当前位置:网站首页>NiO related Basics
NiO related Basics
2022-04-23 19:16:00 【Li Siwei】
from :NIO Related basic part
User space and kernel space concepts
We know that the operating system now uses virtual memory , So right. 32 Bit operating system , Its addressing space ( Virtual storage space ) by 4G(2 Of 32 Power ).
At the heart of the system is the kernel , Independent of ordinary applications , Access to protected memory space , You also have all access to the underlying hardware devices .( The kernel is also an application , That is, the operating system application , It starts one or more processes , Each process of the kernel also has its own memory space . User processes can call... By calling the system , Call the service provided by the kernel process , Get kernel space data )
To ensure that the user process cannot directly operate the kernel , Keep the kernel safe , Worry system divides the virtual space into two parts , Part of it is kernel space , Part of it is user space . in the light of linux In terms of operating system , Will be the highest 1G byte ( From virtual address 0xC0000000 To 0xFFFFFFFF), For kernel use , It's called kernel space , And the lower 3G byte ( From virtual address 0x00000000 To 0xBFFFFFFF), For each process , It's called user space . Each process can enter the kernel through a system call , therefore ,Linux The kernel is shared by all processes in the system . therefore , From the perspective of the specific process , Each process can have 4G Bytes of virtual space .
User process IO
in order to OS The security and so on , User processes cannot be operated directly I/O The equipment , It must be assisted by a system call request kernel I/O action , And the kernel will be for each I/O Equipment maintenance one buffer.
Linux Treat all peripherals as files , When the user process needs to configure the external device IO when , Initiate a system call to the kernel , The kernel will return a buffer to the user process IO The address index of the kernel buffer of the data , Because the kernel treats peripherals as files , This buffer index is called a file descriptor (File Descriptor)- Shorthand for fd.
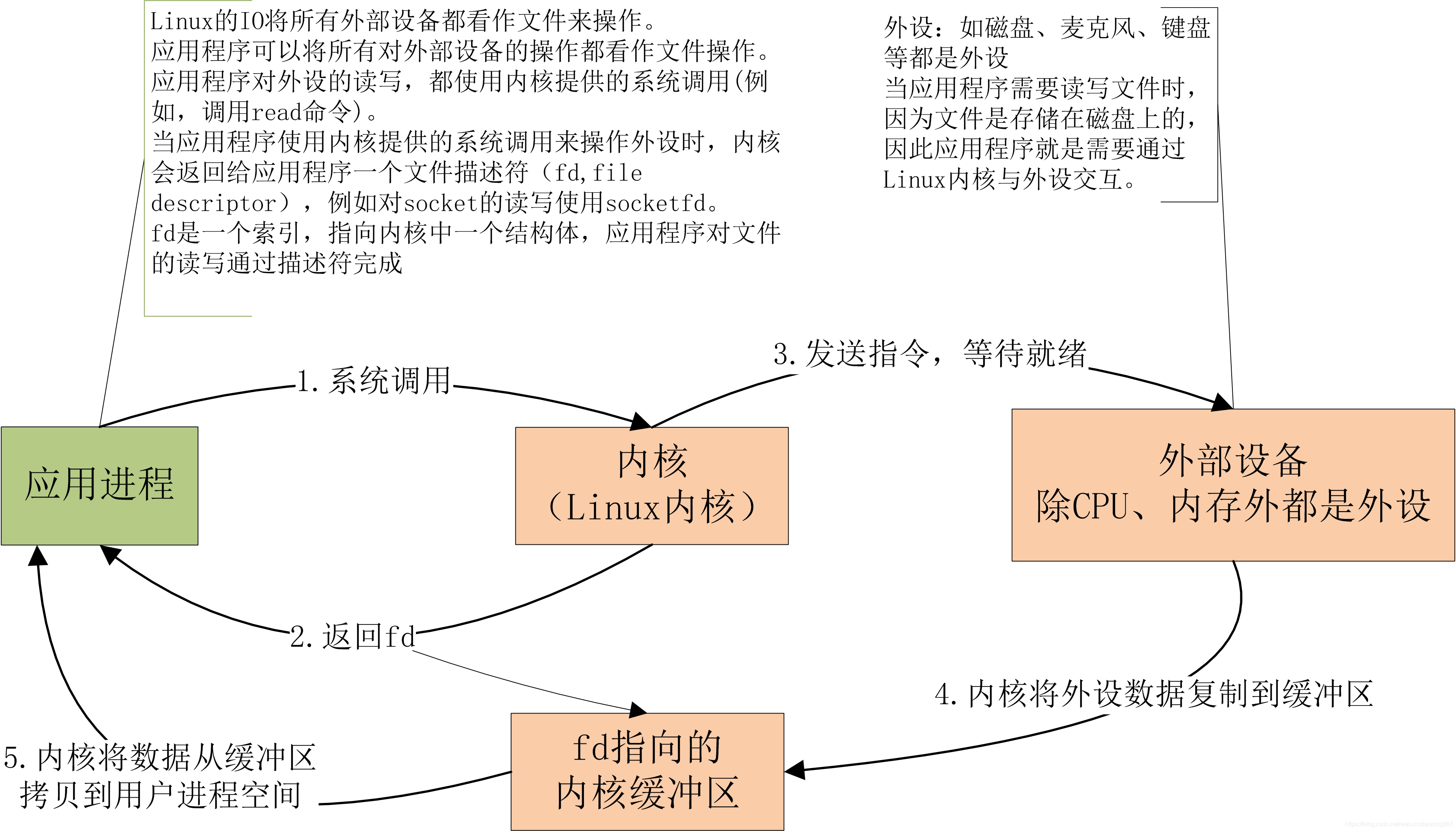
The whole request process is : User process initiates request , After the kernel receives the request , from I/O Get data from the device to buffer in , then buffer Data in copy To the address space of the user process , The user process obtains the data and then responds to the client .
During the entire request process , Data input to buffer It takes time to , And from buffer It also takes time to copy data to the process . So depending on how you wait in these two periods ,I/O Actions can be divided into the following five modes :
- Blocking I/O (Blocking I/O)
- Non blocking I/O (Non-Blocking I/O)
