当前位置:网站首页>[Semantic Segmentation] 2022-HRViT CVPR
[Semantic Segmentation] 2022-HRViT CVPR
2022-08-10 03:31:00 【say】
【语义分割】2022-HRViT CVPR
论文题目:Multi-Scale High-Resolution Vision Transformer for Semantic Segmentation
论文链接:https://arxiv.org/abs/2111.01236
论文代码:https://github.com/facebookresearch/HRViT
作者单位:Facebook, UT-Austin
发表时间:2021年11月
引用:Gu J, Kwon H, Wang D, et al. Multi-scale high-resolution vision transformer for semantic segmentation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022: 12094-12103.
引用数:9
1. 简介
1.1 摘要
视觉Transformer(ViT) It has attracted much attention for its excellent performance on computer vision tasks.To address the limitations of its single-scale low-resolution representation,previous work enables ViT Adapt to high-resolution dense prediction tasks with hierarchical architectures,to generate pyramid features.然而,鉴于 ViT A classification-like sequential topology,Multiscale representation learning is in ViT Exploration is still insufficient.
为了增强 ViTs The ability to learn semantically rich and spatially accurate multi-scale representations,在这项工作中,We propose a high-resolution multi-branch architecture with visionTransformer的有效集成,称为 HRViT,Pushing the task of intensive Pareto frontier forecasting to the next level.
The authors explore heterogeneous branching designs,Reduced redundancy of linear layers,and increase the nonlinearity of the model,to balance model performance and hardware efficiency.本文所提出的HRViT在ADE20K上实现了50.20% mIoU,在Cityscapes上实现了83.16% mIoU,超过了最先进的MiT和CSWin,平均提高了1.78 mIoU,减少了28%的参数和21%的FLOPs.
1.2 介绍
HRViT不同于以往的ViTA few aspects are:
- Through parallel extraction of multi-scale features and cross-resolution fusion,提高了ViTmultiscale characterization;
- Enhanced local self-attention,消除了冗余的key和value,提高了效率,and through additional convolution paths、Additional non-linear and secondary shortcuts enhance the variety of features,增强了表达能力;
- Multi-scale feature extraction is enhanced with a mixed-scale convolutional feedforward network;
- HR卷积stem和高效的patch embedding layerKeep more low-level fine-grained features,降低了硬件成本.
同时,与HRNet-family不同的是,HRViTA unique heterogeneous branch design is employed to balance efficiency and performance,It's not a simple improvementHRNet,Rather, the pure ones are mainly constructed from self-attention operatorsViT拓扑结构.
主要贡献如下:
- 深入研究了ViTMultiscale representation learning in ,And combine the high-resolution architecture with Vision Transformer相结合,Enables high-performance dense predictive vision tasks;
- In order to achieve extensibilityHR-ViT集成,And achieve better performance and efficiency tradeoffs,利用了Transformer Block中的冗余,And design pairs through heterogeneous branchesHRViTThe key components are jointly optimized;
- HRViTRe-semantic segmentation taskADE20K达到50.20% mIoU,在Cityscapes上达到83.16% mIoU,超过了最先进的(SoTA)MiT和CSWin,同时参数减少28%,FLOPs降低21%.
2. 网络
2.1 网络总体架构

在图1中说明了HRViT的体系结构.It consists of a convolutional backbone,Reduce spatial dimensionality while extracting low-level features.然后构造了4progressiveTransformer Stage,其中第nstage includednparallel multiscaleTransformer branches.Each stage can have one or more modules.Each module starts with a lightweight dense fusion layer,Implement cross-resolution interaction and an efficient patch embedding for local feature extraction,Then there is the repetitively enhanced local self-attention block(HRViTAttn)and mixed-scale convolutional feedforward networks(MixCFN).
different from sequentialViTThe backbone gradually reduces the spatial dimension to generate pyramid features,maintained throughout the networkHR特征,Enhanced by cross-resolution fusionHR表示的质量.
