当前位置:网站首页>[text classification cases] (4) RNN and LSTM film evaluation Tendency Classification, with tensorflow complete code attached
[text classification cases] (4) RNN and LSTM film evaluation Tendency Classification, with tensorflow complete code attached
2022-04-23 19:46:00 【Vertical sir】
Hello everyone , Today, I'd like to share with you how to use the RNN and LSTM Methods complete the classification of film review tendency . The data set is explained below :https://blog.csdn.net/qq_23869697/article/details/86505343
1. RNN Method
this 2 The two methods of recurrent neural network have little difference in the code , I'll elaborate here RNN The specific operation method of , sketch LSTM stay RNN Improvement on the basis of .
1.1 Import toolkit
I use GPU Accelerate neural network computing , If it is CPU Calculation , Just set it below GPU Delete the set code .
import time
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore')
# call GPU Speed up
gpus = tf.config.experimental.list_physical_devices(device_type='GPU')
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
1.2 Get data set
Use keras Built in imdb Review data set . Considering the large number of words , To simplify the computational complexity , Only right 10000 Code one common word by one , Use unified symbols for other rare words , The influence of rare words on the training results is not great .
Besides , because The sentence length of each film review is inconsistent , and The input of the network is to try to tensor Of shape coincident , So set The length of film reviews is unified as 80, That is less than 80 The film review of words passed 0 Fill to length 80, More than 80 Only take the first word of a sentence 80 Word .
#(1) Import movie evaluation data
# Code only common words , Number 1w individual , Rare words are represented by unified symbols
total_words = 10000
# x Comments on behalf of users ,y Represents good or bad comments ,
(x_train, y_train), (x_test, y_test) = keras.datasets.imdb.load_data(num_words=total_words)
# Set the length of each sentence , The sentence length of the unified input network model
# After processing the shape by [b,80], Yes b One sentence, each sentence has 80 Word
max_review_len = 80
# Make the length less than 80 Fill in with sentences , Length greater than 80 Sentence truncation
x_train = keras.preprocessing.sequence.pad_sequences(x_train, maxlen=max_review_len)
x_test = keras.preprocessing.sequence.pad_sequences(x_test, maxlen=max_review_len)
The parameters and return values of the sequence preprocessing function are as follows
keras.preprocessing.sequence.pad_sequences()
'''
Parameters
sequences: A two-tier nested list of floating-point numbers or integers
maxlen:None Or integer , Is the maximum length of the sequence . Longer than this length will be truncated , Sequences less than this length will be filled in later 0.
dtype: Back to numpy array Data type of .
padding:pre or post, Be sure to make up for 0 when , At the beginning or the end of the sequence .
truncating:pre or post, When determining that the sequence needs to be truncated , Cut from the beginning or the end .
value: Floating point numbers , Used to fill the sequence .
Return value :2 D tensor , The length is maxlen
'''1.3 Construct data set
Here's to say drop_remainder This parameter . because The total number of data sets may not be batchsize=128 to be divisible by , So the last one batch It often contains less data than 128 individual . However What the network wants to input is fixed shape, So you need to delete the last batch, So that everyone in training step The number of training data is consistent .
For training set data Random disruption shuffle(), Avoid chance , And there's no need to disrupt the test set . After constructing the dataset , Use iterator iter() combination next() function , Take one out of the training set batch The data of , Check the divided shape
#(2) Construct data set
batchsz = 128 # Every batch Handle 128 A sentence
db_train = tf.data.Dataset.from_tensor_slices((x_train, y_train)) # Training set
# Disrupt the training set , And set each step Training 128 A sentence , And will eventually be insufficient 128 the batch Delete
db_train = db_train.shuffle(1000).batch(batchsz, drop_remainder=True)
db_test = tf.data.Dataset.from_tensor_slices((x_test, y_test)) # Test set
# Will be the last batch The size is less than batchsize The deletion of
db_test = db_test.batch(batchsz, drop_remainder=True)
# View dataset information
sample = next(iter(db_train)) # Take out a batch Training set of
print('x_train.shape:', sample[0].shape) # (128,80)
print('y_train.shape:', sample[1].shape) # (128,)
1.4 Network construction
In order to make it easy for you to understand , Build a two-tier RNN The Internet .
