当前位置:网站首页>prometheus学习5altermanager
prometheus学习5altermanager
2022-08-11 05:58:00 【daydayup9527】
安装alertmanager
download_url="https://github.com/prometheus/alertmanager/releases/download/v0.22.2/alertmanager-0.22.2.linux-amd64.tar.gz"
#wget ${download_url}
tar -xvf alertmanager-0.22.2.linux-amd64.tar.gz
mv alertmanager-0.22.2.linux-amd64 /usr/local/
ln -sv /usr/local/alertmanager-0.22.2.linux-amd64 /usr/local/alertmanager
cat <<EOF >/usr/lib/systemd/system/alertmanager.service
[Unit]
Description=alertmanager
Documentation=https://prometheus.io/
After=network-online.target
[Service]
Type=simple
User=root
Group=root
ExecStart=/usr/local/alertmanager/alertmanager \
--config.file=/usr/local/alertmanager/alertmanager.yml \
--storage.path=/usr/local/alertmanager/data/ \
--data.retention=120h \
--web.external-url=http://192.168.1.12:9093
--web.listen-address=:9093
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF
systemctl daemon-reload
systemctl start alertmanager
- 访问alertmanager主页
http://192.168.1.12:9093/#/alerts
配置发邮件
- 安装mail命令(也可以配置:钉钉、企业微信…)
[[email protected] ~]# yum install -y mailx # 安装
[[email protected] ~]# mail -V # 查看版本
- 邮件日志
tail -f /var/spool/mail/root
- 修改配置文件
[[email protected] ~]# vim /etc/mail.rc
...
set [email protected]
set smtp=smtp.qq.com
set [email protected]
set smtp-auth-password=dfsdsadtvjuia #参考https://www.58pxe.com/7980.html获取
set smtp-auth=login
set ssl-verify=ignore
- 测试邮件发送
echo 'test' | mail -s 'test mail' [email protected]

prometheus接入alertmanager
配置alertmanager服务器
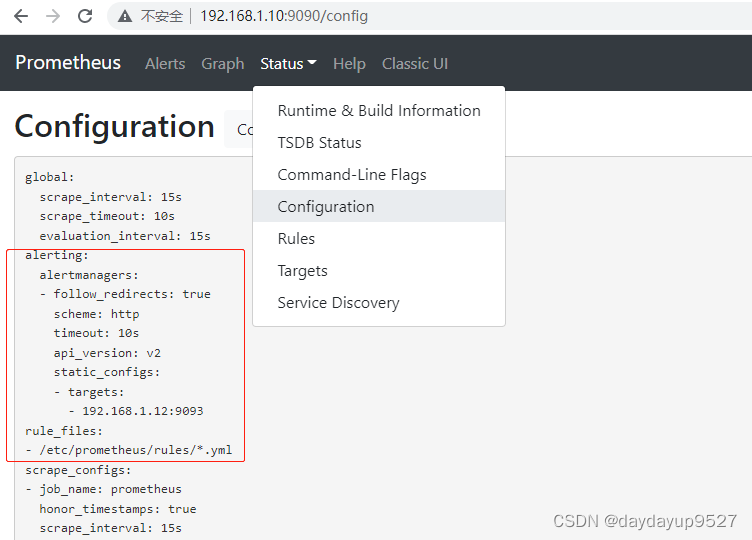
[[email protected] ~]# vim +8 /usr/local/prometheus/prometheus.yml
...
