当前位置:网站首页>Index: teach you index from zero basis to proficient use
Index: teach you index from zero basis to proficient use
2022-04-23 17:36:00 【Crisp_ LF】
List of articles
- Indexes :( Teach you from zero foundation to proficient use )
-
- introduction :
- 1. ** Index Overview **
- 2. Index structure
- 3. Index classification
- 4. Index Syntax
- 5.SQL Performance analysis
- 6.** Index usage **
- 7.** Index design principles **
Indexes :( Teach you from zero foundation to proficient use )
introduction :
Recently in to see mysql How it works when this book , I found that my foundation is still relatively thin and soft , So after reading the index in a muddle, I began to look for videos for further study mysql, Index is an important part of database , So I spent a long time here , But learning is a continuous process , Maybe I just finished learning the index these days , Remember clearly , But it must be forgotten after infrequent use , So write down this blog , One is to deepen your memory of the index , It's convenient for you to review and consolidate later .
This blog is mainly for my video viewing notes , Add your own integration .
The video link is :https://www.bilibili.com/video/BV1Kr4y1i7ru?p=104
Reading documents is the fastest way to learn , If you encounter something you won't in the process of learning , You can watch this video , The chapters of the video correspond to this blog one by one .
1. Index Overview
1.1 Introduce
Indexes (index) Help MySQL Data structure for efficient data acquisition ( Orderly ). Out of data , The database system also maintains a data structure that satisfies a specific search algorithm , These data structures are referenced in some way ( Point to ) data , In this way, advanced search algorithms can be implemented on these data structures , This data structure is the index .

When it comes to data structures , Everyone will be worried , Worry that you can't understand , Can't keep up with the rhythm . But you don't have to worry about , This article will explain the index in detail , So that Xiaobai can quickly master the index .
1.2 demonstration
The table structure and its data are as follows :

-
If we want to implement SQL Statement for : select * from user where age = 45;
1. No index case

- Without index , You need to scan from the first line , Scan until the last line , We call it Full table scan , Very low performance .
2. When there is an index
-
If we index this table , Suppose the index structure is a binary tree , So it means , Would be right age This field establishes a binary tree index structure .[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-FHBGhvM3-1650629270338)(/Users/apple/Library/Application Support/typora-user-images/image-20220420100018075.png)]
-
At this point, when we query , It only takes three scans to find the data , Greatly improve the efficiency of query .
remarks : Here we just assume that the structure of the index is a binary tree , Introduce the general principle of index , It's just a sketch , Not the real structure of the index , The real structure of the index , More on that later .
1.3 characteristic
-
advantage :
-
Improve the efficiency of data retrieval , Reduce the IO cost
-
Sort data through index columns , Reduce the cost of sorting data , Reduce CPU Consumption of .
-
-
Inferiority
- Index columns also take up space .
- Indexing greatly improves query efficiency , At the same time, it also reduces the speed of updating tables , Such as on the table INSERT、UPDATE、DELETE when , Low efficiency .
2. Index structure
2.1 summary
- MySQL The index of is implemented in the storage engine layer , Different storage engines have different index structures , It mainly includes the following :
-
Index structure :
-
B+Tree Indexes : The most common type of index , Most engines support B+ Tree index
-
Hash Indexes : The underlying data structure is realized by hash table , Only the exact index matches the columns , No
Support range query
-
R-tree( Spatial index ): The spatial index is MyISAM A special index type of the engine , Mainly used for geospatial data types , Usually used less
-
Full-text( Full-text index ): It's a way of building inverted indexes , How to quickly match documents . similar Lucene,Solr,ES
-
-
The above is MySQL All index structures supported in , Next , Let's take a look at the support of different storage engines for index structure .
- B+tree Indexes : InnoDB : Support MyISAM : Support Memory: Support
- Hash Indexes : InnoDB : I won't support it MyISAM : I won't support it Memory: Support
- R-tree Indexes : InnoDB : I won't support it MyISAM : Support Memory: I won't support it
- Full-text Indexes :InnoDB :5.6 Support for MyISAM : Support Memory: I won't support it
Be careful : What we usually call index , If not specified , All refer to B+ Index of tree structure organization .
2.2 Binary tree
- If say MySQL The index structure of adopts the data structure of binary tree , The ideal structure is as follows :
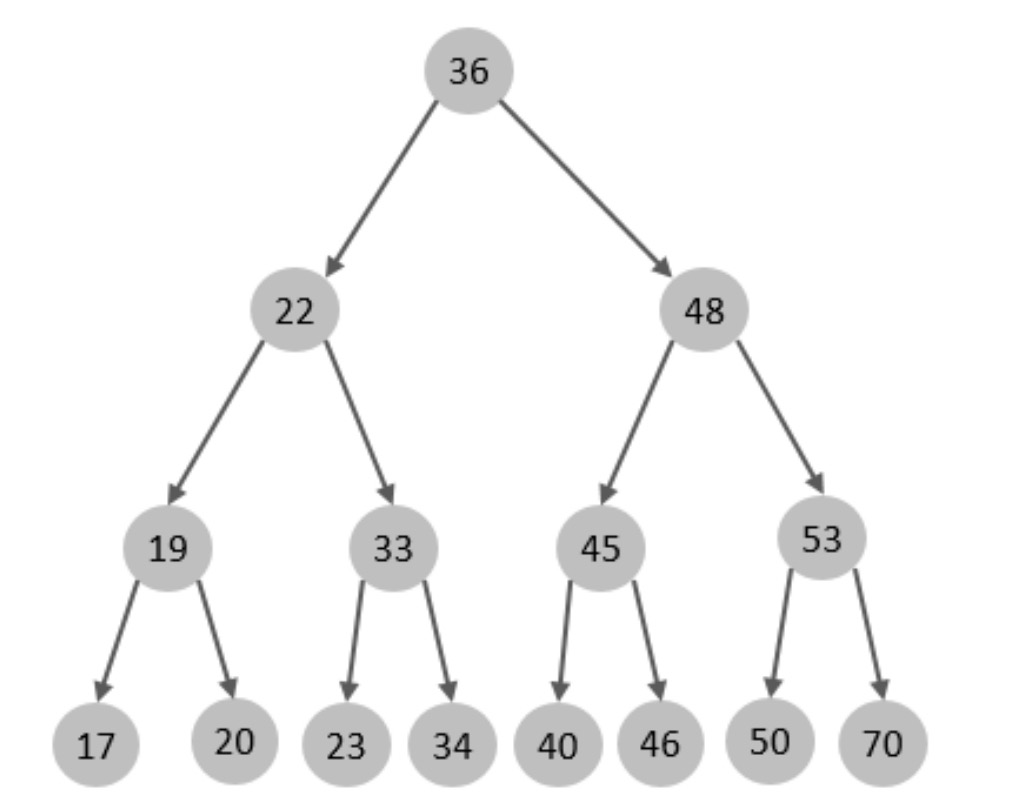
- If the primary key is inserted sequentially , Will form a one-way linked list , The structure is as follows :

- therefore , If you choose a binary tree as the index structure , There will be the following disadvantages :
- On sequential insertion , It will form a linked list , Query performance is greatly reduced .
- In case of large amount of data , Deeper levels , The retrieval speed is slow .
At this point, you may think , We can choose red and black trees , Red black tree is a self balanced binary tree , So even if you insert data sequentially , The resulting data structure is also a balanced binary tree , The structure is as follows :

- however , Even so , Because the red black tree is also a binary tree , So there will be a disadvantage :
- In case of large amount of data , Deeper levels , The retrieval speed is slow .
therefore , stay MySQL In the index structure of , Did not choose binary tree or red black tree , And the choice is B+Tree, So what is B+Tree Well ? In detail B+Tree Before , Let's first introduce a B-Tree
2.3 B-Tree
-
B-Tree,B A tree is a kind of multi fork road scale search tree , Relative to a binary tree ,B Each node of the tree can have multiple branches , That is, multi fork .
At a maximum degree (max-degree) by 5(5 rank ) Of b-tree For example , So this one B Each node of the tree can store up to 4 individual key,5 A pointer to the .

