当前位置:网站首页>Building googlenet neural network based on pytorch for flower recognition
Building googlenet neural network based on pytorch for flower recognition
2022-04-23 19:40:00 【Bald Sue】
Author's brief introduction : Bald Sue , Committed to describing problems in the most popular language
Looking back : Kalman filter series 1—— Kalman filtering be based on pytorch build AlexNet Neural network is used for flower recognition
Near term goals : Have 5000 fans
Support Xiao Su : give the thumbs-up 、 Collection 、 Leaving a message.
List of articles
be based on pytorch build GoogleNet Neural network is used for flower recognition
Write it at the front
It's been out ahead be based on pytorch build AlexNet Neural network is used for flower recognition and be based on pytorch build VGGNet Neural network is used for flower recognition The article , It is recommended to read the first two articles before reading this article .
The network structure used in this article GoogleNet, So you need to know GoogleNet Have a clear understanding of the structure of , Unclear stamp this icon *** Learn more .
Same as the last one , This article will not explain every step of implementing flower class recognition , Only aim at GoogleNet Elaborate on the details of network construction , You can download it yourself Code Further study .
GoogleNet Network model building
GoogleNet At first glance, the structure of is quite complex , But there are a lot of repetitive structures , namely Inception structure . We can Inception Structure is encapsulated into a class for calling , This will greatly improve the readability of the code .Inception Class is defined as follows :
class Inception(nn.Module):
def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5, pool_proj):
super(Inception, self).__init__()
self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1)
self.branch2 = nn.Sequential(
BasicConv2d(in_channels, ch3x3red, kernel_size=1),
BasicConv2d(ch3x3red, ch3x3, kernel_size=3, padding=1) # Make sure the output size equals the input size
)
self.branch3 = nn.Sequential(
BasicConv2d(in_channels, ch5x5red, kernel_size=1),
BasicConv2d(ch5x5red, ch5x5, kernel_size=5, padding=2) # Make sure the output size equals the input size
)
self.branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
BasicConv2d(in_channels, pool_proj, kernel_size=1)
)
def forward(self, x):
branch1 = self.branch1(x)
branch2 = self.branch2(x)
branch3 = self.branch3(x)
branch4 = self.branch4(x)
outputs = [branch1, branch2, branch3, branch4]
return torch.cat(outputs, 1)
I don't want to explain too much here , Let's compare ourselves GoogleNet The theory of It should be well understood , But here I give a simple explanation of the parameters passed in by this class , In fact, it corresponds to Inception Some parameters of the structure , As shown in the figure below :