- I/O Reuse (I/O Multiplexing)
- Signal driven I/O (Signal Driven I/O)
- asynchronous I/O (Asynchrnous I/O)
explain : If you want to know more, you may need linux/unix Knowledge of aspects of , There should be some detailed principles of network programming , But for most java For the programmer , You don't need to know the underlying details , Just know a concept , Knowing that for the system , The bottom is supportive .
Generally, the process of inputting data into the kernel buffer is called waiting for data preparation , Another process that may take a long time and cause blocking is to copy the data from the kernel buffer to the user process space .
Blocking IO

When the user process calls recvfrom This system call , The kernel starts IO The first stage of : Wait for the data to be ready . about network io Come on , Many times the data hasn't arrived at the beginning ( such as , I haven't received a complete UDP package ), At this time, the kernel has to wait for enough data to arrive . On the user process side , The whole process will be blocked . When the kernel waits until the data is ready , It will copy the data from the kernel to user memory , Then the kernel returns the result , The user process is released block The state of , Run it again .
therefore ,blocking IO It is characterized by IO Both phases of implementation are block 了 .
Non blocking IO
stay linux Next , Can be set by socket Turn it into non-blocking, When it comes to such socket When reading , The process is as follows :
When the user process calls recvfrom when , The system does not block user processes , But immediately return to a ewouldblock error , From the perspective of user process , There is no need to wait , It's about getting an immediate result . The user process judgment flag is ewouldblock when , I know the data is not ready yet , So it can do something else , So it can send... Again recvfrom, Once the data in the kernel is ready . And again received the user process's system call, Then it immediately copies the data to the user memory , Then return .
When an application makes a non blocking call in a loop recvfrom, We call it polling . Applications constantly poll the kernel , See if you're ready for some operations . This is usually a waste CPU Time , But this pattern occasionally encounters .
I/O Reuse (I/O Multiplexing)
IO multiplexing The word may be a little strange , But if I say select,epoll, I think we can all understand . Some places also call this IO The way is event driven IO. We all know ,select/epoll The good thing about it is that it's a single process You can handle multiple network connections at the same time IO. Its basic principle is select/epoll This function Will constantly poll all the socket, When a socket There's data coming in , Just inform the user of the process .