alerting:
alertmanagers:
- static_configs:
- targets:
- 192.168.1.12:9093
# 配置规则文件
rule_files:
- "/etc/prometheus/rules/*.yml"
配置报警规则
- /etc/prometheus/rules/rules.yml
[[email protected] ~]# mkdir -p /etc/prometheus/rules
[[email protected] ~]# cat /etc/prometheus/rules/rules.yml
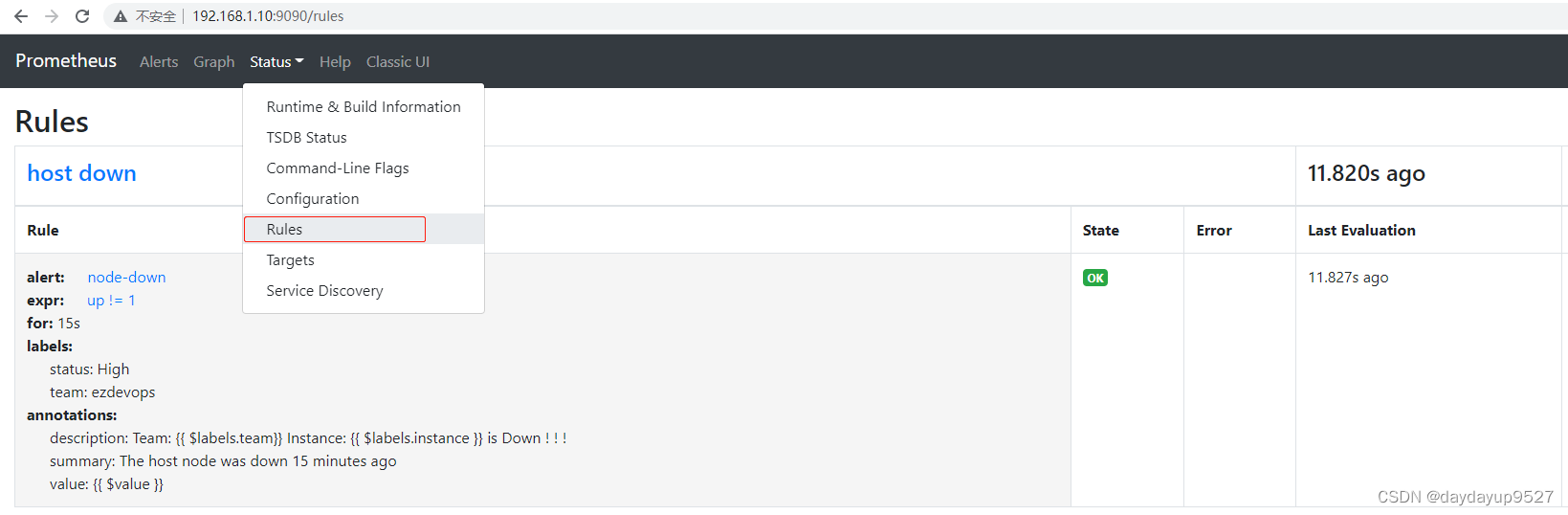
groups:
- name: host down
rules:
- alert: node-down
expr: up{
} < 2 #这里的公式现在prometheus里查好,设置2是为了较快实现报警
for: 15s
labels:
status: High
team: ezdevops
annotations:
description: "Team: {
{ $labels.team}} Instance: {
{ $labels.instance }} is Down ! ! !"
value: '{
{ $value }}'
summary: "The host node was down 15 minutes ago"
报警配置
- /usr/local/alertmanager/alertmanager.yml
global:
smtp_smarthost: smtp.qq.com:465 #163邮箱的应该是25,不一样
smtp_from: [email protected]
smtp_auth_username: [email protected]
smtp_auth_password: gkjfhfgjjjwylbgah
smtp_require_tls: false
resolve_timeout: 300s # 在此时间内未收到alert信息就默认为该报警解除
route:
# 报警时间相关配置
group_wait: 20s # 收到报警后会根据分组等待group_wait时间,这时间内的同组的报警将一起发出
group_interval: 5m # 同一个分组下之前已经发送成功过,进入新的alert时等待group_interval
repeat_interval: 120s # alert group报警发送成功且没有变化则等待repeat_interval后发送报警
# 分组及路由
group_by: [alertname] # 报警分组
receiver: default-receiver
#routes:
# - match:
# team: ezdevops
# group_by: ['instance']
# receiver: 'ops'
receivers:
- name: 'default-receiver'
email_configs:
- to: [email protected]
send_resolved: true
[[email protected] ~]# systemctl restart alertmanager.service
[[email protected] ~]# systemctl restart prometheus.service
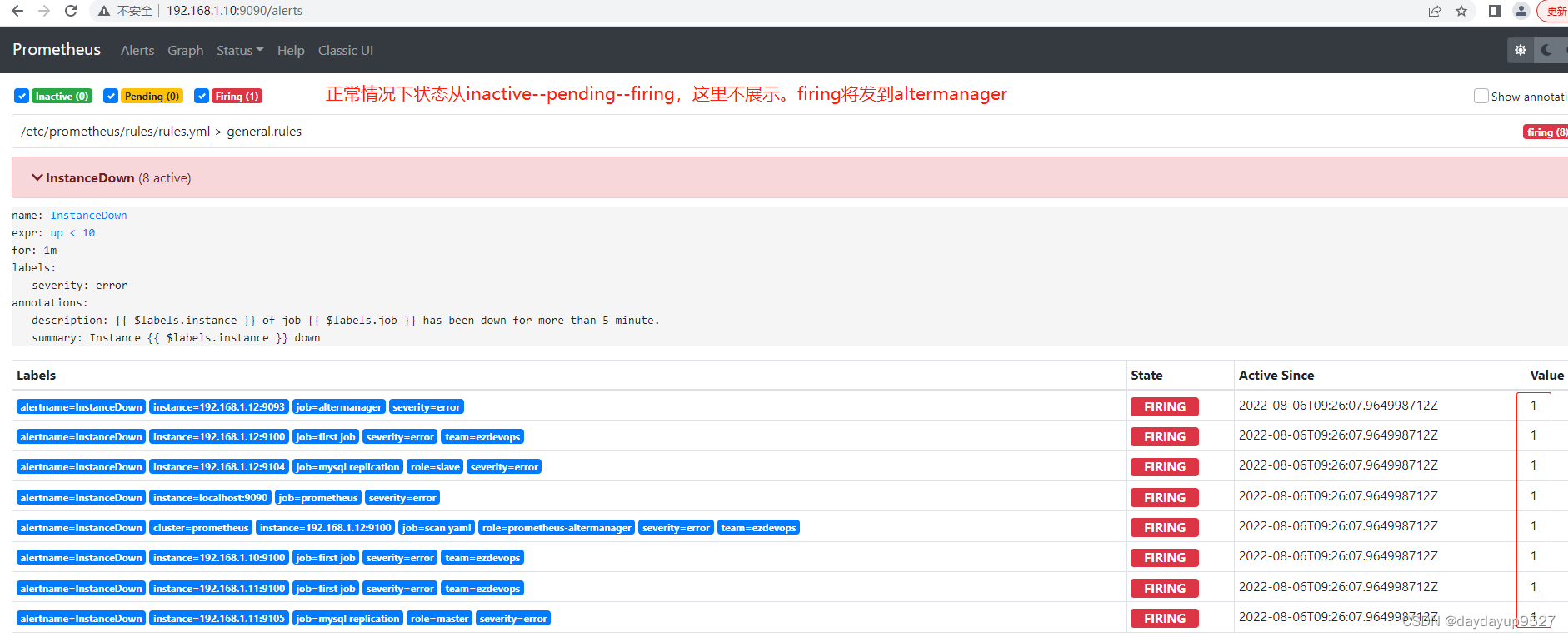
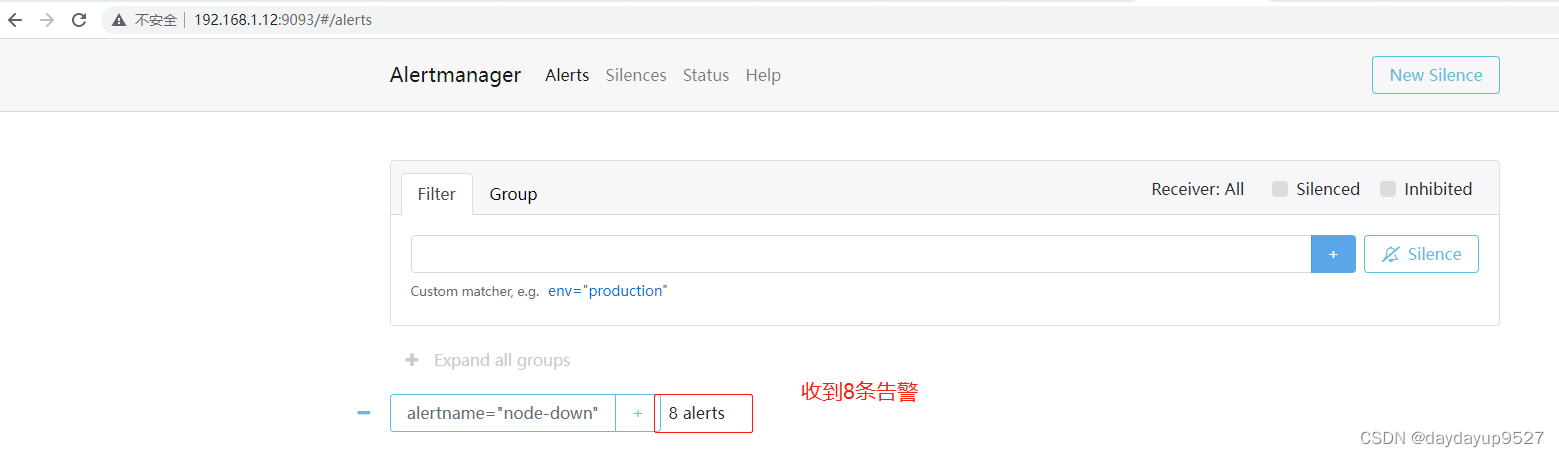

报警时间说明
涉及时间的配置文件
- Prometheus下配置prometheus.yml
global:
scrape_interval: 15s # 数据采集间隔
evaluation_interval: 15s # 评估告警周期