Let's talk about BasicConv2d This east east , This is actually the class we define , The definition is as follows :
class BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, **kwargs)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.relu(x)
return x
This is a better understanding , It combines the convolution with the following Relu The activation is encapsulated together
It is worth mentioning that GoogleNet In the network , There are also two auxiliary classifiers with the same structure , To simplify the code , We also encapsulate it as a class , as follows :
class InceptionAux(nn.Module):
def __init__(self, in_channels, num_classes):
super(InceptionAux, self).__init__()
self.averagePool = nn.AvgPool2d(kernel_size=5, stride=3)
self.conv = BasicConv2d(in_channels, 128, kernel_size=1) # output[batch, 128, 4, 4]
self.fc1 = nn.Linear(2048, 1024)
self.fc2 = nn.Linear(1024, num_classes)
def forward(self, x):
# aux1: N x 512 x 14 x 14, aux2: N x 528 x 14 x 14
x = self.averagePool(x)
# aux1: N x 512 x 4 x 4, aux2: N x 528 x 4 x 4
x = self.conv(x)
# N x 128 x 4 x 4
x = torch.flatten(x, 1)
x = F.dropout(x, 0.5, training=self.training)
# N x 2048
x = F.relu(self.fc1(x), inplace=True)
x = F.dropout(x, 0.5, training=self.training)
# N x 1024
x = self.fc2(x)
# N x num_classes
return x
In this way, all preparations have been made , We can define our GoogleNet Network :
class GoogLeNet(nn.Module):
def __init__(self, num_classes=1000, aux_logits=True):
super(GoogLeNet, self).__init__()
self.aux_logits = aux_logits
self.conv1 = BasicConv2d(3, 64, kernel_size=7, stride=2, padding=3)
self.maxpool1 = nn.MaxPool2d(3, stride=2, ceil_mode=True) #ceil_mode=True Indicates that when the obtained characteristic is decimal , Rounding up
self.conv2 = BasicConv2d(64, 64, kernel_size=1)
self.conv3 = BasicConv2d(64, 192, kernel_size=3, padding=1)
self.maxpool2 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception3a = Inception(192, 64, 96, 128, 16, 32, 32)
self.inception3b = Inception(256, 128, 128, 192, 32, 96, 64)
self.maxpool3 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception4a = Inception(480, 192, 96, 208, 16, 48, 64)
self.inception4b = Inception(512, 160, 112, 224, 24, 64, 64)
self.inception4c = Inception(512, 128, 128, 256, 24, 64, 64)
self.inception4d = Inception(512, 112, 144, 288, 32, 64, 64)
self.inception4e = Inception(528, 256, 160, 320, 32, 128, 128)
self.maxpool4 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception5a = Inception(832, 256, 160, 320, 32, 128, 128)
self.inception5b = Inception(832, 384, 192, 384, 48, 128, 128)
if self.aux_logits:
self.aux1 = InceptionAux(512, num_classes)
self.aux2 = InceptionAux(528, num_classes)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) # Adaptive average pooling , Change the size of the trait map to 1x1
self.dropout = nn.Dropout(0.4)
self.fc = nn.Linear(1024, num_classes)
if init_weights:
self._initialize_weights()
def forward(self, x):
# N x 3 x 224 x 224
x = self.conv1(x)
# N x 64 x 112 x 112
x = self.maxpool1(x)
# N x 64 x 56 x 56
x = self.conv2(x)
# N x 64 x 56 x 56
x = self.conv3(x)
# N x 192 x 56 x 56
x = self.maxpool2(x)
# N x 192 x 28 x 28
x = self.inception3a(x)
# N x 256 x 28 x 28
x = self.inception3b(x)
# N x 480 x 28 x 28
x = self.maxpool3(x)
# N x 480 x 14 x 14
x = self.inception4a(x)
# N x 512 x 14 x 14
if self.training and self.aux_logits: # eval model lose this layer
aux1 = self.aux1(x)
x = self.inception4b(x)
# N x 512 x 14 x 14
x = self.inception4c(x)
# N x 512 x 14 x 14
x = self.inception4d(x)
# N x 528 x 14 x 14
if self.training and self.aux_logits: # eval model lose this layer
aux2 = self.aux2(x)
x = self.inception4e(x)
# N x 832 x 14 x 14
x = self.maxpool4(x)
# N x 832 x 7 x 7
x = self.inception5a(x)
# N x 832 x 7 x 7
x = self.inception5b(x)
# N x 1024 x 7 x 7
x = self.avgpool(x)
# N x 1024 x 1 x 1
x = torch.flatten(x, 1)
# N x 1024
x = self.dropout(x)
x = self.fc(x)
# N x 1000 (num_classes)
if self.training and self.aux_logits: # eval model lose this layer
return x, aux2, aux1
return x
matters needing attention
Let's talk about this part GoogleNet Precautions for building and using network model . We know that GoogleNet There are two auxiliary classifiers , But these two auxiliary classifiers are only used in training , Do not use... During testing .【 Test seasonal parameters self.training and self.aux_logits The value of is False】 Because two auxiliary classifiers are used in training , So there are three outputs
In the process of forecasting , We don't need our auxiliary classifier , When loading model parameters, you need to set strict=False
Display of training results
This article will not explain the training steps in detail , and be based on pytorch build AlexNet Neural network is used for flower recognition Almost the same . Here are the training results , As shown in the figure below :