Knowledge tips : The degree of a tree refers to the number of child nodes of a node .
-
We can use a data structure visualization website to simply demonstrate . https://www.cs.usfca.edu/~galles/visualization/BTree.html

-
Insert a set of data : 100 65 169 368 900 556 780 35 215 1200 234 888 158 90 1000 88
120 268 250 . Then observe some data insertion process , Changes in nodes .

-
characteristic :
- 5 Step B Trees , Each node can store up to 4 individual key, Corresponding 5 A pointer to the .
- Once the node stores key The quantity has arrived 5, Will fission , The intermediate element splits up
- stay B In the tree , Both non leaf nodes and leaf nodes store data .
2.4 B+Tree
-
B+Tree yes B-Tree Variants , We have a maximum degree (max-degree) by 4(4 rank ) Of b+tree For example , Let's take a look at its structural diagram :

-
We can see , Two parts :
-
The green framed part , It's the index part , It only plays the role of indexing data , Don't store data .
-
The part framed in red , It's the data storage part , Specific data should be stored in its leaf node
-
-
We can use a data structure visualization website to simply demonstrate . https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html

-
Insert a set of data : 100 65 169 368 900 556 780 35 215 1200 234 888 158 90 1000 88
120 268 250 . Then observe some data insertion process , Changes in nodes .

-
In the end, we see ,B+Tree And B-Tree comparison , There are three main differences :
- All the data will appear in the leaf node .
- Leaf nodes form a one-way linked list .
- Non leaf nodes only serve to index data , The specific data is stored in the leaf node .
-
The structure we see above is standard B+Tree Data structure of , Next , Let's see MySQL After optimization in B+Tree.
- MySQL Index data structure for classic B+Tree optimized . In the original B+Tree On the basis of , Add a pointer to the linked list of adjacent leaf nodes , So we have a sequence pointer B+Tree, Improve the performance of interval access , Conducive to sorting .

- MySQL Index data structure for classic B+Tree optimized . In the original B+Tree On the basis of , Add a pointer to the linked list of adjacent leaf nodes , So we have a sequence pointer B+Tree, Improve the performance of interval access , Conducive to sorting .
2.5 Hash
- MySQL In addition to support B+Tree Indexes , It also supports an index type —Hash Indexes .
-
structure :
-
Hash index is to use a certain hash Algorithm , Convert key values to new hash value , Map to the corresponding slot , Then stored in hash In the table .[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-cbtQfHK5-1650629270340)(https://gitee.com/hzg-sss/typora-picture/raw/master/20220420102305.png)]
-
If two ( Or more ) Key value , Map to the same slot , They produced hash Conflict ( Also known as hash Collision ), It can be solved by linked list .[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-z78lMX5p-1650629270340)(https://gitee.com/hzg-sss/typora-picture/raw/master/20220420102342.png)]
-
-
characteristic :
- Hash Indexes can only be used for peer-to-peer comparisons (=,in), Range query is not supported (between,>,< ,…)
- Cannot complete sort operation with index
- High query efficiency , Usually ( non-existent hash Conflict situation ) It only needs one search , Efficiency is usually higher than B+tree Cable lead
-
Storage engine support
- stay MySQL in , Support hash The index is Memory Storage engine . and InnoDB It has adaptive function hash function ,hash The index is InnoDB The storage engine is based on B+Tree The index is automatically built under specified conditions .
Thinking questions : Why? InnoDB The storage engine chooses to use B+tree Index structure ?
Relative to a binary tree , Fewer levels , High search efficiency ;
about B-tree, Whether leaf nodes or non leaf nodes , Data will be saved , This causes a page to store
The key value of is reduced , The pointer decreases , Save a lot of data as well , Can only increase the height of the tree , Resulting in reduced performance ;
- relative Hash Indexes ,B+tree Support range matching and sorting operations ;
3. Index classification
1. Index type
-
stay MySQL database , The specific types of indexes are mainly divided into the following categories : primary key 、 unique index 、 General index 、 Full-text index .
-
primary key :
- meaning : The index created for the primary key in the table
- characteristic : Automatically created by default , There can only be one
- keyword :PRIMARY
-
unique index :
- meaning : Avoid duplicate values in a data column in the same table
- characteristic : There can be multiple
- keyword :UNIQUE
-
General index :
- meaning : Quickly locate specific data
- characteristic : There can be multiple
- keyword : nothing
-
Full-text index :
- meaning : The full-text index looks up the keywords in the text , Instead of comparing the values in the index
- characteristic : There can be multiple
- keyword :FULLTEXT
-
2. Clustered index & Secondary indexes
-
And in the InnoDB In the storage engine , According to the storage form of the index , It can be divided into the following two types :
- Clustered index (ClusteredIndex)
- meaning : Put data storage and index together , The leaf node of the index structure holds the row data
- characteristic : There has to be , And there's only one
- General index :
- meaning : Separate data from index , The leaf node of the index structure is associated with the corresponding primary key
- characteristic : There can be multiple
- Clustered index (ClusteredIndex)
-
Clustered index selection rules :
-
If there is a primary key , A primary key index is a clustered index .
-
If there is no primary key , The first unique... Will be used (UNIQUE) Index as clustered index .
-
If the table does not have a primary key , Or there is no suitable unique index , be InnoDB It will automatically generate a rowid As a hidden clustered index .
-
-
The specific structures of clustered index and secondary index are as follows :
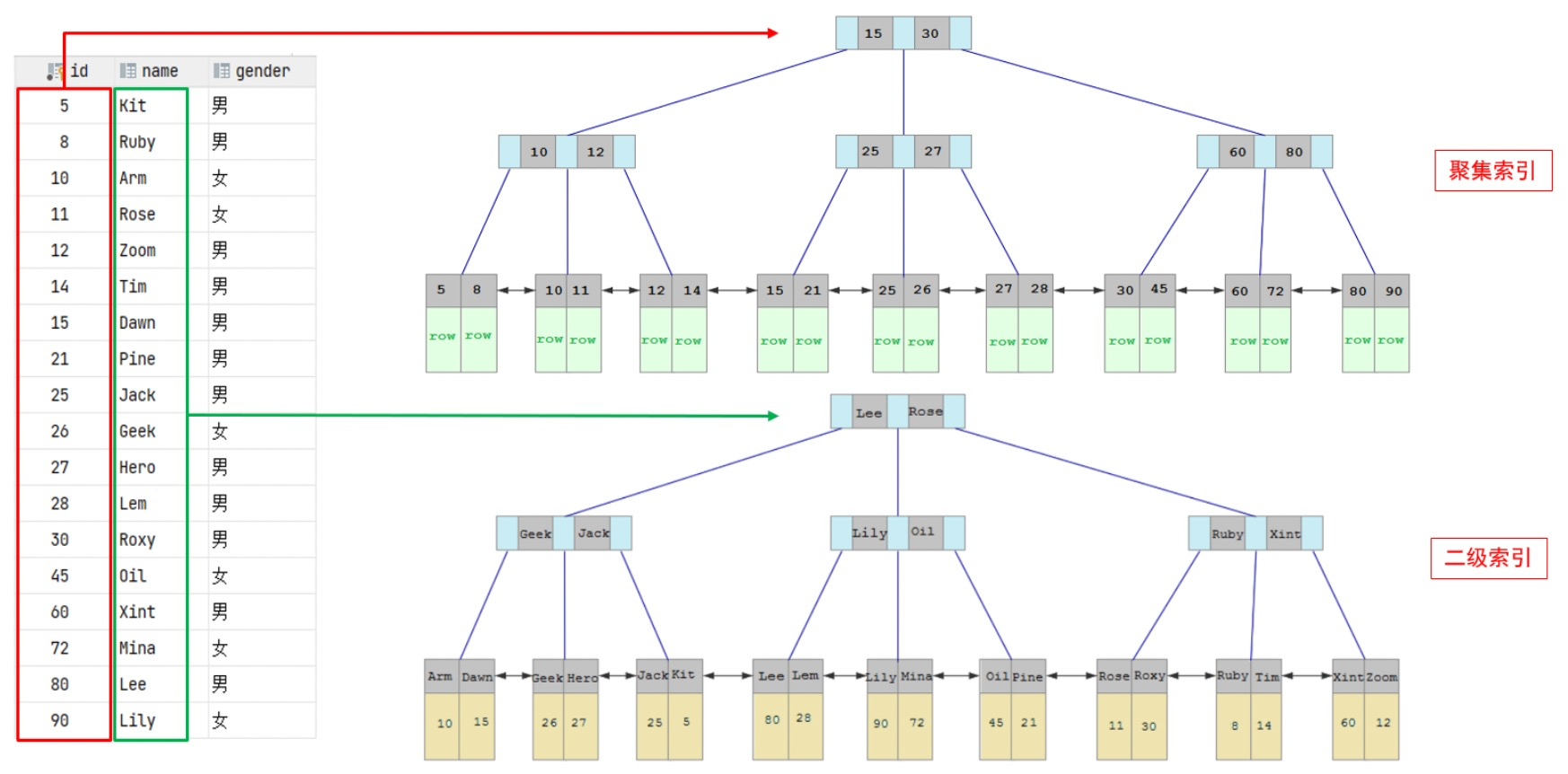
-
The data of this row is hung under the leaf node of the clustered index .
-
The primary key value corresponding to the field value is hung under the leaf node of the secondary index .
-
-
Next , Let's analyze , When we execute the following SQL When the sentence is , What is the specific search process like .