In this mode , The user needs to make two system calls , First of all to select call , Then the user process will be called by the whole block live ( In multithreaded applications , Just a thread is block live , Not the whole process ). When select When the call returns , The user process proceeds again recvfrom call , Then copy the data from the kernel buffer to the user process space .
Its flow chart is as follows :
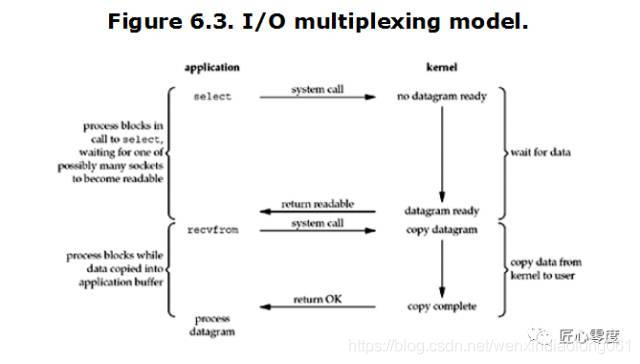
When the user process calls select, Then the whole process will be block, At the same time , The kernel will “ monitor ” all select conscientious socket, When any one socket The data in is ready ,select It will return . At this time, the user process calls read operation , Copy data from the kernel to the user process .
This figure and blocking IO It's not that different , in fact , It's worse . Because we need to use two system call (select and recvfrom), and blocking IO Only one was called system call (recvfrom). however , use select The advantage is that it can handle multiple connection.( Many say . therefore , If the number of connections processed is not very high , Use select/epoll Of web server It's not necessarily better than using multi-threading + blocking IO Of web server Better performance , Maybe the delay is even greater .select/epoll The advantage is not that you can handle a single connection faster , It's about being able to handle more connections .)
stay IO multiplexing Model in , In the actual , For each of these socket, It's usually set to non-blocking, however , As shown in the figure above , For the entire user process In fact, it has been block Of . It's just process Be being select This function block, Rather than being socket IO to block.
in other words , Single thread multiplexing this way , In fact, it does not reduce the response time of a single application request , For a single application request , It's always blocked . But it improves the concurrency of application requests that can be processed at the same time , In high concurrency , So as not to make the response time of a single application request too long , The processing power of this mode in the case of high concurrency is stronger than that of other modes .
File descriptor fd
Linux The kernel can operate all external devices as a file . So we can operate with the external device as the operation of the file . We read and write a file , By calling the system call provided by the kernel ; The kernel returns us a filede scriptor(fd, File descriptor ). And to one socket There will also be corresponding descriptors for reading and writing , be called socketfd(socket The descriptor ). A descriptor is a number , Point to a structure in the kernel ( File path , Data area , Wait for some attributes ). So our application can read and write files through descriptors .
select
The basic principle :select File descriptors for function monitoring 3 class , Namely writefds、readfds、 and exceptfds. After calling select Function will block , Until a descriptor is ready ( There's data Can be read 、 Can write 、 Or there is except), Or a timeout (timeout Specify waiting time , If immediate return is set to null that will do ), The function returns . When select When the function returns , You can do this by traversing fdset, To find the ready descriptor .
shortcoming :
1、select The biggest drawback is that a single process opens FD There are certain restrictions , It consists of FDSETSIZE Set up ,32 The default of bit computer is 1024 individual ,64 The default of bit computer is 2048.
In general, this number has a lot to do with system memory ,” The specific number can be cat /proc/sys/fs/file-max see ”.32 The default of bit computer is 1024 individual .64 The default of bit computer is 2048.
2、 Yes socket When scanning, it's a linear scan , That is, the polling method is adopted , Low efficiency .
When there are more sockets , Every time select() Through traversal FDSETSIZE individual Socket To complete the dispatch , Either way Socket Is active , Go through it all . It's a lot of waste CPU Time .” If you can register a callback function for the socket , When they are active , Automatic completion of related operations , That avoids polling ”, That's exactly what it is. epoll And kqueue It's done .
