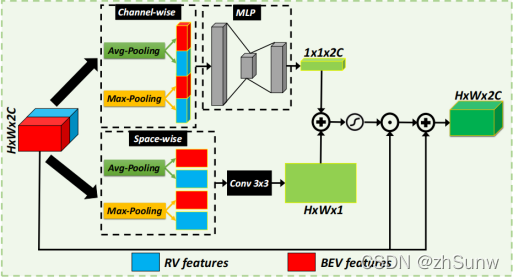
使用了修改的CBAM模块对RV、BEV两个特征图分别计算通道注意力特征图和空间注意力特征图,将两个特征图广播后相加再激活生成注意力图。用注意力图加权输入的RV-BEV特征,突出对检测任务有帮助的特征值。最后与输入特征相加得到注意力加权多视角的特征图。
基于注意力的特征加权图可视化:红色和蓝色的区域分别表示BEV和RV特征被认为具有更高权重的位置。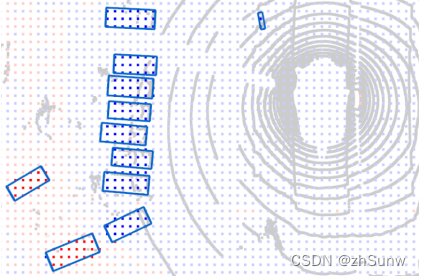
基于注意力的RV-BEV加权模块为代表附近和较小物体的RV特征分配了更高的权重,而对于被遮挡和远处的物体,更倾向于支持BEV特征。
Class-wise Foreground Attention Module:将前景语义信息嵌入到特征中
由于论文缺少模块图,且尚未开源
根据文字叙述按自己的理解画了模块图: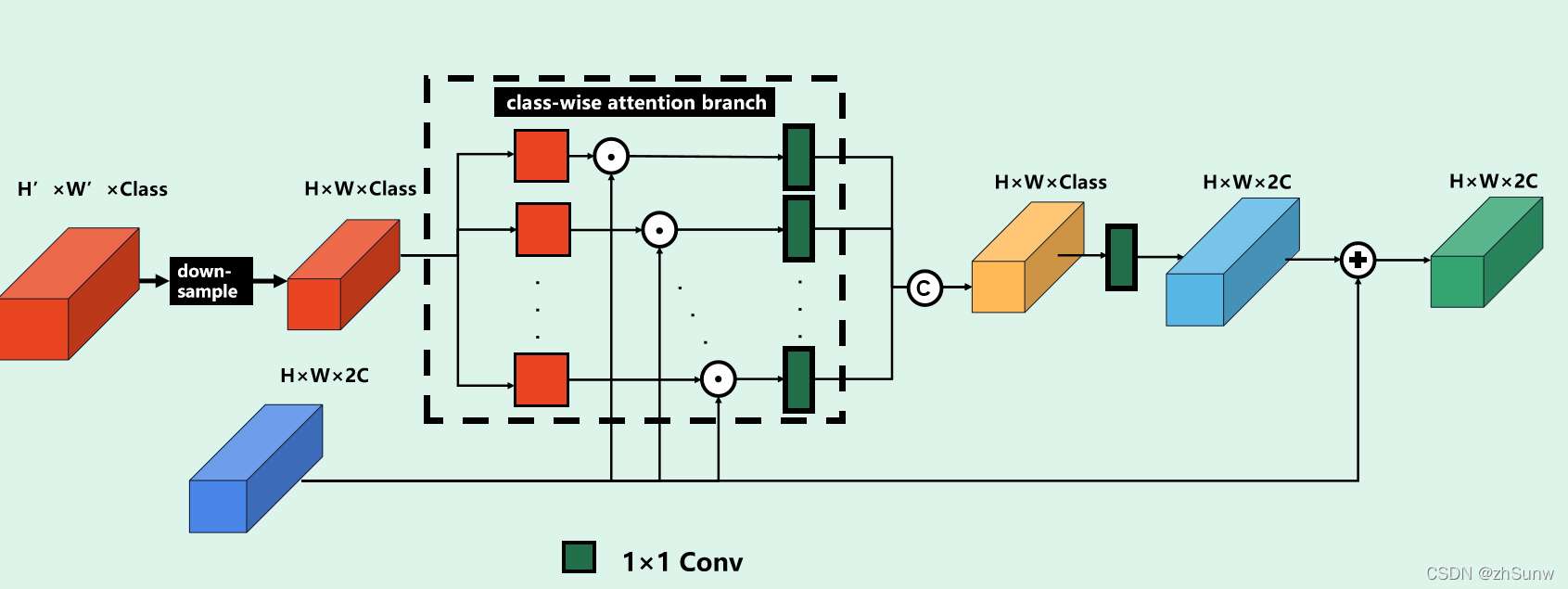
将全景分割提供的每个点的每个前景类概率(不考虑背景点)进行maxpooling下采样到与RV-BEV加权特征图相同分辨率。之后按类进行加权:每个类按概率按元素乘对特征图进行每一类的加权后1×1卷积压缩通道维度得到Class-wise Foreground Attention Map,最后再将每一类的加权图连接通过1×1卷积改变特征图形状与输入RV-BEV特征图相同,再将二者相加得到最终的加权特征图。
Center Density Heatmap Module:计算中心点密度
通过CPSeg估计的每个点的3D BBox中心偏移量绘制 Center Density Heatmap:
先利用前景掩码过去背景点,剩余点根据偏移预测进行偏移并投影到BEV平面上,再根据Heatmap函数创建Heatmap: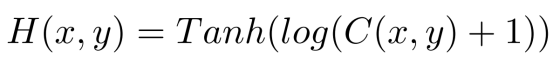
C(x,y)表示投影到该点的数量。
一个点被预测为中心点的次数越多值越大,颜色越深(绿色):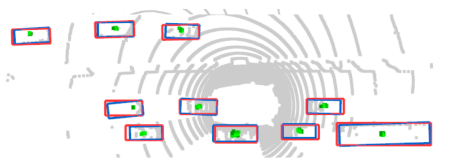
Experiments
Sota:
消融实验: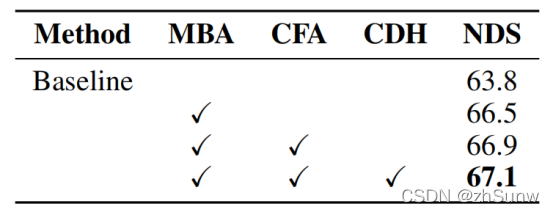
多任务框架的有效性: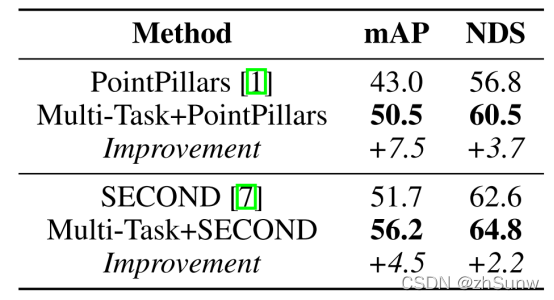
多任务的有效性(单任务预先训练CPSeg):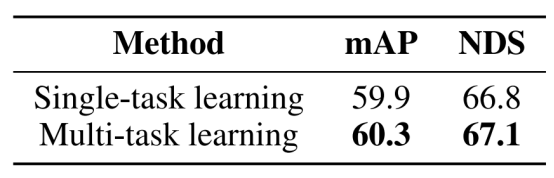
边栏推荐
猜你喜欢



随机推荐
xss.haozi靶场通关
Haproxy集群
Fragment 和 CardView
海内外媒体宣发,关键词优化
GBase数据库监控
ENS是机会吗?
DOM破坏
mysql基本概念之事务
代币标准--ERC721协议源码解析
Markdown学习
解读String的intern()
若依分离版—移动端开发通知公告功能
GBASE数据库迁移(Oracle到GBase 8s的数据类型映射)
Mysql导入UTF8编码数据库命令总结
云计算学习笔记——第二章 虚拟化与容器
【uniapp】跨端开发问题记录
代币标准--ERC1155协议源码解析
为什么购买的磁盘实际空间比标注的空间少
GBase 8s中IO读写方法
利用Redis的bitMap完成用户签到功能