-
The specific process is as follows :
- Because it's based on name Field to query , So first according to name='Arm’ To name Field in the secondary index . But in the secondary index, you can only find Arm The corresponding primary key value 10.
- Because the data returned by the query is *, So at this time , You also need to use the primary key value 10, Find in the clustered index 10 Corresponding records , Finally find 10 The corresponding line row.
- Finally get the data of this line , Just go back .
Return to the table for query : This first to look up data in the secondary index , Find primary key value , Then it is added to the clustered index according to the primary key value , How to get the data , It is called back to table query .
Thinking questions :
Here are two SQL sentence , The execution efficiency is high ? Why? ?
A. select * from user where id = 10 ;
B. select * from user where name = ‘Arm’ ;
remarks : id Primary key ,name Fields are indexed ;
answer :
A The execution performance of the statement is higher than B sentence .
because A Statement goes directly to the clustered index , Direct return data . and B The statement needs to query name The secondary index of the field , Then query the clustered index , That is, you need to query back to the table .
4. Index Syntax
- Create index
CREATE [ UNIQUE | FULLTEXT ] INDEX index_name ON table_name (index_col_name,... ) ;
- Look at the index
SHOW INDEX FROM table_name ;
- Delete index
DROP INDEX index_name ON table_name ;
Case presentation
- Let's create a table first tb_user, And query the test data .
create table tb_user(
id int primary key auto_increment comment ' Primary key ',
name varchar(50) not null comment ' user name ',
phone varchar(11) not null comment ' cell-phone number ',
email varchar(100) comment ' mailbox ',
profession varchar(11) comment ' major ',
age tinyint unsigned comment ' Age ',
gender char(1) comment ' Gender , 1: male , 2: Woman ',
status char(1) comment ' state ',
createtime datetime comment ' Creation time '
) comment ' System user table ';
INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime) VALUES (' Lyu3 bu4 ', '17799990000', '[email protected]', ' Software Engineering ', 23, '1', '6', '2001-02-02 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime) VALUES (' Cao Cao ', '17799990001', '[email protected]', ' Communication Engineering ', 33, '1', '0', '2001-03-05 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime) VALUES (' zhaoyun ', '17799990002', '[email protected]', ' English ', 34, '1', '2', '2002-03-02 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime) VALUES (' The Monkey King ', '17799990003', '[email protected]', ' Project cost ', 54, '1', '0', '2001-07-02 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime) VALUES (' Hua mu LAN ', '17799990004', '[email protected]', ' Software Engineering ', 23, '2', '1', '2001-04-22 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime) VALUES (' Big Joe ', '17799990005', '[email protected]', ' dance ', 22, '2', '0', '2001-02-07 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime) VALUES (' Luna ', '17799990006', '[email protected]', ' Applied Mathematics ', 24, '2', '0', '2001-02-08 00:00:00'); 12345678910111213141516171819
INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime) VALUES (' Cheng Yaojin ', '17799990007', '[email protected]', ' chemical ', 38, '1', '5', '2001-05-23 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime) VALUES (' Xiang yu ', '17799990008', '[email protected]', ' Metal material ', 43, '1', '0', '2001-09-18 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime) VALUES (' White ', '17799990009', '[email protected]', ' Mechanical engineering and its automation turn ', 27, '1', '2', '2001-08-16 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime) VALUES (' Han xin ', '17799990010', '[email protected]', ' Inorganic nonmetallic material worker cheng ', 27, '1', '0', '2001-06-12 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime) VALUES (' Jingke ', '17799990011', '[email protected]', ' accounting ', 29, '1', '0', '2001-05-11 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime) VALUES (' The king of Lanling ', '17799990012', '[email protected]', ' Project cost ', 44, '1', '1', '2001-04-09 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime) VALUES (' Berserker iron ', '17799990013', '[email protected]', ' Applied Mathematics ', 43, '1', '2', '2001-04-10 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime) VALUES (' The sable cicada ', '17799990014', '[email protected]', ' Software Engineering ', 40, '2', '3', '2001-02-12 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime) VALUES (' Daji ', '17799990015', '[email protected]', ' Software Engineering ', 31, '2', '0', '2001-01-30 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime) VALUES (' Mi month ', '17799990016', '[email protected]', ' industrial economy ', 35, '2', '0', '2000-05-03 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime) VALUES (' Ying Zheng ', '17799990017', '[email protected]', ' chemical ', 38, '1', '1', '2001-08-08 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime) VALUES (' Judge dee ', '17799990018', '[email protected]', ' International Trade ', 30, '1', '0', '2007-03-12 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime) VALUES (' Angela ', '17799990019', '[email protected]', ' city planning ', 51, '2', '0', '2001-08-15 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime) VALUES (' Dianwei ', '17799990020', '[email protected]', ' city planning ', 52, '1', '2', '2000-04-12 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime) VALUES (' Lian po ', '17799990021', '[email protected]', ' Civil Engineering ', 19, '1', '3', '2002-07-18 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime) VALUES (' Hou Yi ', '17799990022', '[email protected]', ' Urban landscape ', 20, '1', '0', '2002-03-10 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime) VALUES (' Jiang Ziya ', '17799990023', '[email protected]', ' Project cost ', 29, '1', '4', '2003-05-26 00:00:00');
-
When the data is ready , Next , Let's complete the following requirements :
- A. name The field is the name field , The value of this field may be repeated , Create an index for this field .
CREATE INDEX idx_user_name ON tb_user(name);- B. phone The value of the mobile phone number field , Right and wrong , And only , Create a unique index for this field .
CREATE UNIQUE INDEX idx_user_phone ON tb_user(phone);- C. by profession、age、status Create a federated index .
CREATE INDEX idx_user_pro_age_sta ON tb_user(profession,age,status);- D. by email Establish an appropriate index to improve query efficiency .
CREATE INDEX idx_email ON tb_user(email);- After completing the above requirements , Let's see tb_user All index data of the table .
show index from tb_user;

5.SQL Performance analysis
1.SQL Frequency of execution
MySQL After successful client connection , adopt show [session|global] status Command can provide server status information . By the following instructions , You can view the INSERT、UPDATE、DELETE、SELECT Frequency of visits :
-- session Is to view the current session ;
-- global Global query is data ;
SHOW GLOBAL STATUS LIKE 'Com_______';

-
Com_delete: Number of deletions
-
Com_insert: Number of inserts
-
Com_select: Query times
-
Com_update: Number of updates
-
We can perform several more query operations in the current database , Then check the execution frequency again , have a look Com_select Whether the parameters will change .