One RNN Calculation formula of element by :  ,
,
among  representative Input of current time ,
representative Input of current time , representative Contextual information of the last moment ,
representative Contextual information of the last moment , representative The output result of the current time ,
representative The output result of the current time , Represents the weight item ,
 It's a nonlinear activation function .
It's a nonlinear activation function .

for instance , In a certain RNN In the unit , One word input , The word needs to integrate all the contextual information in front of the sentence , After calculation, we get an output , This output will perform the same calculation as the next input word , Until all the words in each sentence are processed , The final output is the meaning of the whole sentence .
(1) initialization
First build a RNN class , To initialize .self.stage representative RNN The contextual information at the beginning of the unit 
# Create a RNN Class , Inherit keras.Model Parent class
class MyRNN(keras.Model):
# initialization
def __init__(self, units):
# Call the initialization method of the parent class
super(MyRNN, self).__init__()
# Assignment properties
# Initialize each RNN The state of the unit , b A sentence of units All word components are initialized to 0
self.stage0 = [tf.zeros([batchsz, units])]
# the second RNN Initialization status of the unit
self.stage1 = [tf.zeros([batchsz, units])]
'''
Embedding It is mainly used to convert a feature into a vector . It can only be used as the first layer of the model
similar one-hot code , But in practice , Convert the feature to one-hot After coding, the dimension will be very high .
So we will transform sparse features into dense features , The usual practice is to use Embedding.
'''
# Encode text with numeric values [b,80]==>[b,80,100]
# Only right 10000 A common word code , Use one for each word 100 The vector representation of dimensions , The input sentence length is processed into 80
self.embedding = layers.Embedding(10000, 100, input_length=80)
# first floor RNN unit , Expand each word , That is to say axis=1 Expand on dimension
# [b, 80, 100] ==> [b, units]
self.rnn_cell0 = layers.SimpleRNNCell(units, dropout=0.2) # Enter the number of neurons
# the second RNN unit , Strengthen feature extraction
self.rnn_cell1 = layers.SimpleRNNCell(units, dropout=0.2)
# Full connection layer classification
# [b, 64]==>[b, 1]
self.outlayer = layers.Dense(1)(2) Forward propagation
Every word goes through two RNN unit , It can be understood as , The first layer is used to extract whether the word is a commendatory word or a derogatory word , The second layer is used to extract the emotional information contained in the word more deeply .
Here we need to pay attention to a parameter training, because The processing methods of some layers in the model training process and testing process are different , Such as dropout layer , In the training phase, we hope to kill neurons randomly to prevent overfitting , In the testing phase, I hope to get more information , You don't have to kill neurons .
Forward propagating code is in MyRNN Inside the class .
# Define the forward propagation method
def call(self, inputs, training=None):
'''
inputs: do embedding The previous sentence shape=[b,80]
training: Is it the training phase or the testing phase , Some layers are different, such as dropout It works during layer training , It doesn't work during the test
'''
x = inputs # Get the network input size x_train
# embedding Layer word encoding processing
x = self.embedding(x) # [b,80]==>[b,80,100]
# Receive initial RNN The state component of the unit
stage0 = self.stage0 # first floor RNN The state of the unit
stage1 = self.stage1 # The second floor RNN The state of the unit
# after RNN layer [b,80,100]==>[b,units]
# In the time dimension axis=1 Upper deployment , Unfold into 80 individual
for word in tf.unstack(x, axis=1): # word:[b,100] Express , The first word , stay b In one sentence , The word is used 100 Vector representation of dimensions
# Send each word to RNN In the unit
'''
out, ht = Xt * Wxh + h(t-1) * Whh
Xt Words representing the current stage ,h(t-1) Represents the contextual state of the previous stage
out Represents the current stage RNN The output of the cell , ht The results of the current stage are transmitted to the next stage as early warning information
'''
# Pass in RNN Whether the unit is a training or testing phase , Yes dropout Different treatment
# After calculation, update the context information used in the next cycle
out0, stage0 = self.rnn_cell0(word, stage0, training)
# Pass the output result of the first layer to the second layer RNN unit
out1, stage1 = self.rnn_cell1(out0, stage1, training)
# The final output tensor Of shape=[b,64], At this time stage0 It's been aggregated before 80 Word information
# Full connection layer classification [b,64]==>[b,1]
x = self.outlayer(out1)
# after sigmoid Function output probability
prob = tf.sigmoid(x)
return prob1.5 Network training
Next, train the network , Set up Adam The learning rate of the optimizer 0.01, because The positive and negative comments of the target value are in 0 and 1 To represent the , Therefore, this case is a binary classification problem , Use Binary cross entropy loss .
