当前位置:网站首页>Deep learning notes - fine tuning
Deep learning notes - fine tuning
2022-04-23 04:57:00 【Whisper_ yl】

It is usually hoped that models that can be trained on large data sets can help improve accuracy .

One part is feature extraction , One part is linear classification .
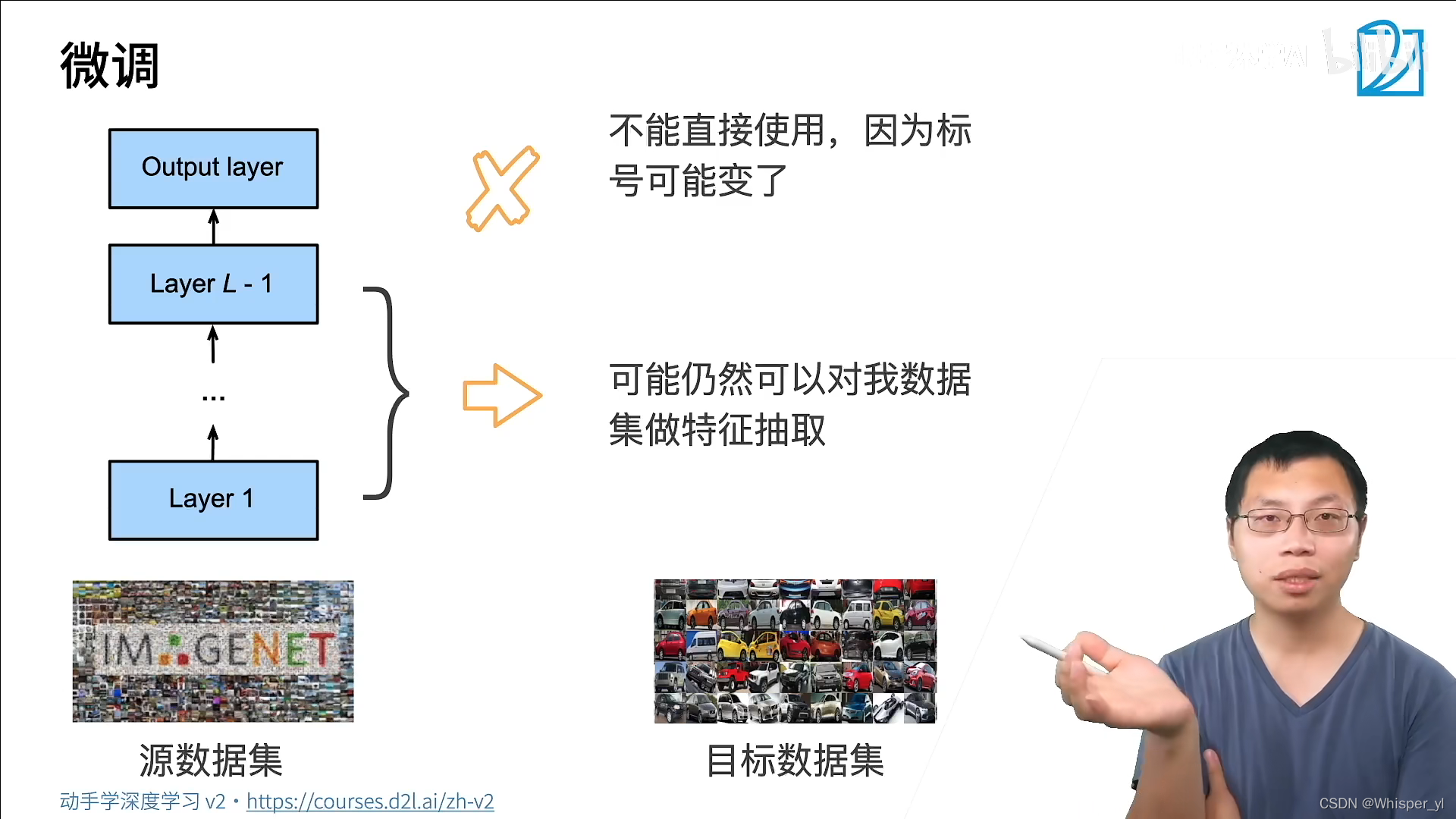
The core idea : In the source dataset ( Usually a relatively large data set ) On the training model , We think we can use the part for feature extraction .( The more general the underlying features are )
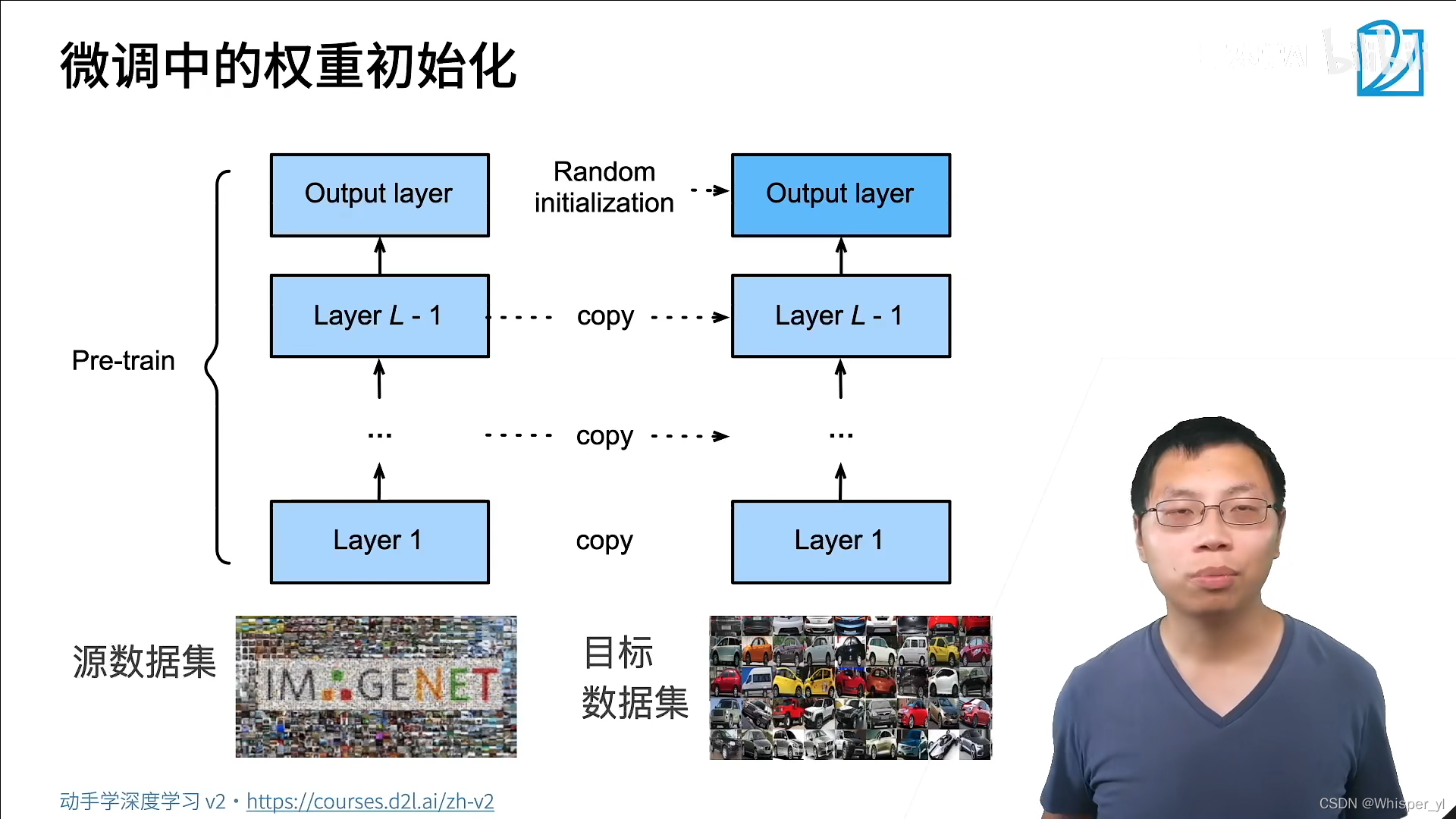 When training on your own dataset , Use one with pre-train Same architecture model , Except for the initialization of the last layer , No longer random initialization , But use pre-train Well trained weight( It may be very similar to the final result , Better than random initialization ), It is equivalent to copying the feature extraction module as my initialized model , So that I can do good feature expression at the beginning .( The label of the last layer is different , So it can be initialized randomly )
When training on your own dataset , Use one with pre-train Same architecture model , Except for the initialization of the last layer , No longer random initialization , But use pre-train Well trained weight( It may be very similar to the final result , Better than random initialization ), It is equivalent to copying the feature extraction module as my initialized model , So that I can do good feature expression at the beginning .( The label of the last layer is different , So it can be initialized randomly )

