当前位置:网站首页>What makes training multi-modal classification networks hard?
What makes training multi-modal classification networks hard?
2022-08-10 02:01:00 【Rainylt】
paper : What makes training multi-modal classification networks hard?
cvpr2020
一句话总结:多模态训练时利用验证集与训练集结合得到的过拟合指标来调制不同模态的Loss权重,解决多模态训练不平衡问题。
一句话讲完,还是有很多问题的,这篇文章也值得我写一篇笔记。
多模态融合方式
(1)Early Fusion
在原始数据输入的时候就concat或通过其他方式融合
(2)Mid Fusion
在提取特征后concat,再过Fusion模块,再过分类头
(3)Late Fusion
提取特征后concat,直接过分类头
什么是多模态训练不平衡问题?
起因是作者发现在视频分类任务上,多模态模型反而不如单模态模型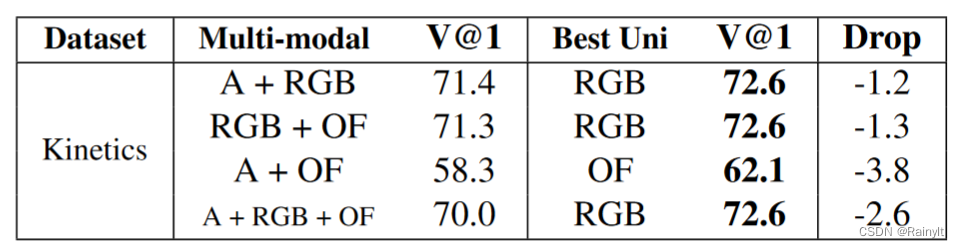
如上图,A是Audio,OF是光流(optical flow)。
用的模型都是差不多的,举个例子,A+RGB就是在单RGB的基础上加了Audio的Encoder,然后把两个feature concat在一起,通过分类器分类。而单RGB就是直接RGB过encoder,然后过分类器分类。
话说这里似乎没有在concat后增加transformer用来fuse?fuse模块或许可以一定程度上解决这个问题?
什么原因?
两个发现:
(1)multi-modal 模型有着更高的训练集精度,但是验证集精度较低
(2)Late Fusion的模型有单模态模型几乎两倍的参数量
=>怀疑问题出在过拟合
怎么解决?
首先试试常规的应对过拟合的方案:
1、Dropout
2、Pre-train
3、early stop
然后再试试mid-Fusion的方案:
1、concatenate(conv得到feature,concat后继续过conv,最后过分类头)
2、SE模式的Gating
3、Non-Local模式的Gating (就是transformer)
评价:
1、early stop完全不行,或许是停得太早了?
2、Pre-train比不Pre-train的late-concat要好,不过并不能赶上单模态RGB,也可能是Pre-train的方式不太好?
3、mid-concat有一些提升,不过竟然比Non-Local更好我是没想到的,是因为Non-Local只接了一层?mid-concat后的conv接了比较多?
4、Dropout有些效果,因为原本确实就有过拟合,不过原本没加dropout?
5、SE是通道级的Attention,并没有空间、时间、频率级的Attention,效果差也情有可原,加了跟没加一样
这部分得看看detail了 。
也就是说,mid-concat优于late concat,而且dropout也能work,不过提升得并不多
dropout能work说明网络确实存在过拟合,在加了dropout后终于是超过了单模态,mid-concat也能超过单模态,所以还是得早点fusion。
本文的方案
为了解决过拟合问题,本文首先提出了一个指标来衡量过拟合程度:
*代表真实场景(近似为验证集上)。
同时,在Late Fusion的基础上增加为3个分支,每个分支一个分类头:
中间的就是concat后的特征,再加个分类头,两边是各自分别过分类头。每个Loss都有一个权重,而权重就是由上面的指标优化来的:
最终得到权重公式:
推导没太看懂,不过总之他是为每个Loss分配了一个权重,那最终测试的时候又是怎么做的呢?
边栏推荐
- 小菜鸟河北联通上岗培训随笔
- Nacos源码分析专题(五)-Nacos小结
- Redis - Basic operations and usage scenarios of String|Hash|List|Set|Zset data types
- MMDetection框架的anchor_generators.py解析
- UXDB现在支持函数索引吗?
- what is a microcontroller or mcu
- How Microbes Affect Physical Health
- 【Kali安全渗透测试实践教程】第6章 密码攻击
- 手把手教你搭建ELK-新手必看-第一章:什么是ELK?
- 【二叉树-中等】1261. 在受污染的二叉树中查找元素
猜你喜欢





随机推荐
The 25th day of the special assault version of the sword offer
Redis - Basic operations and usage scenarios of String|Hash|List|Set|Zset data types
OptiFDTD应用:纳米盘型谐振腔等离子体波导滤波器
进程管理和任务管理
2022强网杯 Quals Reverse 部分writeup
Janus actual production case
OpenCV图像处理学习四,像素的读写操作和图像反差函数操作
实操|风控模型中常用的这三种预测方法与多分类场景的实现
【二叉树-中等】1261. 在受污染的二叉树中查找元素
用于X射线光学器件的哈特曼波前传感器
xss的DOMPurify过滤框架:一个循环问题以及两个循环问题
[Kali Security Penetration Testing Practice Course] Chapter 8 Web Penetration
2022.8.8 Exam area link (district) questions
2022.8.9考试排列变换--1200题解
程序员的专属浪漫——用3D Engine 5分钟实现烟花绽放效果
what is eabi
【Kali安全渗透测试实践教程】第8章 Web渗透
论旅行之收获
liunx PS1 设置
【二叉树-简单】112. 路径总和