当前位置:网站首页>【目标检测】小脚本:提取训练集图片与标签并更新索引
【目标检测】小脚本:提取训练集图片与标签并更新索引
2022-08-10 12:37:00 【zstar-_】
问题场景
在做目标检测任务时,我想提取训练集的图片单独进行外部数据增强。因此,需要根据划分出的train.txt来提取训练集图片与标签。
需求实现
我使用VOC数据集进行测试,实现比较简单。
import shutil
if __name__ == '__main__':
img_src = r"D:\Dataset\VOC2007\images"
xml_src = r"D:\Dataset\VOC2007\Annotations"
img_out = "image_out/"
xml_out = "xml_out/"
txt_path = r"D:\Dataset\VOC2007\ImageSets\Segmentation\train.txt"
# 读取txt文件
with open(txt_path, 'r') as f:
line_list = f.readlines()
for line in line_list:
line_new = line.replace('\n', '') # 将换行符替换为空('')
shutil.copy(img_src + '/' + line_new + ".jpg", img_out)
shutil.copy(xml_src + '/' + line_new + ".xml", xml_out)
效果: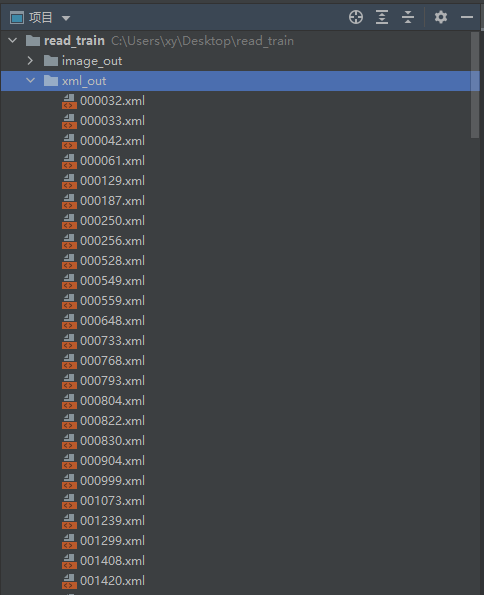
更新训练集索引
使用数据增强之后,把生成的图片和标签丢到VOC里面,混在一起。