#(4) Network training
units = 64 # RNN Number of neurons per unit
epochs = 10 # Network training 10 Time
t0 = time.time() # Start time before training
# Receiving model
model = MyRNN(units)
# Network compilation
model.compile(optimizer=keras.optimizers.Adam(0.001), # Adam Optimizer , To study the 0.01
loss = tf.losses.BinaryCrossentropy(), # Two classification cross entropy loss
metrics=['accuracy']) # Accuracy monitoring indicators
# Network training
history = model.fit(db_train, epochs=epochs, validation_data=db_test)
t1 = time.time() # Record the time spent training
print(' Total time :', t1-t0)The training process is as follows :
Epoch 1/10
195/195 [==============================] - 26s 118ms/step - loss: 0.6318 - accuracy: 0.6034 - val_loss: 0.3870 - val_accuracy: 0.8289
Epoch 2/10
195/195 [==============================] - 22s 115ms/step - loss: 0.3429 - accuracy: 0.8506 - val_loss: 0.4200 - val_accuracy: 0.8308
---------------------------------------------------
---------------------------------------------------
Epoch 9/10
195/195 [==============================] - 22s 112ms/step - loss: 0.0285 - accuracy: 0.9897 - val_loss: 0.9732 - val_accuracy: 0.8100
Epoch 10/10
195/195 [==============================] - 21s 110ms/step - loss: 0.0804 - accuracy: 0.9721 - val_loss: 0.8530 - val_accuracy: 0.78411.6 Test set validation
Use evaluate() Function evaluation test set , View the accuracy and loss of the entire dataset
#(5) Test set evaluation
model.evaluate(db_test)195/195 [==============================] - 6s 30ms/step - loss: 0.8530 - accuracy: 0.78411.7 Visualization of training process
Use RNN It is easy to appear the phenomenon of gradient dispersion and gradient explosion , It needs to be adjusted slowly
#(6) Get training information
history_dict = history.history # Get the training data dictionary
train_loss = history_dict['loss'] # Training set loss
train_accuracy = history_dict['accuracy'] # Training set accuracy
val_loss = history_dict['val_loss'] # Verification set loss
val_accuracy = history_dict['val_accuracy'] # Verification set accuracy
#(7) Draw training loss and verification loss
plt.figure()
plt.plot(range(epochs), train_loss, label='train_loss') # Training set loss
plt.plot(range(epochs), val_loss, label='val_loss') # Verification set loss
plt.legend() # Show labels
plt.xlabel('epochs')
plt.ylabel('loss')
#(8) The accuracy of drawing training set and verification set
plt.figure()
plt.plot(range(epochs), train_accuracy, label='train_accuracy') # Training set accuracy
plt.plot(range(epochs), val_accuracy, label='val_accuracy') # Verification set accuracy
plt.legend()
plt.xlabel('epochs')
plt.ylabel('accuracy')
2. LSTM
2.1 Method introduction
For the traditional RNN The Internet , Its memory time is very short , Although the setting is to let the network remember the contextual information of all words , But in fact, you can only remember the context of the most recent relevant words .LSTM Not only did it solve RNN The problem of gradient discretization , It also solves the problem of memory time .
LSTM The structure is as follows , Can be understood as , The contextual information of the last moment , Input information of the current time , Before entering the network layer , There is a gate to deal with them , When the calculation is done , For output results , There is also a gate to handle .

there The gate is sigmoid function , Limit output to 0 To 1 Between .LSTM There is one more information about the past in the , be called  . The context of the last moment , Input information of the current time , Obtained after calculation
. The context of the last moment , Input information of the current time , Obtained after calculation  . The result of the calculation is Multiply by past information , Plus the filtered new input information , Get the updated... At the current time
. The result of the calculation is Multiply by past information , Plus the filtered new input information , Get the updated... At the current time  .LSTM It mainly filters information and updates the past context through the gate , The detailed principle will be explained in the next chapter , This article is mainly about the code .