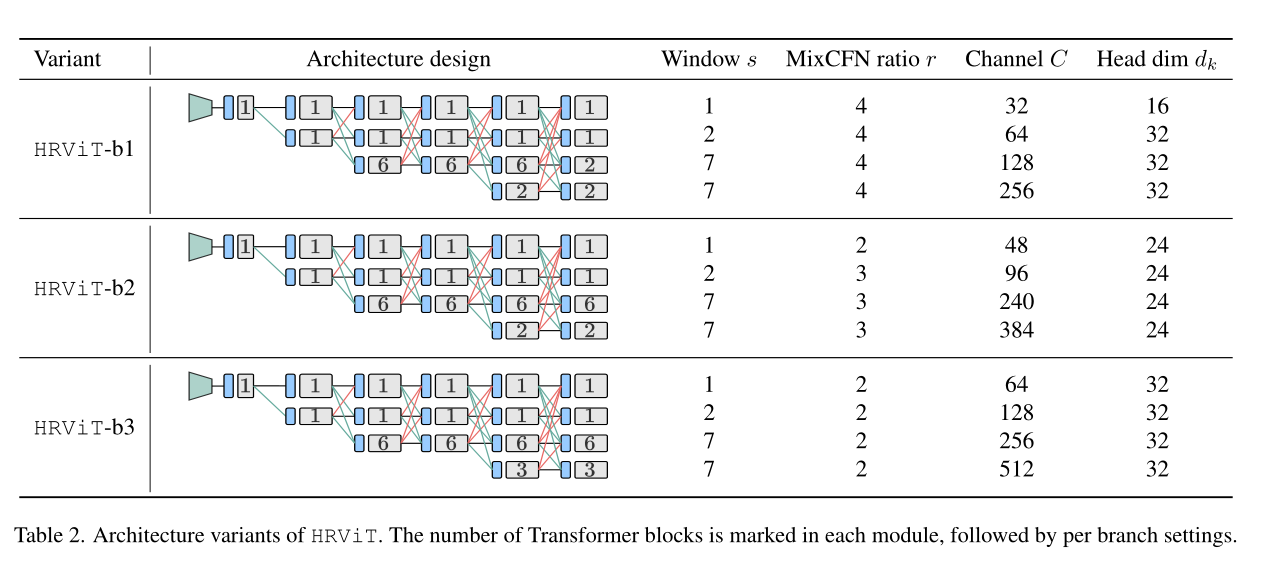
2.2 HRViTAttn
To achieve higher efficiency and higher performance,A hardware efficient self-attention operation is necessary.HRViT采用一种有效的cross-shaped self-attention 作为baseline attention operator.结构如下图所示.
Attention 复杂度最高的部分就是 Q 和 K 的矩阵相似度的计算,每个像素都参与计算相似度复杂度过高.因此,作者将从一开始就将通道分为两半,上面一半做行注意力,下面一半做列注意力.
HRViT-Attn有以下优点:
- Fine-grained attention:with global downsamplingattention相比,HRViT-AttnFine-grained feature aggregation with preserved details;
- Approximate global view:通过使用2A parallel orthogonal local attention to collect global information;
- Scalable complexity:windowOne dimension of is fixed,The quadratic complexity of image size is avoided.

