当前位置:网站首页>[AI vision · quick review of today's sound acoustic papers, issue 2] Fri, 15 APR 2022
[AI vision · quick review of today's sound acoustic papers, issue 2] Fri, 15 APR 2022
2022-04-23 04:01:00 【hitrjj】
AI View · Today, CS.Sound An overview of acoustic papers
Fri, 15 Apr 2022
Totally 6 papers
Quick view of last issue For more highlights, please move to the home page

Daily Sound Papers
| Learning and controlling the source-filter representation of speech with a variational autoencoder Authors Samir Sadok, Simon Leglaive, Laurent Girin, Xavier Alameda Pineda, Renaud S guier Understanding and controlling the potential representation in the depth generation model is important for analysis 、 Transforming and generating various types of data is a challenging but important problem . In speech processing , Inspired by the anatomical mechanism of phonation , The source filter model considers that the speech signal is composed of several independent components 、 Physically meaningful continuous potential factors , Fundamental frequency f 0 And formants are the most important . In this work , We show that the source filter model of speech generation naturally appears in the variational automatic encoder VAE In the potential space of , The VAE Unsupervised training on natural speech signal data set . Only a few seconds of marked speech signal generated by artificial speech synthesizer , We show through experiments that f 0 And formant frequency at VAE Coding in the orthogonal subspace of potential space , And we developed a weak supervision method to accurately and independently control the changing factors in the potential subspace of speech learning . |
| Streamable Neural Audio Synthesis With Non-Causal Convolutions Authors Antoine Caillon, Philippe Esling Deep learning model is mainly used for off-line reasoning . However , This greatly limits the use of these models in audio generation settings , Because most creative workflows are based on real-time digital signal processing . Although the method based on cyclic network can naturally adapt to this buffer based calculation , But the use of convolution still poses some serious challenges . To solve this problem , The use of causal stream convolution has been proposed . |
| From Environmental Sound Representation to Robustness of 2D CNN Models Against Adversarial Attacks Authors Mohammad Esmaeilpour, Patrick Cardinal, Alessandro Lameiras Koerich This paper studies the effect of different standard ambient sound representation spectra on victim residual convolution neural network ( namely ResNet 18) The impact of recognition performance and robustness against attacks . The main motivation for us to focus on this front-end classifier rather than other complex architectures is to balance the recognition accuracy and the total number of training parameters . ad locum , We measured the impact of the different settings needed to generate more information Mel Frequency cepstrum coefficient MFCC、 The short-time Fourier transform STFT And discrete wavelet transform DWT Represent the impact on our front-end model . This measurement involves comparing classification performance with antagonism and robustness . We balance the average budget allocated by the attacker with the attack cost , For six benchmark attack algorithms, the inverse relationship between recognition accuracy and model robustness is proved . Besides , Our experimental results show that , Although in DWT Trained on the spectrum ResNet 18 The model achieves high recognition accuracy , But attacking this model is better for opponents than others 2D Indicates a relatively higher cost . |
| Predicting score distribution to improve non-intrusive speech quality estimation Authors Abu Zaher Md Faridee, Hannes Gamper Depth noise suppressor DNS Has become an attractive solution , It can eliminate the background noise in speech 、 Reverberation and distortion , And widely used in telephone voice applications . They are sometimes prone to introduce artifacts and reduce the perceived quality of speech . Use multiple human judges to get an average opinion score MOS Subjective listening test is a popular way to measure the performance of these models . Non intrusive neural network based on deep neural network MOS Estimation models have recently become a popular cost-effective alternative to these tests . These models use only MOS Tag for training , The secondary statistics of opinion scores are usually discarded . In this paper , We studied several methods to integrate the distribution of opinion scores , For example, variance , Histogram information , In order to improve the MOS Estimate performance . Our model passes 320 Different DNS Models and model variants are in 419K Training on the corpus of denoised samples , And from DNSMOS Of 18K Evaluation on test samples . |
| RadioSES: mmWave-Based Audioradio Speech Enhancement and Separation System Authors Muhammed Zahid Ozturk, Chenshu Wu, Beibei Wang, Min Wu, K. J. Ray Liu Speech enhancement and separation has always been a long-standing problem , Especially in the latest development of using a single microphone . Although the microphone performs well in restricted environments , But their speech separation performance will decline under noisy conditions . In this work , We proposed RadioSES, This is an audio speech enhancement and separation system , It overcomes the inherent problems in pure audio systems . By fusing complementary radio modes ,RadioSES You can estimate the number of speakers , Solve the problem of source Association , Separate and enhance noisy mixed speech , And improve intelligibility and perceptual quality . We perform millimeter wave sensing to detect and locate the speaker , And introduce a audioradio Deep learning framework to fuse individual radio features with mixed audio features . A large number of experiments using commercial off the shelf equipment show that ,RadioSES Superior to various state-of-the-art baselines , It has consistent performance gain in different environmental settings . |
| Lombard Effect for Bilingual Speakers in Cantonese and English: importance of spectro-temporal features Authors Maximilian Karl Scharf, Sabine Hochmuth, Lena L.N. Wong, Birger Kollmeier, Anna Warzybok In order to better understand the mechanism of speech perception and the contribution of different signal features , The computational model of speech recognition has a long tradition in listening research . Due to the need to recognize speech, there are many situations , Therefore, these models need to be under many acoustic conditions 、 Common to speakers and languages . This contribution tests the prediction of Mandarin and Lombardy speech recognition compared with Cantonese in fixed and modulated noise , The importance of different features in English speech recognition and prediction . Although Cantonese is a tonal language , It encodes information in the time characteristics of the spectrum , But as we all know , Lombardy effect is related to the change of spectrum in speech signal . These contrastive properties of tone language and Lombardy effect constitute an interesting basis for evaluating speech recognition models . ad locum , Use empirical data to evaluate the performance of automatic speech recognition based on spectrum or spectrum time characteristics ASR Model . It turns out that , Spectral temporal features are important for predicting speaker specific speech recognition thresholds for Cantonese and English SRT 50 And explain the improvement of speech recognition in modulation noise , and Lombard The influence of voice can be |
| Chinese Abs From Machine Translation |
For more highlights, please move to the home page
版权声明
本文为[hitrjj]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204220600582644.html
边栏推荐
- STM32单片机ADC规则组多通道转换-DMA模式
- 【测绘程序设计】坐标反算神器V1.0(附C/C#/VB源程序)
- Cause analysis of incorrect time of AI traffic statistics of Dahua Equipment Development Bank
- Does China Mobile earn 285 million a day? In fact, 5g is difficult to bring more profits, so where is the money?
- 一个函数秒杀2Sum 3Sum 4Sum问题
- The latest price trend chart and trading points of London Silver
- [AI vision · quick review of NLP natural language processing papers today, issue 29] Mon, 14 Feb 2022
- Man's life
- [AI vision · quick review of robot papers today, issue 29] Mon, 14 Feb 2022
- Xiaomi, qui a établi le plus grand volume de ventes de téléphones portables domestiques sur le marché d'outre - mer, se concentre de nouveau sur le marché intérieur
猜你喜欢