然后再写个脚本,将生成好的图片名称添加到train.txt文件中。
import os
if __name__ == '__main__':
xml_src = r"C:\Users\xy\Desktop\read_train\xml_out_af"
txt_path = r"D:\Dataset\VOC2007\ImageSets\Segmentation\train.txt"
for name in os.listdir(xml_src):
with open(txt_path, 'a') as f:
f.write(name[:-4] + "\n")
效果: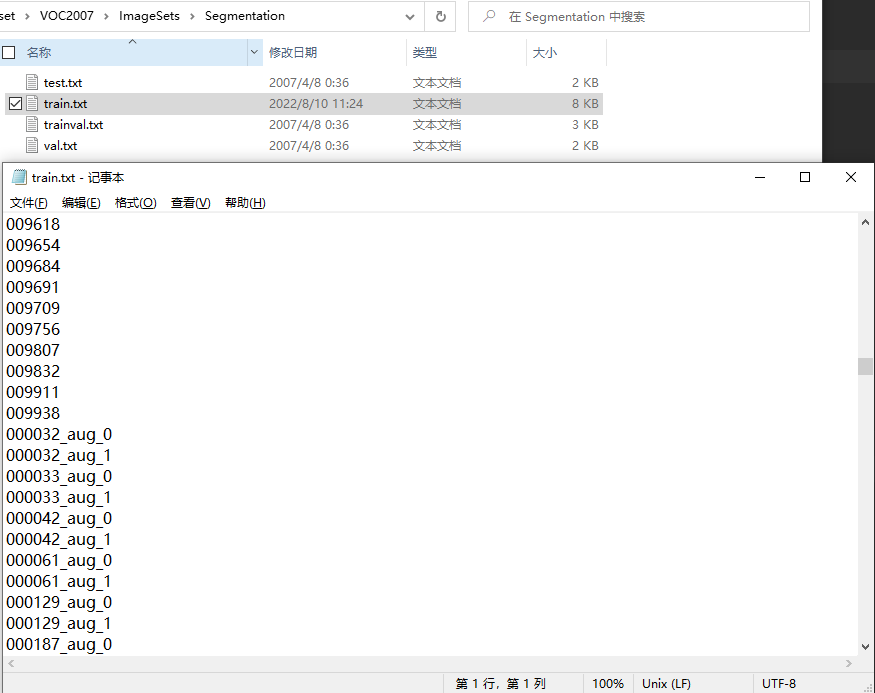
最后,再运行之前在VOC博文里面写过的xml2txt脚本:
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets = ['train', 'test', 'val']
Imgpath = r'D:\Dataset\VOC2007\images' # 图片文件夹
xmlfilepath = r'D:\Dataset\VOC2007\Annotations' # xml文件存放地址
ImageSets_path = r'D:\Dataset\VOC2007\ImageSets\Segmentation'
Label_path = r'D:\Dataset\VOC2007'
classes = ['aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog',
'horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor']
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open(xmlfilepath + '/%s.xml' % (image_id))
out_file = open(Label_path + '/labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
for image_set in sets:
if not os.path.exists(Label_path + 'labels/'):
os.makedirs(Label_path + 'labels/')
image_ids = open(ImageSets_path + '/%s.txt' % (image_set)).read().strip().split()
list_file = open(Label_path + '%s.txt' % (image_set), 'w')
for image_id in image_ids:
# print(image_id) # DJI_0013_00360
list_file.write(Imgpath + '/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()
运行之后,就可以看到生成的数据增强样本被完美得添加到了原始数据集中。
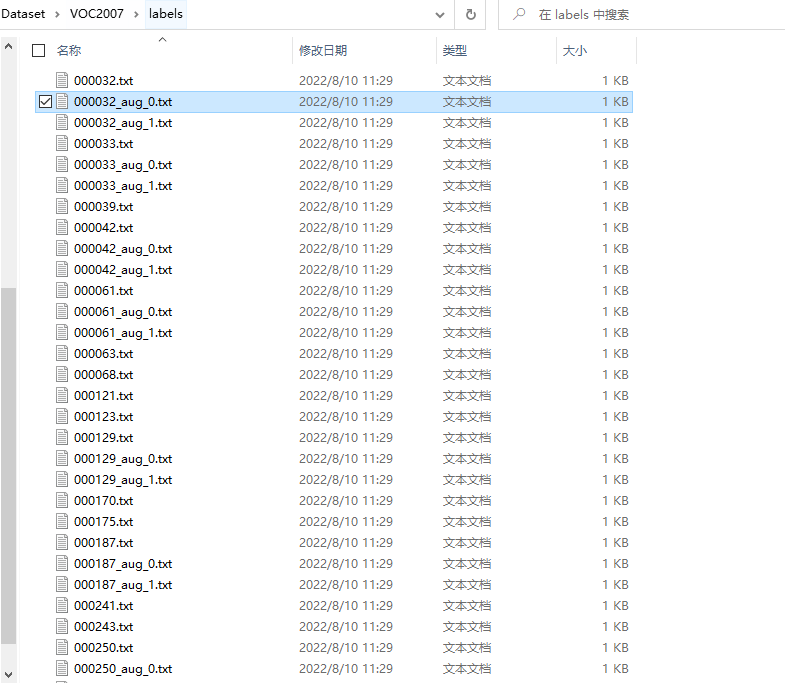
边栏推荐
- ASP.NET Core依赖注入系统学习教程:ServiceDescriptor(服务注册描述类型)
- Jenkins修改默认主目录
- ABAP 里文件操作涉及到中文字符集的问题和解决方案试读版
- Reversing words in a string in LeetCode
- Solution for "Certificate not valid for requested usage" after Digicert EV certificate signing
- LeetCode中等题之比较版本号
- 【论文+代码】PEBAL/Pixel-wise Energy-biased Abstention Learning for Anomaly Segmentation on Complex Urban Driving Scenes(复杂城市驾驶场景异常分割的像素级能量偏置弃权学习)
- 一种能让大型数据聚类快2000倍的方法,真不戳
- 2022年8月中国数据库排行榜:openGauss重夺榜眼,PolarDB反超人大金仓
- 11 + chrome advanced debugging skills, learn to direct efficiency increases by 666%
猜你喜欢

Open Office XML 格式里如何描述多段具有不同字体设置的段落

LeetCode简单题之合并相似的物品

Comparison version number of middle questions in LeetCode
百度用户产品流批一体的实时数仓实践

九宫格抽奖动效

LeetCode·每日一题·640.求解方程·模拟构造
3DS MAX 批量导出文件脚本 MAXScript 带界面

LeetCode中等题之颠倒字符串中的单词
3DS MAX batch export file script MAXScript with interface

BEVDet4D: Exploit Temporal Cues in Multi-camera 3D Object Detection Paper Notes
随机推荐
bgp dual plane experiment routing strategy to control traffic
Digicert EV证书签名后出现“证书对于请求用法无效”的解决方案
AICOCO AI Frontier Promotion (8.10)
生成树协议STP(Spanning Tree Protocol)
“68道 Redis+168道 MySQL”精品面试题(带解析)
娄底干细胞制备实验室建设须知要求
22家!北京昌平区通报存在食品安全问题餐饮服务企业
【mysql索引实现原理】
jenkins数据迁移和备份
Codeforces Round #276 (Div. 1) B. Maximum Value
phpstrom 快速注释:
Keithley DMM7510 accurate measurement of ultra-low power consumption equipment all kinds of operation mode power consumption
Efficient and Robust 2D-to-BEV Representation Learning via Geometry-guided Kernel Transformer 论文笔记
ABAP 里文件操作涉及到中文字符集的问题和解决方案试读版
sprintboot项目通过interceptor和filter实现接入授权控制
shell:常用小工具(sort、uniq、tr、cut)
M²BEV: Multi-Camera Joint 3D Detection and Segmentation with Unified Bird’s-Eye View Representation
LeetCode中等题之比较版本号
Solution for "Certificate not valid for requested usage" after Digicert EV certificate signing
47Haproxy Cluster