3、 Need to maintain one to store a lot of fd Data structure of , This will make the user space and kernel space to transfer the structure of the replication overhead .
poll
The basic principle :poll In essence, select There is no difference between , It copies the array passed in by the user into kernel space , And then look up each fd Corresponding device status , If the device is ready, add an entry to the device wait queue and continue to traverse , If you're done traversing all of fd No ready devices were found , Suspend the current process , Until the device is ready or active timeout , When awakened, it will traverse again fd. This process has gone through many unnecessary traversal .
It has no maximum number of connections , The reason is that it's based on a linked list , But there is also a drawback :1、 a large number of fd The array is copied between user mode and kernel address space , And whether this kind of replication makes sense .
2 、poll Another characteristic is “ Level trigger ”, If you report fd after , Not handled , So next time poll It will be reported again fd.
Be careful : From above ,select and poll All need to be back , Get the ready... By traversing the file descriptor socket. in fact , A large number of clients connected at the same time may only be in a few ready states at one time , So as the number of descriptors monitored grows , Its efficiency will also decrease linearly .
epoll
epoll Is in 2.6 In the kernel , It was before select and poll Enhanced version of . be relative to select and poll Come on ,epoll More flexible , There is no descriptor limit .epoll Use one file descriptor to manage multiple descriptors , Store the events of the user relationship's file descriptor in an event table in the kernel , So in user space and kernel space copy Just once. .
The basic principle :epoll Support horizontal trigger and edge trigger , The biggest feature is edge triggered , It only tells the process what fd Just got ready , And only once . Another characteristic is ,epoll Use “ event ” Is ready to inform , adopt epollctl register fd, Once it's time to fd be ready , The kernel uses something like callback Call back mechanism to activate the fd,epollwait You can receive the notice .
epoll The advantages of :1、 There is no maximum concurrent connection limit , It can be opened FD The upper limit is much larger than 1024(1G Can monitor about 10 Ten thousand ports ).
2、 Efficiency improvement , It's not polling , Not as FD The number increases and the efficiency decreases .
Only active is available FD Will call callback function ; namely Epoll The biggest advantage is that it only cares about you “ active ” The connection of , It's not about the total number of connections , So in the actual network environment ,Epoll Will be much more efficient than select and poll.
3、 Memory copy , utilize mmap() File mapped memory acceleration and kernel space messaging ; namely epoll Use mmap Reduce replication overhead .
From sync 、 asynchronous , And obstruction 、 From the perspective of non blocking two dimensions :
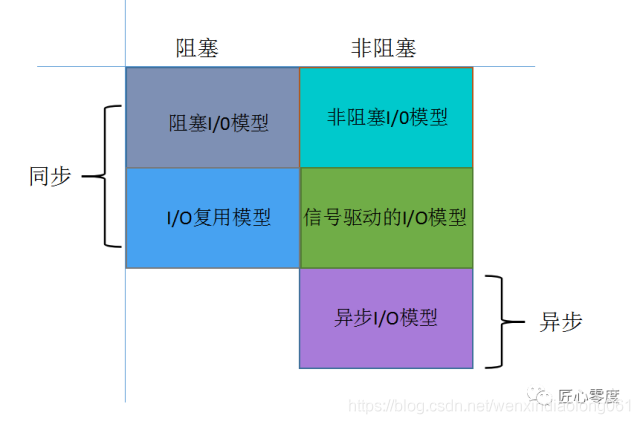
JDK1.5_update10 Version USES epoll Instead of the traditional select/poll, Greatly improved NIO The performance of communication .
cache IO
cache IO Also known as the standard IO, Default for most file systems IO Operations are all caching IO. stay Linux The cache of IO In mechanism , The operating system will IO The data is cached in the file system's page cache ( page cache ) in , in other words , The data will be copied to the buffer of the operating system kernel first , Then it will copy from the buffer of the operating system kernel to the address space of the application .
cache IO The shortcomings of : Data in the process of transmission needs to be copied in the application address space and the kernel many times , What these data copying operations bring CPU And memory overhead is very large .