scrape_timeout: 30s # 数据采集超时时间默认10s
- alertmanager中配置/usr/local/alertmanager/alertmanager.yml
route:
group_wait: 10s # 一个新分组等待发送报警的时间
group_interval: 10s # 已经发送成功了报警的组,有新增alert加入组时下一次发送报警的时间
repeat_interval: 1m # 报警无变化情况下,重复发送告警时间。默认1h
resolve_timeout: 5m # 该时间内未收到报警则视为问题解决
- 规则中配置持续时间 /etc/prometheus/rules/rules.yml
groups:
- name: host down
rules:
- alert: node-down
expr: up{
} != 1
for: 15s # 报警持续时间
报警生命周期
inactive: evaluation_interval: 15s # 评估告警周期
pending: for: 15s # 报警持续时间
firing: #推送报警
分组
是 Alertmanager 把同类型的警报进行分组,合并多条警报到一个通知中。可以把这些被触发的警报合并为一个警报进行通知,从而避免瞬间突发性的接受大量警报通知。
- alertmanager.yml
# 默认使用job名称分组
# 默认接受者ops
# 接受到报警后如果匹配的instance是指定内容时发送到dba组
route:
group_wait: 20s
group_interval: 60s
repeat_interval: 120s
group_by: ['first job']
receiver: ops
routes:
- match:
instance: "192.168.1.11:9100"
receiver: 'first'
#- match_re:
# team: ops|dba
# group_by: [env]
# receiver: 'ops'
- name: 'first'
email_configs:
- to: [email protected]@qq.comn
send_resolved: true
抑制
当某条警报已经发送,停止重复发送由此警报引发的其他异常或故障的警报机制。例如网络交换机断开,则该交换机下的主机down机事件就无需上报。
抑制需求
- 有DB和WEB的节点
- DB节点不可用的情况下,WEB节点就不报警
- DB抑制WEB
prometheus配置
- 配置节点信息,/etc/prometheus/nodes/alertmanager.yml
# web cluster
- targets:
- 192.168.0.52:9100
labels:
cluster: web cluster
role: db
- targets:
- 192.168.0.53:9100
labels:
cluster: web cluster
role: web
- 配置规则
/etc/prometheus/rules/rules.yml
- name: db down
rules:
- alert: db-down
expr: up{
instance="192.168.1.11:9100"} != 1
for: 15s
labels:
status: down
- name: web down
rules:
- alert: web-down
expr: up{
instance="192.168.1.12:9100"} != 1
for: 15s
labels:
http: error
alertmanager配置
- 抑制规则,
/usr/local/alertmanager/alertmanager.yml
inhibit_rules:
- source_match:
status: 'down' # 匹配到标签名称status的值为down
target_match:
http: 'error' # 匹配到标签名称http的值为error
equal: ['cluster'] # 匹配到的记录如果标签cluster的值是相等的,那么就抑制
抑制结果:正常一条报警
规则参考
https://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_liunx_65_prometheus_alertmanager_rule.html
边栏推荐
- 每日sql-找到每个学校gpa最低的同学(开窗)
- 图的拉普拉斯矩阵
- 亚马逊获得AMAZON商品详情 API 返回值说明
- 技术分享 | 实战演练接口自动化如何处理 Form 请求?
- Taobao API interface reference
- 每日sql--统计员工近三个月的总薪水(不包括最新一个月)
- 博途PLC 1200/1500PLC ModbusTcp通信梯形图优化汇总(多服务器多从站轮询)
- Spatial Pyramid Pooling -Spatial Pyramid Pooling (including source code)
- MySQL使用GROUP BY 分组查询时,SELECT 查询字段包含非分组字段
- Redis测试
猜你喜欢
矩阵分析——微分、积分、极限
自定义MVC增删改查
Pinduoduo API interface (attach my available API)
每日sql-员工奖金过滤和回答率排序第一
Concurrent programming in eight-part essay

快速了解集成学习
Pinduoduo api interface application example
1688商品详情接口
Get Pinduoduo product information operation details

Daily sql-statistics of the number of professionals (including the number of professionals is 0)
随机推荐
MySQL之CRUD
JVM学习——3——数据一致性
JD.com product details API call example explanation
NTT的Another Me技术助力创造歌舞伎演员中村狮童的数字孪生体,将在 “Cho Kabuki 2022 Powered by NTT”舞台剧中首次亮相
亚马逊获得AMAZON商品详情 API 返回值说明
【推荐系统】:协同过滤和基于内容过滤概述
Shell:三剑客之awk
Resolved EROR 1064 (42000): You have an error in. your SOL syntax. check the manual that corresponds to yo
PIXHAWK飞控使用RTK
A used in the study of EEG ultra scanning analysis process
mmdetection的安装和训练、测试didi数据集的步骤(含结果)
Implement general-purpose, high-performance sorting and quicksort optimizations
获取拼多多商品信息操作详情
亚马逊API接口大全
Trill keyword search goods - API
技能在赛题解析:交换机防环路设置
Douyin get douyin share password url API return value description
拼多多API接口大全
Waldom Electronics宣布成立顾问委员会
Especially the redis