当前位置:网站首页>A can make large data clustering method of 2000 times faster, don't poke
A can make large data clustering method of 2000 times faster, don't poke
2022-08-10 13:20:00 【Huawei cloud】
一、问题描述
National astronomical observatory has a clustering task:共11份数据,Each data extracted from a photo,包含500多万条记录,Each record is a celestial coordinates and attributes.11张“照片”Some of the celestial coordinates are repeated in,But these repeated coordinates are not identical,They will have some differences but not too far distance.Task is to take one“照片”作为基础,Find duplicate objects from other photos,The repetition of the celestial coordinates and average as the final coordinates, and the object attribute,Is very close to the distance of objects of a class to do aggregation operation,So you can get a clear and coordinate information more accurate object“照片”.
 在这里插入图片描述
在这里插入图片描述 二、问题分析
This task is not complicated,As long as the loop basis each celestial coordinates in the photo,The distance to each celestial coordinates calculation of the other photos,No more than a certain threshold is considered to be the same object,As a kind of,Finally all celestial coordinates calculating mean in each category are the coordinates of the object.
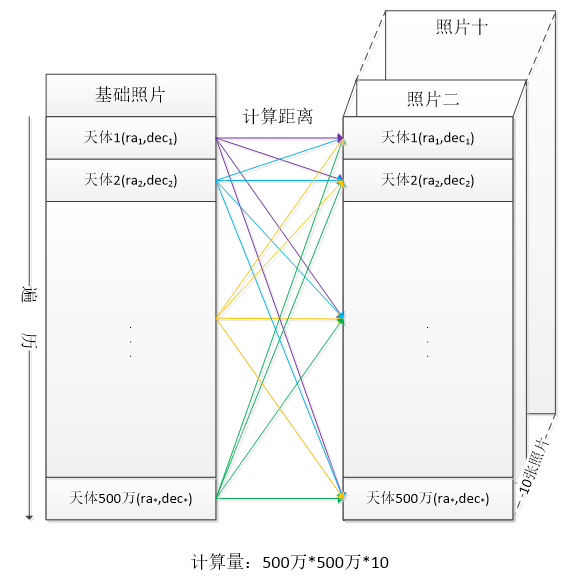
But when I found the task of calculation by computer in computation is amazing,Base photos need cycle500多万次,Each of these celestial coordinates and with other in the photo5000More than a coordinate calculation distance,计算复杂度是500多万*5000多万,This will be an astronomical.
事实也确实如此,在实验阶段,Reduce the amount of data per photo10倍,Namely each photo of celestial coordinates for50万,用PythonWrite code to realize the method to calculate the11Photo of the clustering results need time is6.5天.According to the computational complexity to calculate,500多万的数据量,计算量是50万数据量的100倍,That takes time650天,This must be an unacceptable number.
 在这里插入图片描述
在这里插入图片描述 同样的50万数据量,After being loaded a distributed database withSQL实现,动用了100颗CPU后,跑了3.8Hours to complete the calculation.看起来比Python快了很多倍,但Python的6.5Day is a single thread,细算下来SQLSingle-core performance as wellPython(3.8小时*100>6.5天).Huge resources consumption has been difficult to tolerate,而且计算500When more than the size of, also want to be380小时.
三、解决方案
Let's consider where can be optimized to reduce the amount of calculation.Based the celestial coordinates in the photo is must cycle,In this way can we ensure that each object is used to cluster the,Other pictures of the celestial coordinates need not traverse every time,As long as find a base near the coordinates of the celestial coordinates is ok.This type of search task is very suitable for dichotomy,It can be much less amount of calculation.
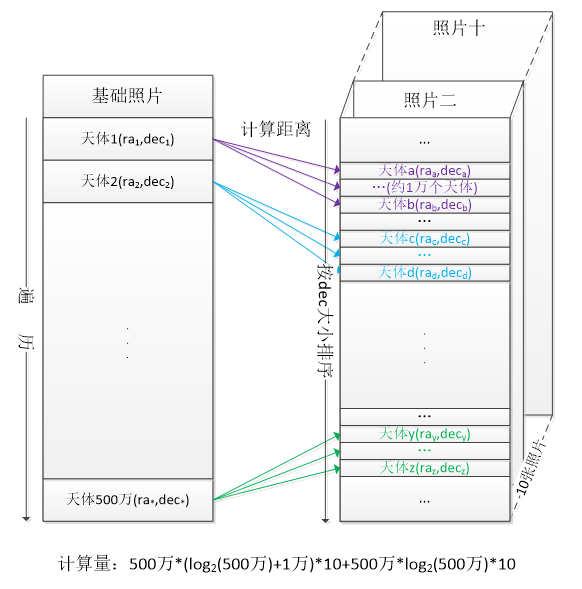
具体过程是这样的:Order of the celestial coordinates of each photo first,Using dichotomy found within the scope of a certain threshold of celestial coordinates,Thus exclude the most heavenly bodies,This is coarse screening process;With basic objects and objects in coarse sieve results calculated distance,To find a qualified result,This is a fine screen process.
 在这里插入图片描述
在这里插入图片描述 To see the screen and fine screen method of computation,10Photo of each sort a,计算量是500万log(500万)10;Dichotomy screen,计算量是500万log(500万)10;Fine screen process,Calculation not sure,但根据经验,Screen after the result is usually not more than1万个,Coarse sieve in the amount of calculationlog(500万)还要再加1万;这样算下来,The total amount of calculation is about500万log(500万)10+500万(log(500万)+1万)10,Compared with the original method,Only one over five hundred of the original amount of calculation.
四、技术选型
方法有了,To select the program tool,Implemented with beforePython,不可否认Python很强大,A framework of the existing system of astronomy calculation,Such as the calculation method of the distance,As long as the call ready-made class library can easily calculate.
但PythonAlso has a very serious disadvantages:
PythonThere are no native dichotomy method,Third-party libraries should combinePandas来完成,Need to do some data transfer during,All of these will bring some unnecessary overhead.
Python的多线程是假多线程,In fact don't support multithreaded parallel,这也是PythonCan't become an important reason this task tools.