To balance performance and hardware efficiency,Extended version introduced,表示为HRViT-Attn,There are several key optimizations.在图2(a)中,遵循CSWin中的cross-shaped window partitioning方法,Split the input into 2个部分.is split into disjoint horizontal windows,And the other half is split into vertical windows.窗口设置为s×W或H×s.在每个窗口内,patchis divided into blocksKdimensionHead,然后应用local self-attention,
HRViTAttn ( x ) = BN ( σ ( W O [ y 1 , ⋯ , y k , ⋯ , y K ] ) ) y k = z k + DWConv ( σ ( W k V x ) ) [ z k 1 , ⋯ , z k M ] = z k = { H − Attn k ( x ) , 1 ≤ k < K / 2 V − A Atn n k ( x ) , K / 2 ≤ k ≤ K z k m = MHSA ( W k Q x m , W k K x m , W k V x m ) [ x 1 , ⋯ , x m , ⋯ , x M ] = x , x m ∈ R ( H / s ) × W × C , \begin{array}{l} \operatorname{HRViTAttn}(x) = \operatorname{BN}\left(\sigma\left(W^{O}\left[y_{1}, \cdots, y_{k}, \cdots, y_{K}\right]\right)\right)\\ y_{k} = z_{k}+\operatorname{DWConv}\left(\sigma\left(W_{k}^{V} x\right)\right)\\ \left[z_{k}^{1}, \cdots, z_{k}^{M}\right] = z_{k} = \left\{\begin{array}{cc} \mathrm{H}-\operatorname{Attn}_{k}(x), & 1 \leq k<K / 2 \\ V-A \operatorname{Atn} n_{k}(x), & K / 2 \leq k \leq K \end{array}\right.\\ z_{k}^{m} = \operatorname{MHSA}\left(W_{k}^{Q} x^{m}, W_{k}^{K} x^{m}, W_{k}^{V} x^{m}\right)\\ \left[x^{1}, \cdots, x^{m}, \cdots, x^{M}\right] = x, \quad x^{m} \in \mathbb{R}^{(H / s) \times W \times C} \text {, } \end{array} HRViTAttn(x)=BN(σ(WO[y1,⋯,yk,⋯,yK]))yk=zk+DWConv(σ(WkVx))[zk1,⋯,zkM]=zk={ H−Attnk(x),V−AAtnnk(x),1≤k<K/2K/2≤k≤Kzkm=MHSA(WkQxm,WkKxm,WkVxm)[x1,⋯,xm,⋯,xM]=x,xm∈R(H/s)×W×C,
where is the generation thk个Head的query 、key 和value The projection matrix of the tensor,is the output projection matrix,σ为Hardswish激活函数.If the image size is not a multiple of the window size,对输入xApply zero padding,to allow a complete sectionk个窗口,如图2(b)所示.然后将Attention Map中的padding区域Mask为0,to avoid semantic inconsistencies.
原有的QKVLinear layers are computationally and parametrically expensive.共享HRViT-Attn中key张量和valueLinear projection of tensors,to save computation and parameters,如下所示:
MHSA ( W k Q x m , W k V x m , W k V x m ) = softmax ( Q k m ( V k m ) T d k ) V k m \operatorname{MHSA}\left(W_{k}^{Q} x^{m}, W_{k}^{V} x^{m}, W_{k}^{V} x^{m}\right)=\operatorname{softmax}\left(\frac{Q_{k}^{m}\left(V_{k}^{m}\right)^{T}}{\sqrt{d_{k}}}\right) V_{k}^{m} MHSA(WkQxm,WkVxm,WkVxm)=softmax(dkQkm(Vkm)T)Vkm
此外,The authors also introduce an auxiliary path with parallel depthwise convolutions to inject induced biases to facilitate training.与CSWinThe local position encodings in are different,HRViTThe parallel paths are nonlinear,and apply to the whole4-D特征图上,without the need for window division.This path can be viewed as an inverse residual modulo,Shared with the self-attention linear projection layerpoint-wise卷积.This shared path can effectively inject induced bias,And strengthen local feature aggregation with less hardware overhead.
作为对上述key-valueShared performance compensation,作者引入了一个额外的Hardswishfunction to improve nonlinearity.Also attached oneBatchNorm(BN)层,The layer is initialized to oneidentity投影,Get better trainability with a stable distribution.
最近的研究表明,不同的Transformer layertend to have very similar properties,其中Shortcut起着至关重要的作用.受augmented shortcutway of inspiration,The authors added a channel-like projection as a diversity enhancementshortcut方式(DES).The main difference is that of this articleShortcutwith higher nonlinearity,And doesn't rely on unfriendly hardware Fourier transform.