It is close to the optimal solution , So use less learning rate and fewer iterations .

 When fine tuning, do not change the weight of the underlying category , Secure it , Don't change those parameters , The complexity of the model is reduced .
When fine tuning, do not change the weight of the underlying category , Secure it , Don't change those parameters , The complexity of the model is reduced .
In the case of very small data sets , If you feel that all parameters participate in training, it is easy to over fit , You can consider fixing the parameters of some layers at the bottom , Do not participate in updates .

import os
import torch
import torchvision
from torch import nn
from d2l import torch as d2l
import matplotlib.pyplot as plt
# save
d2l.DATA_HUB['hotdog'] = (d2l.DATA_URL + 'hotdog.zip',
'fba480ffa8aa7e0febbb511d181409f899b9baa5')
data_dir = d2l.download_extract('hotdog')
train_imgs = torchvision.datasets.ImageFolder(os.path.join(data_dir, 'train'))
test_imgs = torchvision.datasets.ImageFolder(os.path.join(data_dir, 'test'))
hotdogs = [train_imgs[i][0] for i in range(8)]
not_hotdogs = [train_imgs[-i - 1][0] for i in range(8)]
d2l.show_images(hotdogs + not_hotdogs, 2, 8, scale=1.4)
plt.show()
# Use RGB The mean and standard deviation of the channel , To standardize each channel
# Because in ImageNet The training model did this , So do the same here
normalize = torchvision.transforms.Normalize(
[0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
train_augs = torchvision.transforms.Compose([
torchvision.transforms.RandomResizedCrop(224),
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ToTensor(),
normalize])
test_augs = torchvision.transforms.Compose([
torchvision.transforms.Resize(256),
torchvision.transforms.CenterCrop(224),
torchvision.transforms.ToTensor(),
normalize])
# Define and initialize models
# pretrained=True, Explain not only the definition of the model , Also take the trained parameters
pretrained_net = torchvision.models.resnet18(pretrained=True)
print(pretrained_net.fc)
finetune_net = torchvision.models.resnet18(pretrained=True)
# The final output layer is randomly initialized to a linear layer , Here is a binary classification problem
finetune_net.fc = nn.Linear(finetune_net.fc.in_features, 2)
# Only for the last layer weight Do initialization
nn.init.xavier_uniform_(finetune_net.fc.weight)
# Fine tune the model
def train_fine_tuning(net, learning_rate, batch_size=128, num_epochs=5,
param_group=True):
train_iter = torch.utils.data.DataLoader(torchvision.datasets.ImageFolder(
os.path.join(data_dir, 'train'), transform=train_augs),
batch_size=batch_size, shuffle=True)
test_iter = torch.utils.data.DataLoader(torchvision.datasets.ImageFolder(
os.path.join(data_dir, 'test'), transform=test_augs),
batch_size=batch_size)
devices = d2l.try_all_gpus()
loss = nn.CrossEntropyLoss(reduction="none")
# Take out all the layers except the last one , With a smaller learning rate ; The learning rate of the last layer is multiplied by 10, I hope they can learn faster
if param_group:
params_1x = [param for name, param in net.named_parameters()
if name not in ["fc.weight", "fc.bias"]]
trainer = torch.optim.SGD([{'params': params_1x},
{'params': net.fc.parameters(),
'lr': learning_rate * 10}],
lr=learning_rate, weight_decay=0.001)
else:
trainer = torch.optim.SGD(net.parameters(), lr=learning_rate,
weight_decay=0.001)
d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,
devices)
train_fine_tuning(finetune_net, 5e-5)
# Contrast , Not set up pretrained
scratch_net = torchvision.models.resnet18()
scratch_net.fc = nn.Linear(scratch_net.fc.in_features, 2)
# Adopt a higher learning rate
train_fine_tuning(scratch_net, 5e-4, param_group=False)版权声明
本文为[Whisper_ yl]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204230453143799.html
边栏推荐
- Windows remote connection to redis
- C. Tree infection (simulation + greed)
- 深度学习笔记 —— 微调
- unity摄像机旋转带有滑动效果(自转)
- New terminal play method: script guidance independent of technology stack
- Agile practice | agile indicators to improve group predictability
- 什么是指令周期,机器周期,和时钟周期?
- Details related to fingerprint payment
- C. Tree Infection(模拟+贪心)
- List remove an element
猜你喜欢
![[winui3] write an imitation Explorer file manager](/img/3e/62794f1939da7f36f7a4e9dbf0aa7a.png)
[winui3] write an imitation Explorer file manager
深度学习笔记 —— 微调
[WinUI3]編寫一個仿Explorer文件管理器

Innovation training (VI) routing
Learning Android II from scratch - activity
Excel uses the functions of replacement, sorting and filling to comprehensively sort out financial data

深度学习笔记 —— 语义分割和数据集
![解决ValueError: Argument must be a dense tensor: 0 - got shape [198602], but wanted [198602, 16].](/img/99/095063b72390adea6250f7b760d78c.png)
解决ValueError: Argument must be a dense tensor: 0 - got shape [198602], but wanted [198602, 16].

Windows remote connection to redis

Teach you how to build the ruoyi system by Tencent cloud
随机推荐
Field injection is not recommended using @ Autowired
Making message board with PHP + MySQL
信息学奥赛一本通 1212:LETTERS | OpenJudge 2.5 156:LETTERS
静态流水线和动态流水线的区别认识
Unity rawimage background seamlessly connected mobile
Graduation project
2022/4/22
信息学奥赛一本通 1955:【11NOIP普及组】瑞士轮 | OpenJudge 4.1 4363:瑞士轮 | 洛谷 P1309 [NOIP2011 普及组] 瑞士轮
Flink's important basics
vscode ipynb文件没有代码高亮和代码补全解决方法
Set Chrome browser background to eye protection (eye escort / darkreader plug-in)
Manually write smart pointer shared_ PTR function
Progress of innovation training (III)
C. Tree infection (simulation + greed)
多线程基本概念(并发与并行、线程与进程)和入门案例
Knowledge points sorting: ES6
leetcode——启发式搜索
TypeError: ‘Collection‘ object is not callable. If you meant to call the ......
PHP 统计指定文件夹下文件的数量
Innovation training (IX) integration