Zero copy technology classification
The development of zero copy technology has been diversified , There are many kinds of zero copy technologies available , Currently, there is no zero copy technology for all scenarios . about Linux Come on , There are many existing zero copy technologies , Most of these zero copy technologies exist in different Linux Kernel version , There are some old technologies in different Linux Kernel versions have been greatly developed or have been gradually replaced by new technologies . This paper divides these zero copy technologies into different scenarios . Sum up ,Linux The zero copy technology in mainly has the following several :
-
direct I/O: For this kind of data transmission , Applications have direct access to hardware storage , The operating system kernel is just auxiliary data transmission : This kind of zero copy technology is aimed at the situation that the operating system kernel does not need to process the data directly , Data can be transferred directly between the buffer and the disk in the application address space , There's no need for Linux Support for page caching provided by the operating system kernel .
-
In the process of data transmission , Avoid copying data between the operating system kernel address space buffer and the user application address space buffer . sometimes , The application does not need to access the data in the process of data transmission , that , Take data from Linux Copy the page cache to the buffer of the user process , The transferred data can be processed in the page cache . In some special circumstances , This zero copy technology can achieve better performance .Linux Similar system calls are provided in mmap(),sendfile() as well as splice().
-
The data is in Linux The transfer process between the page cache and the user process buffer is optimized . The zero copy technology focuses on flexible handling of data copy operations between the user process buffer and the operating system's page cache . This method continues the traditional way of communication , But more flexible . stay Linux in , This method mainly uses copy at write technology .
The purpose of the first two methods is to avoid buffer copy operation between application address space and operating system kernel address space . These two types of zero copy technologies are usually applicable in some special cases , For example, the data to be transmitted does not need to be processed by the operating system kernel or by the application program . The third method inherits the traditional concept of data transmission between application address space and operating system kernel address space , And then optimize the data transmission itself . We know , Data transfer between hardware and software can be done by using DMA To carry out ,DMA There is little need for data transfer CPU Participate in , So we can take CPU Free up to do more other things , But when data needs to be buffered in user address space and Linux When the page cache of the operating system kernel is transferred between them , There is no parallel DMA This tool can be used ,CPU You need to be fully involved in this data copy operation , Therefore, the purpose of the third method is to effectively improve the efficiency of data transfer between the user address space and the operating system kernel address space .
Be careful , Whether various zero copy mechanisms can be implemented depends on whether the underlying operating system provides corresponding support .

When an application accesses a piece of data , The operating system first checks for , Have you visited this file recently , Whether the file contents are cached in the kernel buffer , If it is , The operating system is directly based on read System call provides buf Address , Copy the contents of the kernel buffer to buf In the specified user space buffer . If not , The operating system first copies the data on the disk to the kernel buffer , At present, this step mainly depends on DMA To transmit , Then copy the contents of the kernel buffer to the user buffer .
Next ,write The system call copies the contents of the user buffer to the kernel buffer related to the network stack , Last socket Then send the contents of the kernel buffer to the network card .
As can be seen from the above figure , Four copies of the data were generated , Even if DMA To handle the communication with the hardware ,CPU Still need to process two copies of data , meanwhile , In the user mode and the kernel mode, there are many context switches , No doubt it's aggravating CPU burden .
In the process , We have not made any changes to the contents of the document , So copying data back and forth between kernel space and user space is undoubtedly a waste , Zero copy is mainly to solve this inefficiency .
Make data transmission unnecessary user space, Use mmap
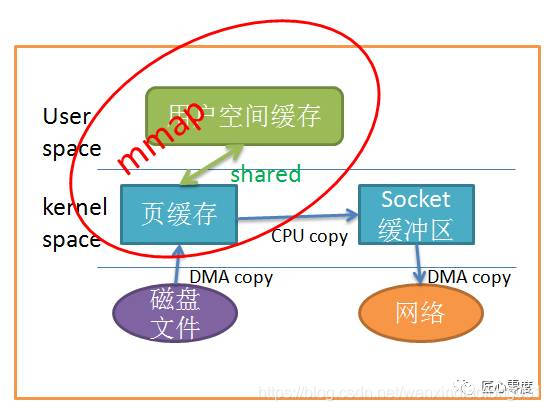
One way we can reduce the number of copies is to call mmap() Instead of read call :
Application calls mmap(), The data on the disk will pass through DMA The copied kernel buffer , Then the operating system will share the kernel buffer with the application , In this way, you don't need to copy the contents of the kernel buffer to user space . The application calls write(), The operating system directly copies the contents of the kernel buffer to socket Buffer zone , All this happens in kernel state , Last , socket The buffer sends the data to the network card .