Through the above instructions , We can see whether the current database is based on query , Or mainly add, delete and modify , So as to provide data
Provide reference basis for library optimization . If it is mainly based on addition, deletion and modification , We can consider not optimizing the index . If so
Query based , Then we should consider optimizing the index of the database .
Then through the query SQL Frequency of execution of , We can know whether the current database is mainly for addition, deletion and modification , Or mainly query . If it is mainly based on query , How can we optimize those query statements ? The number of times we can use the slow query log .
2. Slow query log
-
The slow query log records all execution times that exceed the specified parameters (long_query_time, Company : second , Default 10 second ) All of the SQL Statement log .
-
MySQL The slow query log is not enabled by default , We can look at the system variables slow_query_log.

-
If you want to start slow query log , Need to be in MySQL Configuration file for (/etc/my.cnf) The following information is configured in :
# Turn on MySQL Slow log query switch slow_query_log=1 # Set the time of slow log to 2 second ,SQL Statement execution time exceeds 2 second , It will be regarded as slow query , Log slow queries long_query_time=2 -
If you want to start slow query log , Need to be in MySQL Configuration file for (/etc/my.cnf) The following information is configured in :
# /var/lib/mysql/localhost-slow.log. # Restart MySQL The server systemctl restart mysqld -
then , Check the switch again , The slow query log has been opened .

test :
- The implementation is as follows SQL sentence :
-- This article SQL The execution efficiency is quite high , Execution time consuming 0.00sec
select * from tb_user;
-- because tb_sku In the table , Pre deposited 1000w The record of , count once , Time consuming 13.35sec
select count(*) from tb_sku;
[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-d0zLtmzz-1650629270341)(https://gitee.com/hzg-sss/typora-picture/raw/master/20220421082932.png)]
-
Check the slow query log :
- In the end, we found out , In slow query log , Only the execution time will be recorded, which exceeds our preset time (2s) Of SQL, Perform faster SQL It won't be recorded .
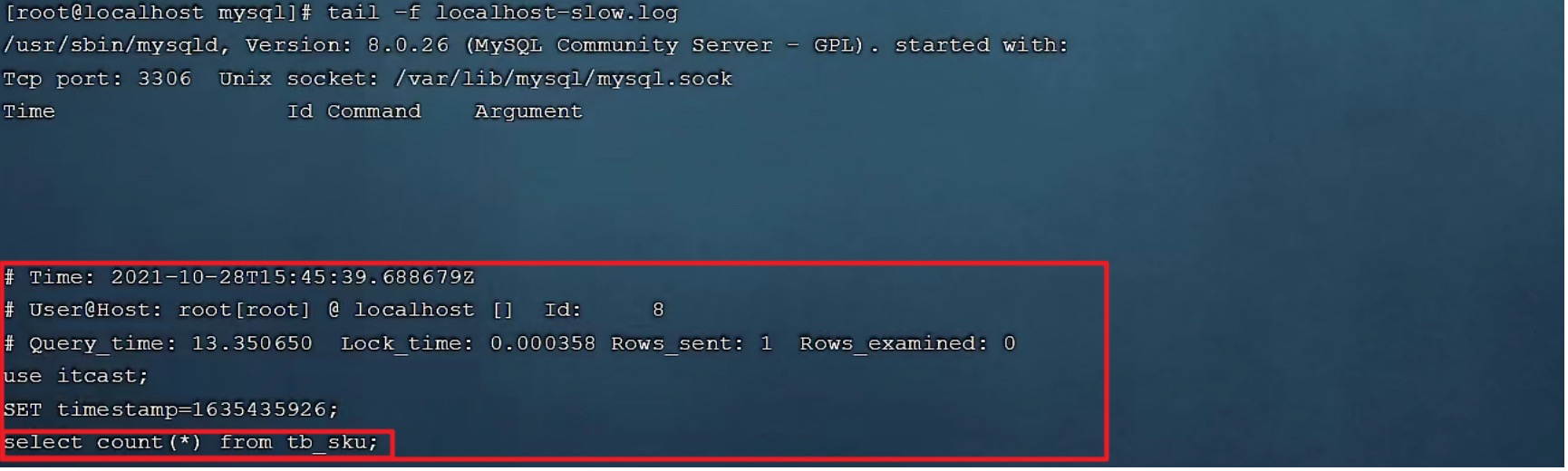
- In the end, we found out , In slow query log , Only the execution time will be recorded, which exceeds our preset time (2s) Of SQL, Perform faster SQL It won't be recorded .
-
That such , Log by slow query , We can locate those with low execution efficiency SQL, Thus targeted optimization .
3.profile**** details
-
show profiles Be able to do SQL Optimization helps us understand where the time is spent . adopt have_profiling
Parameters , Be able to see the present MySQL Do you support profile operation :
SELECT @@have_profiling ;

-
You can see , At present MySQL It's supporting profile Operation of the , But the switch is off . Can pass set Statements in
session/global Level on profiling:
SET profiling = 1; -
The switch has been turned on , Next , What we do SQL sentence , Will be MySQL Record , And record where the execution time is spent . We directly execute the following SQL sentence :
select * from tb_user; select * from tb_user where id = 1; select * from tb_user where name = ' White '; select count(*) from tb_sku; -
Execute a series of business SQL The operation of , Then check the execution time of the instruction through the following instructions :
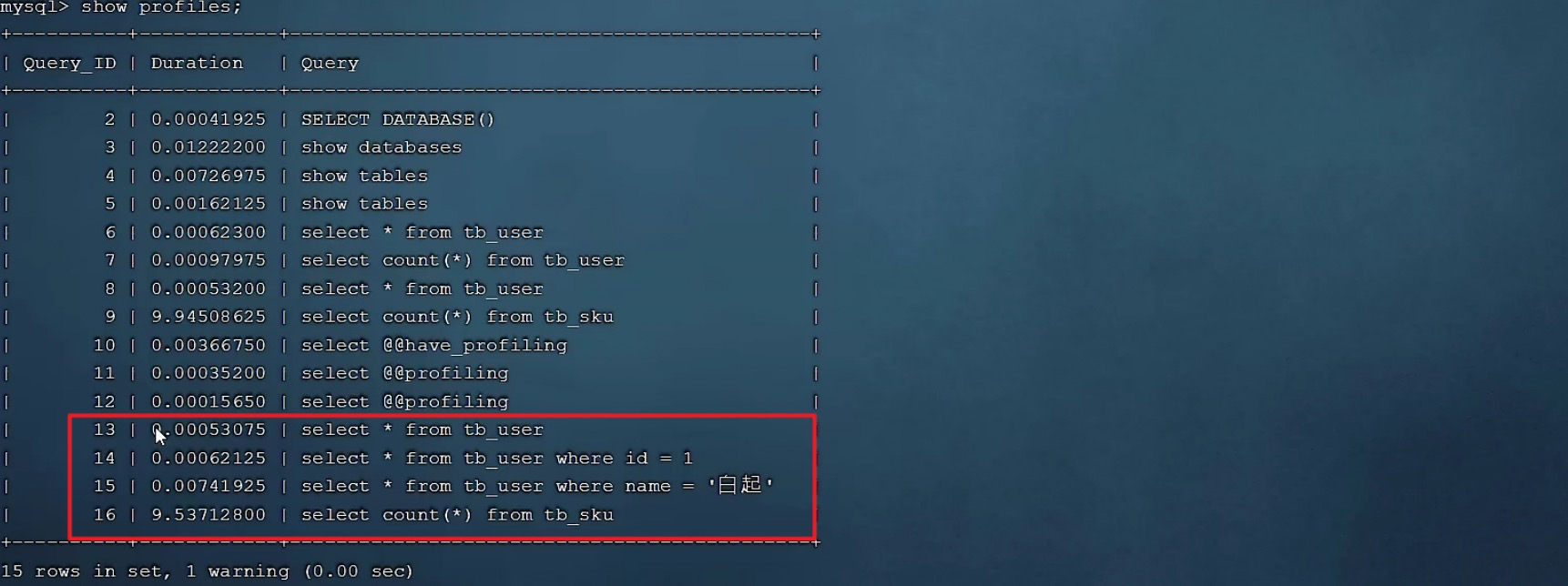
-- Check each one SQL The time-consuming basic situation of show profiles; -- View specified query_id Of SQL The time-consuming situation of each stage of the statement show profile for query query_id; -- View specified query_id Of SQL sentence CPU Usage situation show profile cpu for query query_id; -
Check each one SQL Time consuming :
-
View specified SQL The time-consuming situation of each stage :