将编译安装的mysql加入PATH环境变量
![[latex] formula group](/img/34/ba927517d902a505077388d9b875d1.png)
[latex] formula group

A sword is a sword. There is no difference between a wooden sword and a copper sword
![[echart] démarrer avec echart](/img/40/e057f4ac07754fe6f3500f3dc72293.jpg)
[echart] démarrer avec echart

Cortex-M3寄存器组、汇编语言与C语言的接口介绍

小红书被曝整体裁员20%,大厂之间内卷也很严重
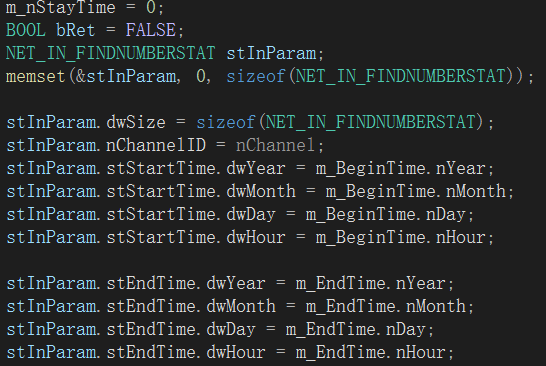
使用大华设备开发行AI人流量统计出现时间不正确的原因分析

AI CC 2019 installation tutorial under win10 (super detailed - small white version)
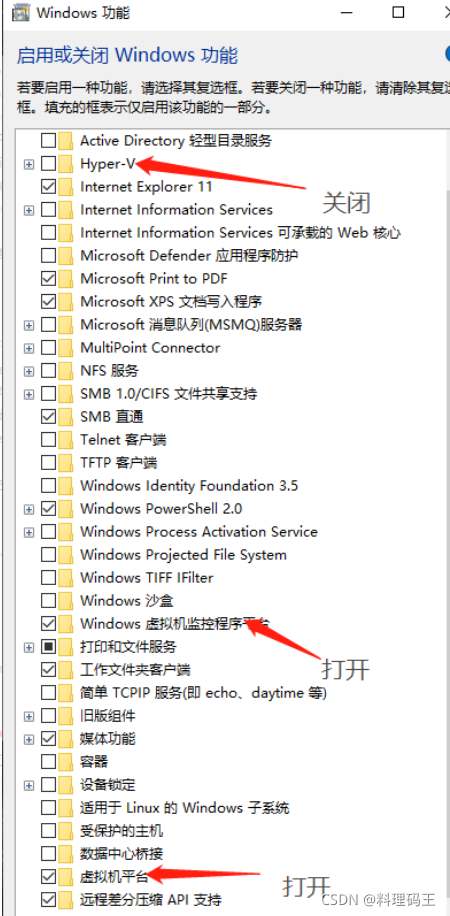
Win10 boot VMware virtual machine boot seconds blue screen problem perfect solution
Xiaohongshu was exposed to layoffs of 20% as a whole, and the internal volume among large factories was also very serious
随机推荐
[AI vision · quick review of NLP natural language processing papers today, issue 30] Thu, 14 APR 2022
[BIM introduction practice] wall hierarchy and FAQ in Revit
Paddlepaddle model to onnx
Difference between LabVIEW small end sequence and large end sequence
基于PHP的代步工具购物商城
硬核拆芯片
ROS series (IV): ROS communication mechanism series (6): parameter server operation
【测绘程序设计】坐标反算神器V1.0(附C/C#/VB源程序)
Now is the best time to empower industrial visual inspection with AI
Nel ASA:挪威Herøya设施正式启用
Operating skills of spot gold_ Wave estimation curve
减治思想——二分查找详细总结
The difference between lists, tuples, dictionaries and collections
【NeurIPS 2019】Self-Supervised Deep Learning on Point Clouds by Reconstructing Space
[echart] Introduction to echart
什么是软件验收测试,第三方软件检测机构进行验收测试有什么好处?
Digital image processing third edition Gonzalez notes Chapter 2
The latest price trend chart and trading points of London Silver
Express middleware ② (classification of Middleware)
Set classic topics