关系数据库的SQLAlso unable to efficiently complete.The clustering arithmetic is essentially a non equal join,Database for contour connection can also adoptHASH JOINSuch as optimization scheme to reduce the amount of calculation,But for the equivalent connecting traverse scheme can only be adopted;SQLAlso cannot be achieved in the statement above design process of complex,The monotonicity of the distance can't identify the initiative order and using dichotomy;Plus was supposed to do this kind of mathematical calculation ability is insufficient(Distance calculation involving trigonometric function);In the experimental stage in front of the soSQLSingle-core performance also run butPython的现象.
JavaA high-level language such as though can realize dichotomy,Can also be good parallel,But the code to write lengthy,开发效率过低,Will seriously affect the application of maintainability.
那么,What tools can also be used to complete the task?集算器SPL是个很好的选择,It built in many high performance algorithm(如二分法),也支持多线程并行,Code to write also simple and clear,Also provides a friendly visual debugging mechanism,能有效提高开发效率,And lower maintenance cost.
 在这里插入图片描述
在这里插入图片描述 五、实际效果
相较于Python来说,SPLFor this task to speed up2000倍,Dichotomy to speed up500倍,The multi-thread parallel speed up again4倍(The laptopCPU只有4核),A total of speed2000倍,使用SPL完成500More than the target size of clustering task only need a few hours.
SPLThe code performance not only,And it also is not complicated,The key calculation code as long as23行.
| A | B | C | D | E | |
| 1 | =RThd | /距离阈值 | |||
| 2 | =NJob=4 | /并行线程数 | |||
| 3 | =file("BasePhoto.csv")[email protected]() | ||||
| 4 | [email protected](OtherPhotos) | /Other photos path | |||
| 5 | for A4 | =file(A4)[email protected]() | /Other photos | ||
| 6 | [email protected](OnOrbitDec) | /排序 | |||
| 7 | =B6.min(DEC) | ||||
| 8 | =delta_ra=F(B7,RThd) | /根据DEC算RA阈值 | |||
| 9 | =FK(B5,NJob) | /Data index fragmentation | |||
| 10 | fork B9 | =B5(B10) | /Photo clips | ||
| 11 | for A3 | =C11.OnOrbitDec | /DEC | ||
| 12 | =D11-delta_rad | /DEC下限 | |||
| 13 | =D11+delta_rad | /DEC上限 | |||
| 14 | =C11.RA | /RA | |||
| 15 | =D14-delta_ra | /RA下限 | |||
| 16 | =D14+delta_ra | /RA上限 | |||
| 17 | [email protected]([email protected](OnOrbitDec,D12:D13)) | /二分查找DEC | |||
| 18 | =D17.select(RA>=D10&&RA<=D11) | /查找RA | |||
| 19 | =D36.select(Dis(~,C11)<=A7) | /细筛 | |||
| 20 | if D19!=[] | /合并结果 | |||
| 21 | =FC(C11,D37) | ||||
| 22 | [email protected]|B10 | /汇总结果 | |||
| 23 | =file(OFile)[email protected](B22) | /写出结果 | |||
B10格的forkIs a multithreaded parallel function,Allows section to perform the above algorithm.B6格的[email protected]()Function is parallel sorting method,Large amount of data can improve the efficiency of,The premise of orderly data dichotomy is used.C17格的[email protected](…)Function is a binary search method,Is the key to this task to speed up.
 在这里插入图片描述
在这里插入图片描述 六、后记
Performance optimization problem relies on the high performance algorithm,Only cut down the amount of calculation can effectively improve the efficiency,And the high performance algorithm need to accumulate slowly in the work,Will anyone interested in can come here to study the performance of the commonly used optimization algorithm:Performance optimization algorithm.
High performance algorithm need efficient programming tools to realize,之前已经说过,Python、SQL、javaHas its disadvantages such as language,Or can't parallel,Either implementation difficulties、维护困难.SPLHave enough algorithm underlying support and allows high concurrency,The code can do it very simple,Also provides a friendly visual debugging mechanism,能有效提高开发效率,And lower maintenance cost.
## 七、SPL资料
High performance algorithm need efficient programming tools to realize,之前已经说过,Python、SQL、javaHas its disadvantages such as language,Or can't parallel,Either implementation difficulties、维护困难.SPLHave enough algorithm underlying support and allows high concurrency,The code can do it very simple,Also provides a friendly visual debugging mechanism,能有效提高开发效率,And lower maintenance cost.
边栏推荐
- 教育Codeforces轮41(额定Div。2)大肠Tufurama
- M²BEV: Multi-Camera Joint 3D Detection and Segmentation with Unified Bird’s-Eye View Representation
- C#中导入其它自定义的命名空间
- 九宫格抽奖动效
- Jenkins修改端口号, jenkins容器修改默认端口号
- LeetCode中等题之颠倒字符串中的单词
- MySQL面试题整理
- 大佬们有遇到过这个问题吗? MySQL 2.2 和 2.3-SNAPSHOT 都这样,貌似是
- odps sql 不支持 unsupported feature CREATE TEMPORARY
- 机器学习实战(2)——端到端的机器学习项目
猜你喜欢