.LSTM It mainly filters information and updates the past context through the gate , The detailed principle will be explained in the next chapter , This article is mainly about the code .
2.2 Code display
(1) Change part
In the code ,LSTM Compared with the above RNN, Only need to layers.SimpleRNNCell() Change to layers.LSTMCell() .
# first floor LSTM unit , Expand each word , That is to say axis=1 Expand on dimension
# [b, 80, 100] ==> [b, units]
self.rnn_cell0 = layers.LSTMCell(units, dropout=0.2) # Enter the number of neurons
# the second LSTM unit , Strengthen feature extraction
self.rnn_cell1 = layers.LSTMCell(units, dropout=0.2) Then you need to increase the initialization status ,RNN Just the context information of the last moment use 0 initialization , and LSTM Than RNN One more message from the old moment , This quantity is also 0 initialization .
# Assignment properties
# Initialize each RNN The state of the unit , b A sentence of units All word components are initialized to 0, The first piece of information is the old one 0
self.stage0 = [tf.zeros([batchsz, units]), tf.zeros([batchsz, units])] # Both are 0 Initialization amount of , representative c and h
# the second RNN Initialization status of the unit
self.stage1 = [tf.zeros([batchsz, units]), tf.zeros([batchsz, units])]
(2) Network training
Other parts and RNN Are all the same , Don't repeat .
import time
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore')
# call GPU Speed up
gpus = tf.config.experimental.list_physical_devices(device_type='GPU')
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
#(1) Import movie evaluation data
# Code only common words , Number 1w individual , Rare words are represented by unified symbols
total_words = 10000
# x Comments on behalf of users ,y Represents good or bad comments ,
(x_train, y_train), (x_test, y_test) = keras.datasets.imdb.load_data(num_words=total_words)
# Set the length of each sentence , The sentence length of the unified input network model
# After processing the shape by [b,80], Yes b One sentence, each sentence has 80 Word
max_review_len = 80
# Make the length less than 80 Fill in with sentences , Length greater than 80 Sentence truncation
x_train = keras.preprocessing.sequence.pad_sequences(x_train, maxlen=max_review_len)
x_test = keras.preprocessing.sequence.pad_sequences(x_test, maxlen=max_review_len)
'''
Parameters
sequences: A two-tier nested list of floating-point numbers or integers
maxlen:None Or integer , Is the maximum length of the sequence . Longer than this length will be truncated , Sequences less than this length will be filled in later 0.
dtype: Back to numpy array Data type of .
padding:pre or post, Be sure to make up for 0 when , At the beginning or the end of the sequence .
truncating:pre or post, When determining that the sequence needs to be truncated , Cut from the beginning or the end .
value: Floating point numbers , Used to fill the sequence .
Return value :2 D tensor , The length is maxlen
'''
#(2) Construct data set
''' The input of the network is expected to be fixed shape, When the last batch Less than batchsize, Delete it '''
batchsz = 128 # Every batch Handle 128 A sentence
db_train = tf.data.Dataset.from_tensor_slices((x_train, y_train)) # Training set
# Disrupt the training set , And set each step Training 128 A sentence , And will eventually be insufficient 128 the batch Delete
db_train = db_train.shuffle(1000).batch(batchsz, drop_remainder=True)
db_test = tf.data.Dataset.from_tensor_slices((x_test, y_test)) # Test set
# Will be the last batch The size is less than batchsize The deletion of
db_test = db_test.batch(batchsz, drop_remainder=True)
# View dataset information
sample = next(iter(db_train)) # Take out a batch Training set of
print('x_train.shape:', sample[0].shape) # (128,80)
print('y_train.shape:', sample[1].shape) # (128,)
#(3) structure RNN A network model
# Create a RNN Class , Inherit keras.Model Parent class
class MyRNN(keras.Model):
# initialization
def __init__(self, units):
# Call the initialization method of the parent class
super(MyRNN, self).__init__()
# Assignment properties
# Initialize each RNN The state of the unit , b A sentence of units All word components are initialized to 0, The first piece of information is the old one 0
self.stage0 = [tf.zeros([batchsz, units]), tf.zeros([batchsz, units])] # Both are 0 Initialization amount of , representative c and h
# the second RNN Initialization status of the unit
self.stage1 = [tf.zeros([batchsz, units]), tf.zeros([batchsz, units])]
'''
Embedding It is mainly used to convert a feature into a vector . It can only be used as the first layer of the model
similar one-hot code , But in practice , Convert the feature to one-hot After coding, the dimension will be very high .