投影矩阵DES 近似为Kronecker分解,Minimize parameter cost,其中P最优设置为.然后将x折叠为,and will convert to to save computation.进一步在BInsert after projectionHardswish以增加非线性,
DES ( x ) = A ⋅ Hardswish ( x ~ B T ) \operatorname{DES}(x)=A \cdot \text { Hardswish }\left(\tilde{x} B^{T}\right) DES(x)=A⋅ Hardswish (x~BT)
总结:作者主要进行了四处改进:
- s行为一个token,每个 token 的特征为 s × W s \times W s×W或者$ s \times H ,同时,相似度矩阵就为 ,同时,相似度矩阵就为 ,同时,相似度矩阵就为s \times s$了,相似度的计算就简化了.(这里的处理方法和 Restormer 类似,大家可以回顾);
- 正常得到 K,Q,V时,需要三个 1x1 卷积,这里作者只使用了两个,K 和 V 是共享的,又进一步简化了计算;
- V 额外使用了 Hardwith 激活函数和 DWConv 处理,作者解释是增加了归纳偏置.
添加了一个 diversity-enhanced shortcut,这里是受了 NeurIPS2021 论文 Augmented Shortcuts for Vision Transformers 的启发,非常类似.
2.3 MixCFN
作者提出的 MixCFN 和大多数的 FFN 类似,都是先升维,后降维.不同的地方就是为了增强多尺度特征的提取,作者使用了 3X3 卷积和 5X5 卷积,如下图所示.
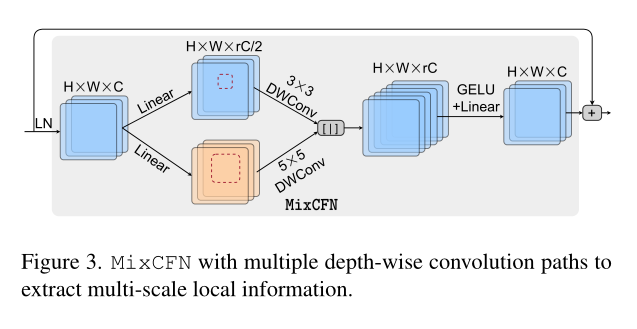
2.4 融合模块

3. 代码
# Copyright (c) Meta Platforms, Inc. and affiliates. All Rights Reserved.
import logging
import math
from functools import lru_cache
from typing import List, Optional, Tuple
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.checkpoint as cp
from einops import rearrange
from timm.data import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
from timm.models.layers import DropPath, to_2tuple
from timm.models.registry import register_model
from torch import Tensor
from torch.types import _size
logger = logging.getLogger(__name__)
def _cfg(url="", **kwargs):
return {
"url": url,
"num_classes": 1000,
"input_size": (3, 224, 224),
"pool_size": None,
"crop_pct": 0.9,
"interpolation": "bicubic",
"mean": IMAGENET_DEFAULT_MEAN,
"std": IMAGENET_DEFAULT_STD,
"first_conv": "patch_embed.proj",
"classifier": "head",
**kwargs,
}
default_cfgs = {
"hrvit_224": _cfg(),
}
class MixConv2d(nn.Module):
def __init__(
self,
in_channels: int,
out_channels: int,
kernel_size: int = 3,
stride: int = 1,
padding: int = 0,
dilation: int = 1,
groups: int = 1,
bias: bool = True,
) -> None:
super().__init__()
self.conv_3 = nn.Conv2d(
in_channels // 2,
out_channels // 2,
kernel_size,
stride=1,
padding=padding,
dilation=dilation,
groups=groups // 2,
bias=bias,
)
self.conv_5 = nn.Conv2d(
in_channels - in_channels // 2,
out_channels - out_channels // 2,
kernel_size + 2,
stride=stride,
padding=padding + 1,
dilation=dilation,
groups=groups - groups // 2,
bias=bias,
)
def forward(self, x: Tensor) -> Tensor:
x1, x2 = x.chunk(2, dim=1)
x1 = self.conv_3(x1)
x2 = self.conv_5(x2)
x = torch.cat([x1, x2], dim=1)
return x
class DES(nn.Module):
def __init__(
self,
in_features: int,
out_features: int,
bias: bool = True,
act_func: nn.Module = nn.GELU,
) -> None:
super().__init__()
_, self.p = self._decompose(min(in_features, out_features))
self.k_out = out_features // self.p
self.k_in = in_features // self.p
self.proj_right = nn.Linear(self.p, self.p, bias=bias)