shell:常用小工具(sort、uniq、tr、cut)

2022年8月中国数据库排行榜:openGauss重夺榜眼,PolarDB反超人大金仓

海外邮件发送指南(二)

金山云要飘到哪里?

MYSQL误删数据恢复

Redis 定长队列的探索和实践

LeetCode简单题之合并相似的物品
MySQL面试题整理
ABAP 里文件操作涉及到中文字符集的问题和解决方案试读版
![ArcMAP has a problem of -15 and cannot be accessed [Provide your license server administrator with the following information:Err-15]](/img/da/b49d7ba845c351cefc4efc174de995.png)
ArcMAP has a problem of -15 and cannot be accessed [Provide your license server administrator with the following information:Err-15]
随机推荐
交换机的基础知识
矩阵键盘&基于51(UcosII)计算器小项目
Jenkins修改端口号, jenkins容器修改默认端口号
多线程下自旋锁设计基本思想
Codeforces Round #276 (Div. 1) D. Kindergarten
YTU 2295: KMP模式匹配 一(串)
G1和CMS的三色标记法及漏标问题
Network Saboteur
「网络架构」网络代理第一部分: 代理概述
LeetCode中等题之搜索二维矩阵
金山云要飘到哪里?
数字藏品,“赌”字当头
协程与任务
讯飞创意组别 全国选拔赛成绩公布说明
一个 CRM One Order Application log 的单元测试报表
MySQL面试题——MySQL常见查询
jenkins数据迁移和备份
来看Prada大秀吗?在元宇宙里那种!
H264 GOP 扫盲
Twikoo腾讯云函数部署转移到私有部署