alike , It's easy to look at the picture :
Use mmap replace read There's a significant reduction in one copy , When there is a large amount of copied data , No doubt it improves efficiency . But use mmap There is a price . When you use mmap when , You may encounter some hidden traps . for example , When your program map A document , But when this file is truncated by another process (truncate) when , write The system call will be SIGBUS Signal termination . SIGBUS The signal defaults to killing your process and creating a coredump, If your server is suspended like this , That would be a loss .
Usually we use the following solutions to avoid this problem :
by SIGBUS Signal set up signal processing program When you meet SIGBUS Signal time , The signal processor simply returns , write The system call returns the number of bytes written before it is interrupted , also errno It's going to be set to success, But it's a bad way to deal with it , Because you don't solve the core of the problem .
Use file rental lock Usually we use this method , Use lease locks on file descriptors , We request a lease lock from the kernel for the file , When other processes want to truncate this file , The kernel will send us a real-time RT_SIGNAL_LEASE The signal , Tell us that the kernel is breaking the read and write locks you've imposed on files . In this way, the program accesses illegal memory and is SIGBUS Before killing , Yours write The system call will be interrupted . write Returns the number of bytes that have been written , And put errno by success. We should mmap Lock the file before it , And unlock the file after the operation .
版权声明
本文为[Li Siwei]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204210600380923.html
边栏推荐
- [advanced level 11 of C language -- character and string functions and their simulation implementation (2)]
- Openlayers 5.0 discrete aggregation points
- Android Development: the client obtains the latest value in the database in real time and displays it on the interface
- MySQL restores or rolls back data through binlog
- An algorithm problem was encountered during the interview_ Find the mirrored word pairs in the dictionary
- Openharmony open source developer growth plan, looking for new open source forces that change the world!
- Accessing private members using templates
- All table queries and comment description queries of SQL Server
- 2022.04.23(LC_714_买卖股票的最佳时机含手续费)
- Common processing of point cloud dataset
猜你喜欢
FTP, SSH Remote Access and control

2022.04.23(LC_763_划分字母区间)
On the forced conversion of C language pointer

12 examples to consolidate promise Foundation

mysql通过binlog恢复或回滚数据

Client interns of a large factory share their experience face to face
FTP、ssh远程访问及控制

An algorithm problem was encountered during the interview_ Find the mirrored word pairs in the dictionary
![[report] Microsoft: application of deep learning methods in speech enhancement](/img/29/2d2addd826359fdb0920e06ebedd29.png)
[report] Microsoft: application of deep learning methods in speech enhancement

RuntimeError: Providing a bool or integral fill value without setting the optional `dtype` or `out`
随机推荐
C1000k TCP connection upper limit test 1
RuntimeError: Providing a bool or integral fill value without setting the optional `dtype` or `out`
Pdf reference learning notes
高层次人才一站式服务平台开发 人才综合服务平台系统
SSDB foundation 2
SSDB Foundation
Introduction to micro build low code zero Foundation (lesson 3)
SSDB基础3
Coordinate conversion WGS-84 to gcj-02 and gcj-02 to WGS-84
Redis optimization series (III) solve common problems after master-slave configuration
One stop service platform for high-level talents and development of comprehensive service platform system for talents
mysql_ Download and installation of Linux version
Thoughts on the optimization of examination papers in the examination system
Raspberry pie 18b20 temperature
Pit encountered using camera x_ When onpause, the camera is not released, resulting in a black screen when it comes back
How to uninstall easyton
Keysight has chosen what equipment to buy for you
Circuit on-line simulation
MySQL学习第五弹——事务及其操作特性详解
[report] Microsoft: application of deep learning methods in speech enhancement