So we will transform sparse features into dense features , The usual practice is to use Embedding.
'''
# Encode text with numeric values [b,80]==>[b,80,100]
# Only right 10000 A common word code , Use one for each word 100 The vector representation of dimensions , The input sentence length is processed into 80
self.embedding = layers.Embedding(10000, 100, input_length=80)
# first floor LSTM unit , Expand each word , That is to say axis=1 Expand on dimension
# [b, 80, 100] ==> [b, units]
self.rnn_cell0 = layers.LSTMCell(units, dropout=0.2) # Enter the number of neurons
# the second LSTM unit , Strengthen feature extraction
self.rnn_cell1 = layers.LSTMCell(units, dropout=0.2)
# Full connection layer classification
# [b, 64]==>[b, 1]
self.outlayer = layers.Dense(1)
# Define the forward propagation method
def call(self, inputs, training=None):
'''
inputs: do embedding The previous sentence shape=[b,80]
training: Is it the training phase or the testing phase , Some layers are different, such as dropout It works during layer training , It doesn't work during the test
'''
x = inputs # Get the network input size x_train
# embedding Layer word encoding processing
x = self.embedding(x) # [b,80]==>[b,80,100]
# Receive initial RNN The state component of the unit
stage0 = self.stage0 # first floor RNN The state of the unit
stage1 = self.stage1 # The second floor RNN The state of the unit
# after RNN layer [b,80,100]==>[b,units]
# In the time dimension axis=1 Upper deployment , Unfold into 80 individual
for word in tf.unstack(x, axis=1): # word:[b,100] Express , The first word , stay b In one sentence , The word is used 100 Vector representation of dimensions
# Send each word to RNN In the unit
'''
out, ht = Xt * Wxh + h(t-1) * Whh
Xt Words representing the current stage ,h(t-1) Represents the contextual state of the previous stage
out Represents the current stage RNN The output of the cell , ht The results of the current stage are transmitted to the next stage as early warning information
'''
# Pass in RNN Whether the unit is a training or testing phase , Yes dropout Different treatment
# After calculation, update the context information used in the next cycle
out0, stage0 = self.rnn_cell0(word, stage0, training)
# Pass the output result of the first layer to the second layer RNN unit
out1, stage1 = self.rnn_cell1(out0, stage1, training)
# The final output tensor Of shape=[b,64], At this time stage0 It's been aggregated before 80 Word information
# Full connection layer classification [b,64]==>[b,1]
x = self.outlayer(out1)
# after sigmoid Function output probability
prob = tf.sigmoid(x)
return prob
#(4) Network training
units = 64 # RNN Number of neurons per unit
epochs = 10 # Network training 10 Time
t0 = time.time() # Start time before training
# Receiving model
model = MyRNN(units)
# Network compilation
model.compile(optimizer=keras.optimizers.Adam(0.001), # Adam Optimizer , To study the 0.01
loss = tf.losses.BinaryCrossentropy(), # Two classification cross entropy loss
metrics=['accuracy']) # Accuracy monitoring indicators
# Network training
history = model.fit(db_train, epochs=epochs, validation_data=db_test)
t1 = time.time() # Record the time spent training
print(' Total time :', t1-t0)Check out the training process
Epoch 1/10
195/195 [==============================] - 63s 286ms/step - loss: 0.5425 - accuracy: 0.7036 - val_loss: 0.3783 - val_accuracy: 0.8317
Epoch 2/10
195/195 [==============================] - 53s 275ms/step - loss: 0.3030 - accuracy: 0.8735 - val_loss: 0.3891 - val_accuracy: 0.8333
------------------------------------------------
------------------------------------------------
Epoch 9/10
195/195 [==============================] - 53s 271ms/step - loss: 0.0785 - accuracy: 0.9731 - val_loss: 0.8818 - val_accuracy: 0.8058
Epoch 10/10
195/195 [==============================] - 53s 272ms/step - loss: 0.0592 - accuracy: 0.9813 - val_loss: 0.8983 - val_accuracy: 0.8060(3) Model evaluation
First, check the evaluation indicators of the whole test set , Loss value and accuracy .