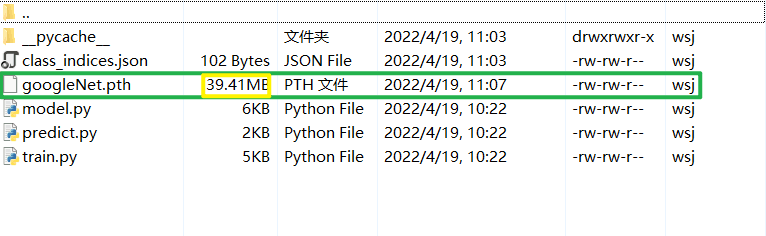
Its accuracy has reached 0.742, We can take another look at what we keep GoogleNet Model , Here's the picture , It can be seen that GoogleNet The parameters of are relative to VGG It can be said that there is a lot less , This is also consistent with our theory
Summary
For this part, I strongly recommend that you use Pycharm Debugging function of , Look at the results of each run step by step , In this way, you will find that the code structure is particularly clear .
Reference video :https://www.bilibili.com/video/BV1r7411T7M5/?spm_id_from=333.788
If the article is helpful to you , It would be
Whew, whew, whew ~~duang~~ A great bai
版权声明
本文为[Bald Sue]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204231929292302.html
边栏推荐
- OpenHarmony开源开发者成长计划,寻找改变世界的开源新生力!
- Speex Wiener filter and rewriting of hypergeometric distribution
- 2021-2022-2 ACM training team weekly Programming Competition (8) problem solution
- Openlayers 5.0 two centering methods
- Class loading process of JVM
- C6748 software simulation and hardware test - with detailed FFT hardware measurement time
- Kubernetes入门到精通-裸机LoadBalence 80 443 端口暴露注意事项
- Zero base to build profit taking away CPS platform official account
- Video understanding
- SRS 的部署
猜你喜欢
![[transfer] summary of new features of js-es6 (one picture)](/img/45/76dba32e4fa7ed44a42e5f98ea8207.jpg)
[transfer] summary of new features of js-es6 (one picture)
![[report] Microsoft: application of deep learning methods in speech enhancement](/img/29/2d2addd826359fdb0920e06ebedd29.png)
[report] Microsoft: application of deep learning methods in speech enhancement

Using oes texture + glsurfaceview + JNI to realize player picture processing based on OpenGL es

Shanda Wangan shooting range experimental platform project - personal record (V)

Openharmony open source developer growth plan, looking for new open source forces that change the world!
php参考手册String(7.2千字)

antd dropdown + modal + textarea导致的textarea光标不可被键盘控制问题

MySQL syntax collation (5) -- functions, stored procedures and triggers
Mfcc: Mel frequency cepstrum coefficient calculation of perceived frequency and actual frequency conversion
Use of fluent custom fonts and pictures
随机推荐
goroutine
IIS data conversion problem: 16bit to 24bit
音频编辑生成软件
MySQL syntax collation (4)
Gossip: on greed
filebeat、logstash配置安装
Some ideas about time-consuming needs assessment
MySQL syntax collation
Audio editing generation software
指针数组与数组指针的区分
优先使用组合而不使用继承
An algorithm problem was encountered during the interview_ Find the mirrored word pairs in the dictionary
数据分析学习目录
MySQL syntax collation (5) -- functions, stored procedures and triggers
2021-2022-2 ACM training team weekly Programming Competition (8) problem solution
仓库管理数据库系统设计
IIS数据转换问题16bit转24bit
[report] Microsoft: application of deep learning methods in speech enhancement
Why is PostgreSQL about to surpass SQL Server?
Executor、ExecutorService、Executors、ThreadPoolExecutor、Future、Runnable、Callable