self.act = act_func()
self.proj_left = nn.Linear(self.k_in, self.k_out, bias=bias)
def _decompose(self, n: int) -> List[int]:
assert n % 2 == 0, f"Feature dimension has to be a multiple of 2, but got {
n}"
e = int(math.log2(n))
e1 = e // 2
e2 = e - e // 2
return 2 ** e1, 2 ** e2
def forward(self, x: Tensor) -> Tensor:
B = x.shape[:-1]
x = x.view(*B, self.k_in, self.p)
x = self.proj_right(x).transpose(-1, -2)
if self.act is not None:
x = self.act(x)
x = self.proj_left(x).transpose(-1, -2).flatten(-2, -1)
return x
class MixCFN(nn.Module):
def __init__(
self,
in_features: int,
hidden_features: Optional[int] = None,
out_features: Optional[int] = None,
act_func: nn.Module = nn.GELU,
with_cp: bool = False,
):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.with_cp = with_cp
self.fc1 = nn.Linear(in_features, hidden_features)
self.conv = MixConv2d(
hidden_features,
hidden_features,
kernel_size=3,
stride=1,
padding=1,
groups=hidden_features,
dilation=1,
bias=True,
)
self.act = act_func()
self.fc2 = nn.Linear(hidden_features, out_features)
def forward(self, x: Tensor, H: int, W: int) -> Tensor:
def _inner_forward(x: Tensor) -> Tensor:
x = self.fc1(x)
B, N, C = x.shape
x = self.conv(x.transpose(1, 2).view(B, C, H, W))
x = self.act(x)
x = self.fc2(x.flatten(2).transpose(-1, -2))
return x
if self.with_cp and x.requires_grad:
x = cp.checkpoint(_inner_forward, x)
else:
x = _inner_forward(x)
return x
class Bottleneck(nn.Module):
expansion = 4
def __init__(
self,
inplanes: int,
planes: int,
stride: int = 1,
with_cp: bool = False,
):
super(Bottleneck, self).__init__()
self.with_cp = with_cp
self.conv1 = nn.Conv2d(
inplanes,
planes,
kernel_size=1,
stride=1,
dilation=1,
padding=0,
groups=1,
bias=False,
)
self.bn1 = nn.BatchNorm2d(
planes, momentum=1 - 0.9 ** 0.5 if self.with_cp else 0.1
)
self.conv2 = nn.Conv2d(
planes,
planes,
kernel_size=3,
stride=stride,
dilation=1,
padding=1,
groups=1,
bias=False,
)
self.bn2 = nn.BatchNorm2d(
planes, momentum=1 - 0.9 ** 0.5 if self.with_cp else 0.1
)
self.conv3 = nn.Conv2d(
planes,
planes * self.expansion,
kernel_size=1,
stride=1,
dilation=1,
padding=0,
groups=1,
bias=False,
)
self.bn3 = nn.BatchNorm2d(
planes * self.expansion, momentum=1 - 0.9 ** 0.5 if self.with_cp else 0.1
)
self.relu = nn.ReLU(inplace=True)
self.downsample = None
if stride != 1 or inplanes != planes * self.expansion:
self.downsample = nn.Sequential(
nn.Conv2d(
inplanes,
planes * self.expansion,
kernel_size=1,
stride=stride,
dilation=1,
padding=0,
groups=1,
bias=False,
),
nn.BatchNorm2d(
planes * self.expansion,
momentum=1 - 0.9 ** 0.5 if self.with_cp else 0.1,
),
)
self.stride = stride
def forward(self, x: Tensor) -> Tensor:
def _inner_forward(x: Tensor) -> Tensor:
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out = out.add(residual)
return out
if self.with_cp and x.requires_grad:
x = cp.checkpoint(_inner_forward, x)
else:
x = _inner_forward(x)
x = self.relu(x)
return x
class HRViTClassifier(nn.Module):
def __init__(
self,
in_channels: Tuple[int] = (32, 64, 128, 256),
head_channels: Tuple[int] = (32, 64, 128, 256),
num_classes: int = 1000,
dropout: float = 0.0,
act_func: nn.Module = nn.ReLU,
with_cp: bool = False,
) -> None:
super().__init__()
self.with_cp = with_cp
head_block = Bottleneck
# Increasing the #channels on each resolution
# from C, 2C, 4C, 8C to 128, 256, 512, 1024
incre_modules = []
for i, channels in enumerate(in_channels):
incre_module = self._make_layer(
head_block,
channels,
head_channels[i],
1,
stride=1,
)
incre_modules.append(incre_module)
self.incre_modules = nn.ModuleList(incre_modules)
# downsampling modules
downsamp_modules = []
for i in range(len(in_channels) - 1):
inc = head_channels[i] * head_block.expansion
outc = head_channels[i + 1] * head_block.expansion
downsamp_module = nn.Sequential(
nn.Conv2d(
in_channels=inc,
out_channels=outc,
kernel_size=3,
stride=2,
dilation=1,
padding=1,
groups=1,
bias=True,
),
nn.BatchNorm2d(outc),
act_func(inplace=True),
)
downsamp_modules.append(downsamp_module)
self.downsamp_modules = nn.ModuleList(downsamp_modules)
self.final_layer = nn.Sequential(
nn.Conv2d(
in_channels=head_channels[3] * head_block.expansion,
out_channels=2048,
kernel_size=1,
stride=1,
dilation=1,
padding=0,
groups=1,
bias=True,
),
nn.BatchNorm2d(2048),
act_func(inplace=True),
)
self.pool = nn.AdaptiveAvgPool2d(1)
self.dropout = nn.Dropout(dropout)
self.classifier = (
nn.Linear(2048, num_classes) if num_classes > 0 else nn.Identity()
)
def _make_layer(
self, block: nn.Module, inplanes: int, planes: int, blocks: int, stride: int = 1
) -> nn.Module:
layers = []
layers.append(
block(
inplanes=inplanes,
planes=planes,
stride=stride,
with_cp=self.with_cp,
)
)
inplanes = planes * block.expansion
for _ in range(1, blocks):
layers.append(
block(
inplanes,
planes,
with_cp=self.with_cp,
)
)
return nn.Sequential(*layers)
def forward(
self,
y_list: Tuple[
Tensor,
],
) -> Tensor:
# Classification Head
y = self.incre_modules[0](y_list[0])
for i in range(len(self.downsamp_modules)):
y = self.incre_modules[i + 1](y_list[i + 1]) + self.downsamp_modules[i](y)
y = self.final_layer(y)
y = self.pool(y).flatten(1)
y = self.dropout(y)
y = self.classifier(y)
return y
class HRViTAttention(nn.Module):
def __init__(
self,
in_dim: int = 64,
dim: int = 64,
heads: int = 2,
ws: int = 1, # window size
qk_scale: Optional[float] = None,
proj_drop: float = 0.0,
with_cp: bool = False,
):
super().__init__()
assert dim % heads == 0, f"dim {
dim} should be divided by num_heads {
heads}."