4.explain
-
EXPLAIN perhaps DESC Command acquisition MySQL How to execute SELECT Statement information , Included in SELECT How tables are joined and the order in which they are joined during statement execution .
-
grammar :
-- Directly in select Add the keyword before the statement explain / desc EXPLAIN SELECT Field list FROM Table name WHERE Conditions ; -
result

-
-
Explain The meaning of each field in the execution plan :
- id : select The serial number of the query , Represents execution in a query select Clause or the order of the operation table (id identical , Execution order from top to bottom ;id Different , The bigger the value is. , Execute first ).
- select_type : Express SELECT The type of , Common values are SIMPLE( A simple watch , That is, no table join or subquery is used )、PRIMARY( Main query , That is, the outer query )、UNION(UNION The second or subsequent query statement in )、SUBQUERY(SELECT/WHERE Then it contains sub queries ) etc.
- type : Indicates the connection type , The connection types with good to poor performance are NULL、system、const、eq_ref、ref、range、 index、all .
- possible_key : Displays the indexes that may be applied to this table , One or more .
- key : Actual index used , If NULL, No index is used .
- key_len : Represents the number of bytes used in the index , This value is the maximum possible length of the index field , It's not the actual length , Without losing accuracy , The shorter the length, the better .
- rows : MySQL The number of rows that you think you must execute the query , stay innodb In the engine's table , Is an estimate , It may not always be accurate .
- filtered : Represents the number of rows returned as a percentage of the number of rows to be read , filtered The greater the value, the better .
6. Index usage
1. Verify index efficiency
-
Before explaining the principles of index use , Let's start with a simple case , To verify the index , See if you can improve data query performance by indexing . During the demonstration , Let's use the form we prepared before tb_sku , In this table 1000w The record of .

-
In this list id Primary key , There's a primary key index , Other fields are not indexed . Let's first query one of the records , Look at the fields inside , The implementation is as follows SQL:
select * from tb_sku where id = 1\G;
-
You can see that even if there is 1000w The data of , according to id Data query , The performance is still very fast , Because the primary key id It's indexed . So next , Let's go again according to sn Field to query , The implementation is as follows SQL:
SELECT * FROM tb_sku WHERE sn = '100000003145001';
-
We can see the basis sn Field to query , The query returned a piece of data , The result is time consuming 20.78sec, Because of sn No index , And the query efficiency is very low . Then we can aim at sn Field , Build an index , After indexing , We are again based on sn The query , Let's take a look at the query time .
-
Create index :
create index idx_sku_sn on tb_sku(sn) ; -
And then do the same again SQL sentence , Look again SQL Time consuming .
SELECT * FROM tb_sku WHERE sn = '100000003145001';
-
We will obviously see ,sn After the field is indexed , Query performance is greatly improved . Before and after indexing , The query time is not an order of magnitude .
2. The leftmost prefix rule
-
If you index multiple columns ( Joint index ), Follow the leftmost prefix rule . The leftmost prefix rule means that the query starts from the leftmost column of the index , And don't skip columns in the index . If you jump a column , The index will be partially invalidated ( The following field index is invalid ).
-
With tb_user Table as an example , Let's take a look at the previous tb_user The index created by the table .

-
stay tb_user In the table , There is a joint index , This joint index involves three fields , The order is :profession,age,status.
-
For the leftmost prefix, the law refers to , When inquiring , Leftmost column , That is to say profession There must be , Otherwise, all indexes will be invalid . And you can't skip a column in the middle , Otherwise, the field index behind the column will be invalidated . Next , Let's demonstrate several groups of cases , Take a look at the specific implementation plan :
-
explain select * from tb_user where profession = ' Software Engineering ' and age = 31 and status = '0';
-
explain select * from tb_user where profession = ' Software Engineering ' and age = 31;
-
explain select * from tb_user where profession = ' Software Engineering ';
-
Of the above three sets of tests , We found that as long as the leftmost field of the joint index profession There is , The index will take effect , But the length of the index is different . And tested by the above three groups , We can also speculate that profession The length of the field index is 47、age The length of the field index is 2、status The length of the field index is 5.
-
explain select * from tb_user where age = 31 and status = '0';
-
explain select * from tb_user where status = '0';[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-x3K6cRZ5-1650629270343)(https://gitee.com/hzg-sss/typora-picture/raw/master/20220421090046.png)]
-
And through the above two sets of tests , We can also see that the index is not effective , The reason is that the leftmost prefix rule is not satisfied , The leftmost column of the union index profession non-existent .
-
explain select * from tb_user where profession = ' Software Engineering ' and status = '0';[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-2Jvc6fUl-1650629270343)(https://gitee.com/hzg-sss/typora-picture/raw/master/20220421090126.png)]
-
Aforementioned SQL When inquiring , There is profession Field , The leftmost column exists , The index satisfies the basic condition of the leftmost prefix rule . But when querying , Skip the age This column , So the following column indexes will not be used , That is, the index part takes effect , So the length of the index is 47.
3. Range queries
-
In the union index , Range query appears (>,<), The column index on the right side of the range query is invalid .
-
explain select * from tb_user where profession = ' Software Engineering ' and age > 30 and status = '0';
-
When range queries use > or < when , Let's go , But the length of the index is 49, It indicates that the query range is on the right status Fields are not indexed .
-
explain select * from tb_user where profession = ' Software Engineering ' and age >= 30 and status = '0';
-
When range queries use >= or <= when , Let's go , But the length of the index is 54, It means that all fields are indexed .
-
therefore , When business allows , Use as much as possible similar to >= or <= This kind of range query , Avoid using > or < .
4. Index failure
1. Column operation of index
-
Do not operate on index columns , Index will fail .
-
Case study :
-
stay tb_user In the table , In addition to the union index described earlier , There is also an index , yes phone Single column index of the field .

