当前位置:网站首页>Spark small case - RDD, spark SQL
Spark small case - RDD, spark SQL
2022-04-23 04:41:00 【Z-hhhhh】
Separate use RDD and SparkSQL Two ways to solve the same data analysis problem ;
Project data
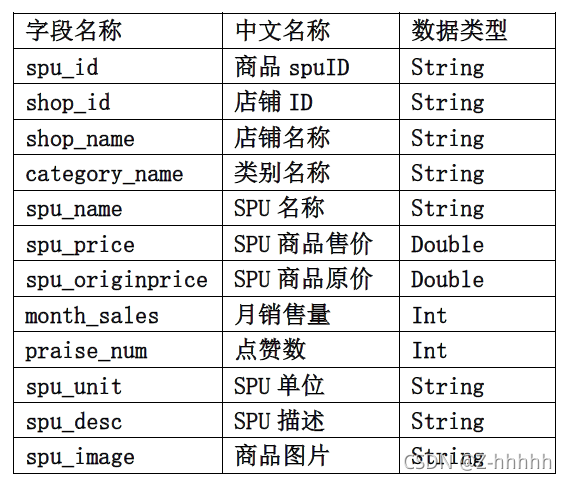
Project requirements
Use RDD and SQL There are two ways to clean the data
- The cleaning requirements are as follows :
- Count the number of goods in each store
- Count the total sales of each store
- Count the top three commodities with the highest sales in each store , Output contents include : Shop name , Trade name and sales volume
- Medium sales 0 No statistical calculation is carried out for the goods , for example : If a store sells 0 No statistics will be made .
It involves pom rely on
<properties>
<scala.version>2.12.10</scala.version>
<spark.version>3.1.2</spark.version>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-reflect</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-compiler</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>3.0.0</version>
</dependency>
</dependencies>
RDD The way
val session: SparkSession = SparkSession.builder().master("local[*]").appName("unname").getOrCreate()
val sc: SparkContext = session.sparkContext
//RDD The way
sc.textFile("hdfs://ip Address :9820/ Catalog /meituan_waimai_meishi.csv")
.mapPartitionsWithIndex((ix,it)=>{
// Delete header
if (ix == 0)it.drop(1)
it.map(line=>{
// Split data ,csv Default comma split
val ps: Array[String] = line.split(",")
// Get useful fields : Shop name , Trade name , Total amount of goods
// Calculate the total amount of goods in advance , Complete data conversion
(ps(2),ps(4),ps(5).toFloat*ps(7).toInt)
})
})
// Group by store name
.groupBy(_._1)
//mapValues For each key value value Apply a function , however ,key It won't change
.mapValues(itshop=>{
// Iterators do not support sorting
(
itshop.size,itshop.map(_._3).sum,
itshop.filter(_._3>0)
.toArray
.sortWith(_._3 > _._3)
.take(3)
.map(x=>{
s"${x._2}${x._3}"
}).mkString(";")
)
})
.foreach(println)
sc.stop()
session.close()
SparkSQL The way
val session: SparkSession = SparkSession.builder().master("local[*]").appName("unname").getOrCreate()
val sc: SparkContext = session.sparkContext
import session.implicits._ // Implicit conversion
/* there session No Scala The package name in , It's created sparkSession Object's variable name , So you must first create SparkSession Object and then import . there session Object cannot be used var Statement , because Scala Only support val The introduction of decorated objects * */
import org.apache.spark.sql.functions._
import org.apache.spark.sql.expressions.Window
val frame: DataFrame = session.read.format("CSV")
.option("inferSchema", true) // Whether to infer the table structure according to the file format
.option("delimiter", ",") // Specify the separator , Default to comma
.option("nullValue", "NULL") // Fill in empty values
.option("header", true) // Whether the header exists
.load("hdfs://192.168.71.200:9820/test/data/meituan_waimai_meishi.csv")
.select($"shop_name", $"spu_name", ($"spu_price" * $"month_sales").as("month_total"))
.cache() // Avoid double counting =persist(StorageLevel.MEMORY_AND_DISK_2)
val top3_shopname: DataFrame = frame
.filter($"month_total" > 0)
.select($"shop_name", $"spu_name", $"month_total",
dense_rank().over(Window.partitionBy($"shop_name")
.orderBy($"month_total".desc)).as("rnk")
).orderBy($"rnk".desc)
.filter($"rnk" < 3)
.groupBy($"shop_name".as("shop_name_top3"))
.agg(collect_list(concat_ws("_", $"spu_name", $"month_total")).as("top3"))
frame.groupBy($"shop_name")
.agg(count($"spu_name").as("cmm_count"),sum($"month_total").as("shop_total"))
.join(top3_shopname,$"shop_name_top3" === $"shop_name","inner")
.select($"shop_name",$"cmm_count",$"shop_total",$"top3")
.collect() // Merge partitions
.foreach(println)
// frame.collect().foreach(println)
// top3_shopname.foreach(x=>{println(x.toString())})
sc.stop()
session.close()
版权声明
本文为[Z-hhhhh]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204220559122405.html
边栏推荐
- thymeleaf th:value 为null时报错问题
- Error occurs when thymeleaf th: value is null
- 程序员抱怨:1万2的工资我真的活不下去了,网友:我3千咋说
- Create VPC in AWS console (no plate)
- /etc/bash_ completion. D directory function (the user logs in and executes the script under the directory immediately)
- Gut liver axis: host microbiota interaction affects hepatocarcinogenesis
- AWS EKS添加集群用户或IAM角色
- 【Pytorch基础】torch.split()用法
- Leetcode005 -- delete duplicate elements in the array in place
- Brushless motor drive scheme based on Infineon MCU GTM module
猜你喜欢

New terminal play method: script guidance independent of technology stack
![[paper reading] [3D target detection] point transformer](/img/c5/b1fe5f206b5fe6e4dcd88dce11592d.png)
[paper reading] [3D target detection] point transformer
QML advanced (V) - realize all kinds of cool special effects through particle simulation system

针对NFT的网络钓鱼

PIP3 installation requests Library - the most complete pit sorting
Jetpack 之 LifeCycle 组件使用详解
test

【时序】基于 TCN 的用于序列建模的通用卷积和循环网络的经验评估
A new method for evaluating the quality of metagenome assembly - magista

Bacterial infection and antibiotic use
随机推荐
leetcode004--罗马数字转整数
Differences among electric drill, electric hammer and electric pick
Small volume Schottky diode compatible with nsr20f30nxt5g
数据孤岛是什么?为什么2022年仍然存在数据孤岛?
A heavy sword without a blade is a great skill
C language: spoof games
做数据可视化应该避免的8个误区
Youqilin 22.04 lts version officially released | ukui 3.1 opens a new experience
兼容NSR20F30NXT5G的小体积肖特基二极管
基于英飞凌MCU GTM模块的无刷电机驱动方案开源啦
阿里十年技术专家联合打造“最新”Jetpack Compose项目实战演练(附Demo)
zynq平台交叉编译器的安装
用D435i录制自己的数据集运行ORBslam2并构建稠密点云
Coinbase: basic knowledge, facts and statistics about cross chain bridge
Gut liver axis: host microbiota interaction affects hepatocarcinogenesis
Microbial neuroimmune axis -- the hope of prevention and treatment of cardiovascular diseases
Programmers complain: I really can't live with a salary of 12000. Netizen: how can I say 3000
MySQL - data read / write separation, multi instance
电钻、电锤、电镐的区别
zynq平臺交叉編譯器的安裝