self.in_dim = in_dim
self.dim = dim
self.heads = heads
self.dim_head = dim // heads
self.ws = ws
self.with_cp = with_cp
self.to_qkv = nn.Linear(in_dim, 2 * dim)
self.scale = qk_scale or self.dim_head ** -0.5
self.attend = nn.Softmax(dim=-1)
self.attn_act = nn.Hardswish(inplace=True)
self.to_out = nn.Sequential(
nn.Linear(dim, dim),
nn.Dropout(proj_drop),
)
self.attn_bn = nn.BatchNorm1d(
dim, momentum=1 - 0.9 ** 0.5 if self.with_cp else 0.1
)
nn.init.constant_(self.attn_bn.bias, 0)
nn.init.constant_(self.attn_bn.weight, 0)
self.parallel_conv = nn.Sequential(
nn.Hardswish(inplace=False),
nn.Conv2d(
dim,
dim,
kernel_size=3,
padding=1,
groups=dim,
),
)
@lru_cache(maxsize=4)
def _generate_attn_mask(self, h: int, hp: int, device):
x = torch.empty(hp, hp, device=device).fill_(-100.0)
x[:h, :h] = 0
return x
def _cross_shaped_attention(
self,
q: Tensor,
k: Tensor,
v: Tensor,
H: int,
W: int,
HP: int,
WP: int,
ws: int,
horizontal: bool = True,
):
B, N, C = q.shape
if C < self.dim_head: # half channels are smaller than the defined dim_head
dim_head = C
scale = dim_head ** -0.5
else:
scale = self.scale
dim_head = self.dim_head
if horizontal:
q, k, v = map(
lambda y: y.reshape(B, HP // ws, ws, W, C // dim_head, -1)
.permute(0, 1, 4, 2, 3, 5)
.flatten(3, 4),
(q, k, v),
)
else:
q, k, v = map(
lambda y: y.reshape(B, H, WP // ws, ws, C // dim_head, -1)
.permute(0, 2, 4, 3, 1, 5)
.flatten(3, 4),
(q, k, v),
)
attn = q.matmul(k.transpose(-2, -1)).mul(
scale
) # [B,H_2//ws,W_2//ws,h,(b1*b2+1)*(ws*ws),(b1*b2+1)*(ws*ws)]
## need to mask zero padding before softmax
if horizontal and HP != H:
attn_pad = attn[:, -1:] # [B, 1, num_heads, ws*W, ws*W]
mask = self._generate_attn_mask(
h=(ws - HP + H) * W, hp=attn.size(-2), device=attn.device
) # [ws*W, ws*W]
attn_pad = attn_pad + mask
attn = torch.cat([attn[:, :-1], attn_pad], dim=1)
if not horizontal and WP != W:
attn_pad = attn[:, -1:] # [B, 1, num_head, ws*H, ws*H]
mask = self._generate_attn_mask(
h=(ws - WP + W) * H, hp=attn.size(-2), device=attn.device
) # [ws*H, ws*H]
attn_pad = attn_pad + mask
attn = torch.cat([attn[:, :-1], attn_pad], dim=1)
attn = self.attend(attn)
attn = attn.matmul(v) # [B,H_2//ws,W_2//ws,h,(b1*b2+1)*(ws*ws),D//h]
attn = rearrange(
attn,
"B H h (b W) d -> B (H b) W (h d)"
if horizontal
else "B W h (b H) d -> B H (W b) (h d)",
b=ws,
) # [B,H_1, W_1,D]
if horizontal and HP != H:
attn = attn[:, :H, ...]
if not horizontal and WP != W:
attn = attn[:, :, :W, ...]
attn = attn.flatten(1, 2)
return attn
def forward(self, x: Tensor, H: int, W: int) -> Tensor:
def _inner_forward(x: Tensor) -> Tensor:
B = x.shape[0]
ws = self.ws
qv = self.to_qkv(x)
q, v = qv.chunk(2, dim=-1)
v_conv = (
self.parallel_conv(v.reshape(B, H, W, -1).permute(0, 3, 1, 2))
.flatten(2)
.transpose(-1, -2)
)
qh, qv = q.chunk(2, dim=-1)
vh, vv = v.chunk(2, dim=-1)
kh, kv = vh, vv # share key and value
# padding to a multple of window size
if H % ws != 0:
HP = int((H + ws - 1) / ws) * ws
qh = (
F.pad(
qh.transpose(-1, -2).reshape(B, -1, H, W),
pad=[0, 0, 0, HP - H],
)
.flatten(2, 3)
.transpose(-1, -2)
)