-
A. When according to phone When performing equivalent matching query on fields , The index works .
explain select * from tb_user where phone = '17799990015';
-
B. When according to phone After the function operation of the field , Index failure .
explain select * from tb_user where substring(phone,10,2) = '15';
-
2. String without quotes
-
When using string type fields , Without quotes , Index will fail .
-
Case study :
-
We use two sets of examples , Let's look at fields of string type , The difference between single quotation mark and no single quotation mark :
explain select * from tb_user where profession = ' Software Engineering ' and age = 31 and status = '0'; explain select * from tb_user where profession = ' Software Engineering ' and age = 31 and status = 0;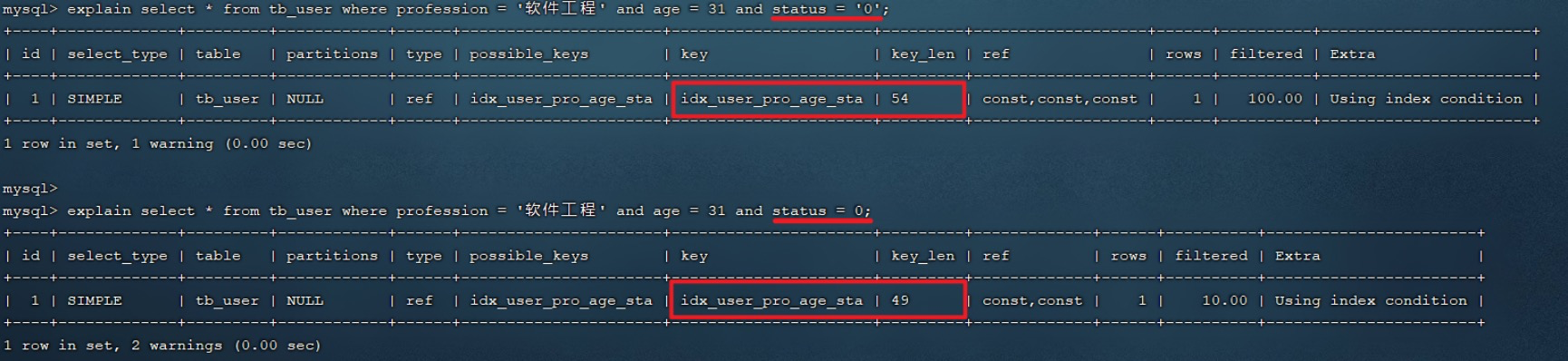
explain select * from tb_user where phone = '17799990015'; explain select * from tb_user where phone = 17799990015;
-
After the above two sets of examples , We will clearly find , If the string is not in single quotation marks , For query results , It doesn't matter , But the database has implicit type conversion , Index will fail .
-
3. Fuzzy query
-
If it's just tail blur matching , The index will not fail . If it's a fuzzy head match , Index failure .
-
Case study :
-
Let's take a look at these three SQL Statement execution effect , Take a look at its implementation plan :
-
Because in the following query statement , Are all based on profession A field , Conform to the leftmost prefix rule , The union index is valid , Let's mainly take a look at , Fuzzy query ,% Add before keyword , And the influence added after the keyword .
explain select * from tb_user where profession like ' Software %'; explain select * from tb_user where profession like '% engineering '; explain select * from tb_user where profession like '% work %';
-
After the above tests , We found that , stay like Fuzzy query , Add the keyword after %, The index can work . And if you add... In front of the keyword %, The index will fail .
-
4.or Connection condition
-
Case study
-
use or The conditions of separation , If or The columns in the previous condition are indexed , And there's no index in the next column , Then the indexes involved will not be used .
explain select * from tb_user where id = 10 or age = 23; explain select * from tb_user where phone = '17799990017' or age = 23;
-
because age No index , So even id、phone There is an index , Indexes will also fail . So you need a needle for age Also index . then , We can age Field indexing .
create index idx_user_age on tb_user(age);
-
After indexing , Let's do the above again SQL sentence , Look at the changes in the implementation plan before and after .

-
Final , We found that , When or The conditions of connection , When the left and right fields have indexes , The index will take effect .
-
5. Data distribution affects
-
If MySQL Evaluation uses indexes more slowly than full tables , Index is not used .
-
Case study
select * from tb_user where phone >= '17799990005'; select * from tb_user where phone >= '17799990015';

-
After testing, we found that , same SQL sentence , Only the field values passed in are different , The final implementation plan is also completely different , Why is that ?
- Because of MySQL In the query , Will evaluate the efficiency of using the index and the efficiency of full table scanning , If you walk the whole table, scanning is faster , Then abandon the index , Take a full scan . Because the index is used to index a small amount of data , If large quantities of data are returned through index query , It's not as fast as scanning the whole table , At this point, the index will be invalidated .
5.SQL**** Tips
-
Let's follow the table above , Check the index

-
Put the above idx_user_age, idx_email The two indexes used in the previous test are deleted directly .
drop index idx_user_age on tb_user; drop index idx_email on tb_user; -
A. perform SQL : explain select * from tb_user where profession = ‘ Software Engineering ’;

- The query left the union index .
-
B. perform SQL, establish profession A single column index of :create index idx_user_pro ontb_user(profession);

-
C. After creating a single column index , Re execution A Medium SQL sentence , View execution plan , See which index to go .

-
test result , We can see ,possible_keys in idx_user_pro_age_sta,idx_user_pro Both indexes may use , Final MySQL I chose idx_user_pro_age_sta Indexes . This is a MySQL The result of automatic selection .
-
that , Can we check when , Specify which index to use by yourself ? The answer is yes , At this point, you can use MySQL Of SQL Prompt to complete . Next , Introduce to you SQL Tips .
-
SQL Tips , Is an important means to optimize the database , Simply speaking , Is in the SQL Add some human prompts in the statement to optimize the operation .
- use index : Suggest MySQL Which index to use to complete this query ( It's just advice ,mysql Internal evaluation will be conducted again ).
explain select * from tb_user use index(idx_user_pro) where profession = ' Software engineering cheng ';- ignore index : Ignore the specified index .
explain select * from tb_user ignore index(idx_user_pro) where profession = ' Software engineering cheng ';- force index : Force index .
explain select * from tb_user force index(idx_user_pro) where profession = ' Software engineering cheng '; -
Examples demonstrate
-
A. use index
explain select * from tb_user use index(idx_user_pro) where profession = ' Software engineering cheng ';
-
B. ignore index
explain select * from tb_user ignore index(idx_user_pro) where profession = ' Software engineering cheng ';[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-2zLjTrzT-1650629270345)(https://gitee.com/hzg-sss/typora-picture/raw/master/20220422193556.png)]
-
C. force index
explain select * from tb_user force index(idx_user_pro_age_sta) where profession = ' Software Engineering ';
-
-
6 . Overlay index
-
Try to use overlay index , Reduce select *. So what is an overlay index ? Overlay index means The query uses an index , And the columns that need to be returned , All can be found in this index .
-
Let's look at a group SQL Implementation plan of , Look at the differences in the implementation plan , Then we will do a specific analysis .
explain select id, profession from tb_user where profession = ' Software Engineering ' and age = 31 and status = '0' ; explain select id,profession,age, status from tb_user where profession = ' Software Engineering ' and age = 31 and status = '0' ; explain select id,profession,age, status, name from tb_user where profession = ' soft Piece of work ' and age = 31 and status = '0' ; explain select * from tb_user where profession = ' Software Engineering ' and age = 31 and status = '0';- The above items SQL The execution result of is :

-
From the above implementation plan, we can see , These four SQL All indicators in front of the execution plan of the statement are the same , I can't see the difference . But at this time , Our main focus is on the latter Extra, The first two days SQL As the result of the Using where; Using Index ; And the last two SQL As the result of the : Using index condition .
- Using where; Using Index : Search uses index , But all the data needed can be found in the index column , So you don't need to go back to the table to query the data
- Using index condition : Search uses index , But you need to return the table to query the data
-
because , stay tb_user There is a union index in the table idx_user_pro_age_sta, The index is associated with three fields profession、age、status, And this index is also a secondary index , Therefore, the primary key of this row is hung under the leaf node id. So when we query the returned data in id、profession、age、status In , Then go directly to the secondary index and directly return the data . If it goes beyond this range , You need to get the primary key id, Then scan the clustered index , Get additional data , This process is back to the table . And if we keep using select * The query returns all field values , It is easy to cause back to table query ( Unless the query is based on the primary key , Only the clustered index will be scanned at this time ).
-
For a clearer understanding , What is an overlay index , What is return table query , Let's take a look at the following group SQL Implementation process of .
A. Table structure and index diagram :