#(5) Test set evaluation
model.evaluate(db_test)
195/195 [==============================] - 14s 72ms/step - loss: 0.8983 - accuracy: 0.8060history All the information of the training stage is saved in the variable , Draw the loss and accuracy curve in the training stage .
#(6) Draw a training curve
history_dict = history.history # Get the training data dictionary
train_loss = history_dict['loss'] # Training set loss
train_accuracy = history_dict['accuracy'] # Training set accuracy
val_loss = history_dict['val_loss'] # Verification set loss
val_accuracy = history_dict['val_accuracy'] # Verification set accuracy
#(7) Draw training loss and verification loss
plt.figure()
plt.plot(range(epochs), train_loss, label='train_loss') # Training set loss
plt.plot(range(epochs), val_loss, label='val_loss') # Verification set loss
plt.legend() # Show labels
plt.xlabel('epochs')
plt.ylabel('loss')
#(8) The accuracy of drawing training set and verification set
plt.figure()
plt.plot(range(epochs), train_accuracy, label='train_accuracy') # Training set accuracy
plt.plot(range(epochs), val_accuracy, label='val_accuracy') # Verification set accuracy
plt.legend()
plt.xlabel('epochs')
plt.ylabel('accuracy')
版权声明
本文为[Vertical sir]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204231930160097.html
边栏推荐
- [webrtc] add x264 encoder for CEF / Chromium
- 高效的串口循环Buffer接收处理思路及代码2
- Possible root causes include a too low setting for -Xss and illegal cyclic inheritance dependencies
- Kubernetes entry to mastery - bare metal loadbalance 80 443 port exposure precautions
- 命令-sudo
- Esp8266 - beginner level Chapter 1
- 【webrtc】Add x264 encoder for CEF/Chromium
- OpenHarmony开源开发者成长计划,寻找改变世界的开源新生力!
- Kubernetes introduction to mastery - ktconnect (full name: kubernetes toolkit connect) is a small tool based on kubernetes environment to improve the efficiency of local test joint debugging.
- An example of using JNI to directly access surface data
猜你喜欢

The textarea cursor cannot be controlled by the keyboard due to antd dropdown + modal + textarea
PHP reference manual string (7.2000 words)

@MapperScan与@Mapper
Prefer composition to inheritance
2021-2022-2 ACM training team weekly Programming Competition (8) problem solution

Lottery applet, mother no longer have to worry about who does the dishes (assign tasks), so easy
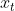
【文本分类案例】(4) RNN、LSTM 电影评价倾向分类,附TensorFlow完整代码
php参考手册String(7.2千字)
![[report] Microsoft: application of deep learning methods in speech enhancement](/img/c1/7bffbcecababf8dabf86bd34ab1809.png)
[report] Microsoft: application of deep learning methods in speech enhancement

山大网安靶场实验平台项目-个人记录(五)
随机推荐
Mysql database - connection query
MySQL 进阶 锁 -- MySQL锁概述、MySQL锁的分类:全局锁(数据备份)、表级锁(表共享读锁、表独占写锁、元数据锁、意向锁)、行级锁(行锁、间隙锁、临键锁)
filebeat、logstash配置安装
First experience of using fluent canvas
Building googlenet neural network based on pytorch for flower recognition
The textarea cursor cannot be controlled by the keyboard due to antd dropdown + modal + textarea
Software College of Shandong University Project Training - Innovation Training - network security shooting range experimental platform (8)
Project training of Software College of Shandong University - Innovation Training - network security shooting range experimental platform (VII)
音频编辑生成软件
山东大学软件学院项目实训-创新实训-网络安全靶场实验平台(八)
Kubernetes getting started to proficient - install openelb on kubernetes
A brief explanation of golang's keyword "competence"
Go modules daily use
Openharmony open source developer growth plan, looking for new open source forces that change the world!
Mfcc: Mel frequency cepstrum coefficient calculation of perceived frequency and actual frequency conversion
Command - sudo
NiO related Basics
C语言的十六进制printf为何输出有时候输出带0xFF有时没有
Strange passion
Kubernetes entry to mastery - bare metal loadbalance 80 443 port exposure precautions