-
id It's the primary key , Is a clustered index . name The field establishes a general index , Is a secondary index ( Secondary index ).
B. perform SQL : select * from tb_user where id = 2;
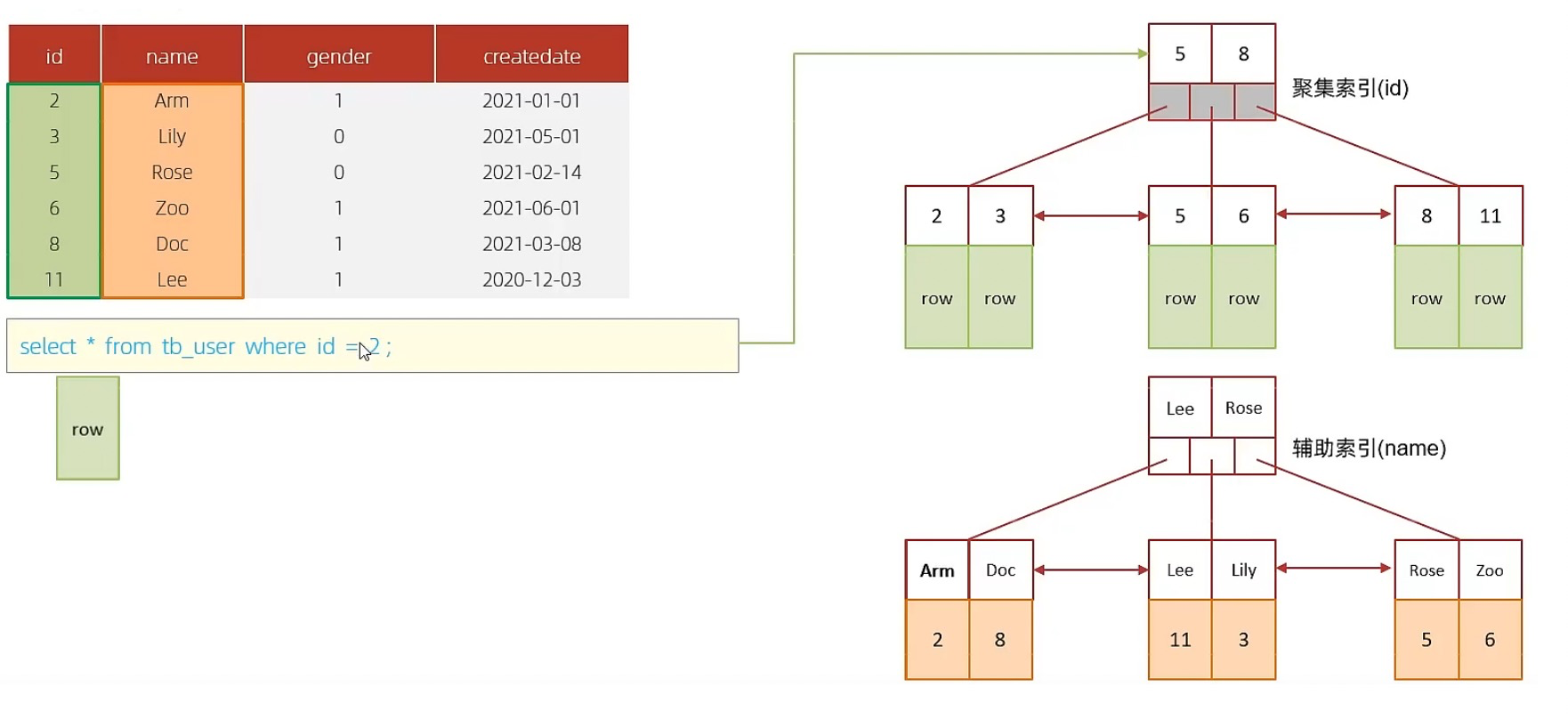
-
according to id Inquire about , Go directly to the clustered index query , An index scan , Direct return data , High performance
C. perform SQL:selet id,name from tb_user where name = ‘Arm’;

-
Although it is based on name A field , Query secondary index , But because the query returns in the field id,name, stay name In the secondary index of , These two values can be obtained directly , Because the overlay index , So there is no need to query back to the table , High performance .
D. perform SQL:selet id,name,gender from tb_user where name = ‘Arm’;
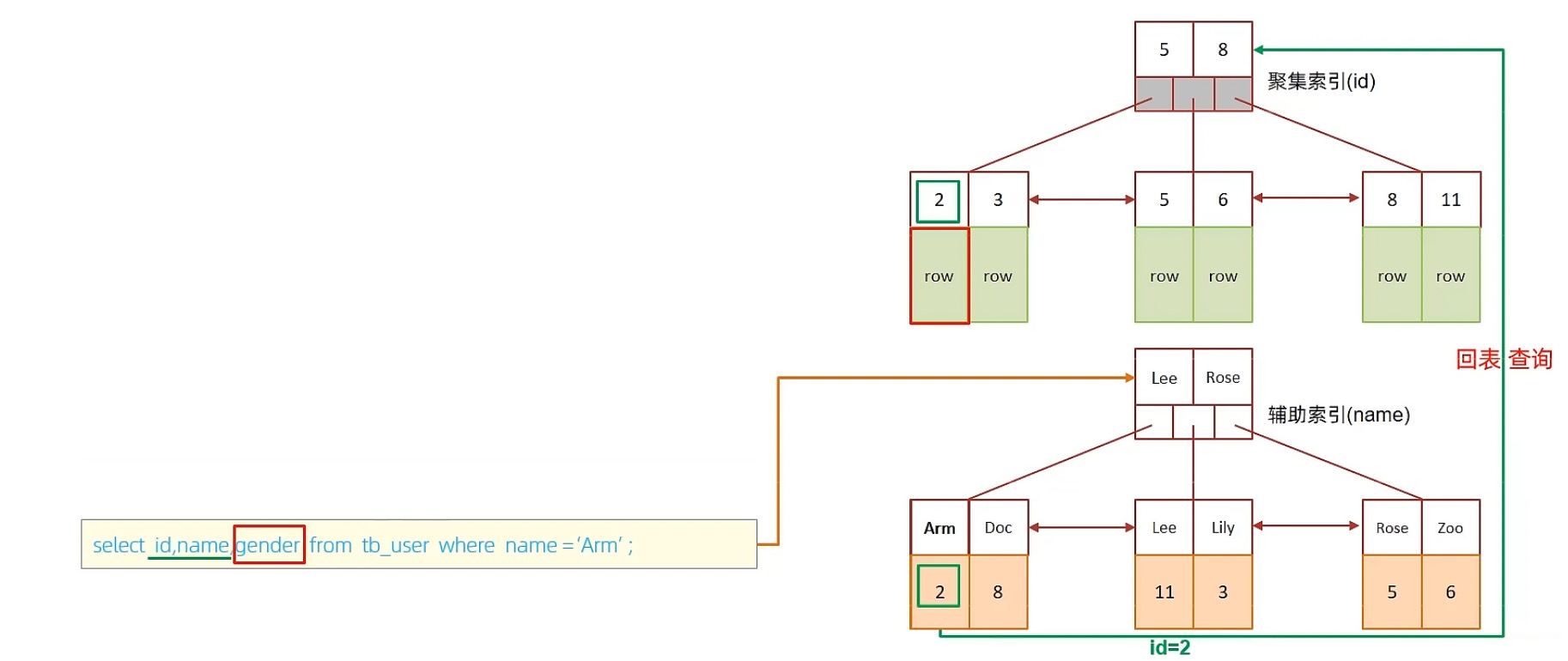
-
Because in name In the secondary index of , It doesn't contain gender, therefore , Two index scans are required , That is, you need to query back to the table , The performance is relatively poor .
Thinking questions :
- A watch , There are four fields (id, username, password, status), Because of the amount of data , The following SQL Statement optimization , How to proceed is the best solution :
select id,username,password from tb_user where username ='itcast';
- answer : Aim at username, password Set up a joint index , sql by : create index
idx_user_name_pass on tb_user(username,password);
- This can avoid the above SQL sentence , During the query , The back table query... Appears .
7. Prefix index
- When the field type is string (varchar,text,longtext etc. ) when , Sometimes you need to index long strings , This makes the index big , When inquiring , Waste a lot of disk IO, Affecting query efficiency . At this point, you can prefix only part of the string with , Index , This can greatly save index space , To improve index efficiency .
- grammar :
create index idx_xxxx on table_name(column(n)) ;
-
Example :
-
by tb_user Tabular email Field , Set the length to 5 Prefix index of .
create index idx_email_5 on tb_user(email(5));[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-VbsrO5hw-1650629270346)(https://gitee.com/hzg-sss/typora-picture/raw/master/20220422195014.png)]
-
- Prefix length
-
It can be determined according to the selectivity of the index , Selectivity refers to index values that are not repeated ( base ) And the total number of records in the data table , The higher the index selectivity, the higher the query efficiency , The only index selectivity is 1, This is the best index selectivity , Performance is also the best .
select count(distinct email) / count(*) from tb_user ; select count(distinct substring(email,1,5)) / count(*) from tb_user ;
-
The query process of prefix index

8. Single column index and joint index
-
Single index : That is, an index contains only a single column .
-
Joint index : That is, an index contains multiple columns .
-
Let's take a look first tb_user The current index in the table :

- In the queried index , Existing single column index , There is also a joint index .
-
Next , Let's execute a SQL sentence , Look at its implementation plan :

- From the above implementation plan, we can see , stay and Two fields connected phone、name There are single column indexes on , But in the end mysql Only one index will be selected , in other words , The index of only one field , At this time, the table query will be returned .
-
Then , Let's create another phone and name Field to query the execution plan .
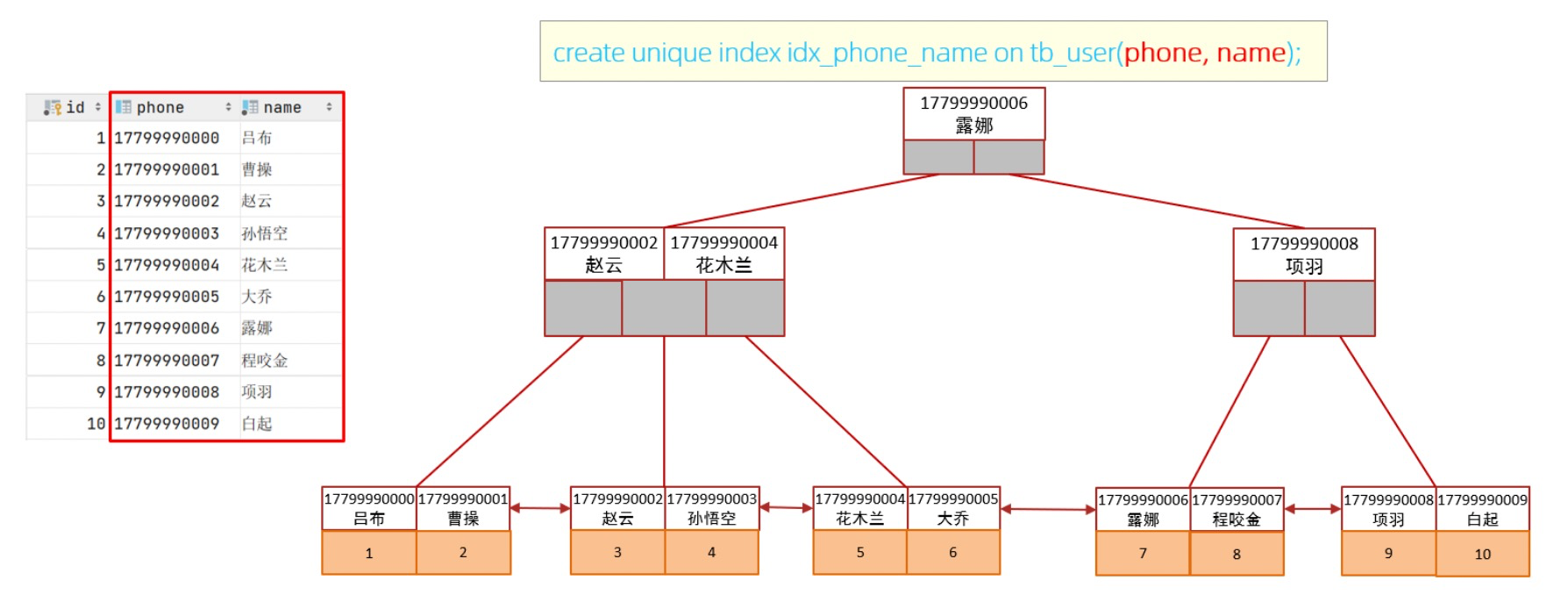
create unique index idx_user_phone_name on tb_user(phone,name);
- here , When inquiring , Just left, joint index , And include in the joint index phone、name Information about , The corresponding primary key is hung under the leaf node id, Therefore, there is no need to query back to the table .
In the business scenario , If there are multiple query criteria , Consider when indexing fields , It is recommended to establish a joint index , Instead of a single column index .
-
If the query uses a federated index , The specific structural diagram is as follows :
7. Index design principles
-
For large amount of data , The tables that are frequently queried are indexed .
-
For often used as query criteria (where)、 Sort (order by)、 grouping (group by) Index the fields of the operation .
- Try to select highly differentiated columns as indexes , Try to build a unique index , The more distinguishable , The more efficient the index is .
-
If it is a string type field , The length of the field is long , You can focus on the characteristics of the field , Building prefix index .
-
Try to use a federated index , Reduce single column index , When inquiring , Joint indexes can often overwrite indexes , Save storage space , Avoid returning to your watch , Improve query efficiency .
-
To control the number of indexes , The index is not that more is better , More indexes , The greater the cost of maintaining the index structure , It will affect the efficiency of addition, deletion and modification .
-
If the index column cannot store NULL value , Please use... When creating the table NOT NULL Constrain it . When the optimizer knows whether each column contains NULL When the value of , It can better determine which index is most effectively used for queries .
版权声明
本文为[Crisp_ LF]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204231727096349.html
边栏推荐
- Solution of Navicat connecting Oracle library is not loaded
- 402. Remove K digits - greedy
- SiteServer CMS5. 0 Usage Summary
- RPC核心概念理解
- HCIP第五次实验
- 01-初识sketch-sketch优势
- 1217_使用SCons生成目标文件
- Use of todesk remote control software
- 209. Minimum length subarray - sliding window
- If you start from zero according to the frame
猜你喜欢
Advantages and disadvantages of several note taking software
Kubernetes 服务发现 监控Endpoints

How to change input into text
![Using quartz under. Net core -- general properties and priority of triggers for [5] jobs and triggers](/img/65/89473397da4217201eeee85aef3c10.png)
Using quartz under. Net core -- general properties and priority of triggers for [5] jobs and triggers
394. 字符串解码-辅助栈
Matlab / Simulink simulation of double closed loop DC speed regulation system
102. 二叉树的层序遍历

470. 用 Rand7() 实现 Rand10()
ASP. NET CORE3. 1. Solution to login failure after identity registers users

Qt error: /usr/bin/ld: cannot find -lGL: No such file or directory
随机推荐
How to use the input table one-way service to send (occupy less) picture files (body transmission)? FileReader built-in object involved
Using quartz under. Net core -- general properties and priority of triggers for [5] jobs and triggers
Oninput one function to control multiple oninputs (take the contents of this input box as parameters) [very practical, very practical]
Metaprogramming, proxy and reflection
92. 反转链表 II-字节跳动高频题
How to manually implement the mechanism of triggering garbage collection in node
练习:求偶数和、阈值分割和求差( list 对象的两个基础小题)
基于51单片机红外无线通讯仿真
. net cross platform principle (Part I)
常用SQL语句总结
ASP. NET CORE3. 1. Solution to login failure after identity registers users
How to change input into text
Allowed latency and side output
Conversion between hexadecimal numbers
41. The first missing positive number
Construction of functions in C language programming
How does matlab draw the curve of known formula and how does excel draw the function curve image?
Tdan over half
[batch change MySQL table and corresponding codes of fields in the table]
In ancient Egypt and Greece, what base system was used in mathematics