vh = (
F.pad(
vh.transpose(-1, -2).reshape(B, -1, H, W),
pad=[0, 0, 0, HP - H],
)
.flatten(2, 3)
.transpose(-1, -2)
)
kh = vh
else:
HP = H
if W % ws != 0:
WP = int((W + ws - 1) / ws) * ws
qv = (
F.pad(
qv.transpose(-1, -2).reshape(B, -1, H, W),
pad=[0, WP - W, 0, 0],
)
.flatten(2, 3)
.transpose(-1, -2)
)
vv = (
F.pad(
vv.transpose(-1, -2).reshape(B, -1, H, W),
pad=[0, WP - W, 0, 0],
)
.flatten(2, 3)
.transpose(-1, -2)
)
kv = vv
else:
WP = W
attn_h = self._cross_shaped_attention(
qh,
kh,
vh,
H,
W,
HP,
W,
ws,
horizontal=True,
)
attn_v = self._cross_shaped_attention(
qv,
kv,
vv,
H,
W,
H,
WP,
ws,
horizontal=False,
)
attn = torch.cat([attn_h, attn_v], dim=-1)
attn = attn.add(v_conv)
attn = self.attn_act(attn)
attn = self.to_out(attn)
attn = self.attn_bn(attn.flatten(0, 1)).view_as(attn)
return attn
if self.with_cp and x.requires_grad:
x = cp.checkpoint(_inner_forward, x)
else:
x = _inner_forward(x)
return x
def extra_repr(self) -> str:
s = f"window_size={
self.ws}"
return s
class HRViTBlock(nn.Module):
def __init__(
self,
in_dim: int = 64,
dim: int = 64,
heads: int = 2,
proj_dropout: float = 0.0,
mlp_ratio: float = 4.0,
drop_path: float = 0.0,
ws: int = 1,
with_cp: bool = False,
) -> None:
super().__init__()
self.with_cp = with_cp
# build layer normalization
self.attn_norm = nn.LayerNorm(in_dim)
# build attention layer
self.attn = HRViTAttention(
in_dim=in_dim,
dim=dim,
heads=heads,
ws=ws,
proj_drop=proj_dropout,
with_cp=with_cp,
)
# build diversity-enhanced shortcut DES
self.des = DES(
in_features=in_dim,
out_features=dim,
bias=True,
act_func=nn.GELU,
)
# build drop path
self.attn_drop_path = DropPath(drop_path) if drop_path > 0.0 else nn.Identity()
# build layer normalization
self.ffn_norm = nn.LayerNorm(in_dim)
# build FFN
self.ffn = MixCFN(
in_features=in_dim,
hidden_features=int(dim * mlp_ratio),
out_features=dim,
act_func=nn.GELU,
with_cp=with_cp,
)
# build drop path
self.ffn_drop_path = DropPath(drop_path) if drop_path > 0.0 else nn.Identity()
def forward(self, x: Tensor, H: int, W: int) -> Tensor:
# attention block
res = x
x = self.attn_norm(x)
x = self.attn(x, H, W)
x_des = self.des(res)
x = self.attn_drop_path(x.add(x_des)).add(res)
# ffn block
res = x
x = self.ffn_norm(x)
x = self.ffn(x, H, W)
x = self.ffn_drop_path(x).add(res)
return x
class HRViTPatchEmbed(nn.Module):
def __init__(
self,
in_channels: int = 3,
patch_size: _size = 3,
stride: int = 1,
dim: int = 64,
) -> None:
super().__init__()
self.patch_size = to_2tuple(patch_size)
self.dim = dim
self.proj = nn.Sequential(
nn.Conv2d(
in_channels,
dim,
kernel_size=1,
stride=1,
padding=0,
),
nn.Conv2d(
dim,
dim,
kernel_size=self.patch_size,
stride=stride,
padding=(self.patch_size[0] // 2, self.patch_size[1] // 2),
groups=dim,
),
)
self.norm = nn.LayerNorm(dim)
def forward(self, x: Tensor) -> Tuple[Tensor, int, int]:
x = self.proj(x)
H, W = x.shape[-2:]
x = x.flatten(2).transpose(1, 2)
x = self.norm(x)
return x, H, W
class HRViTFusionBlock(nn.Module):
def __init__(
self,
in_channels: Tuple[int] = (32, 64, 128, 256),
out_channels: Tuple[int] = (32, 64, 128, 256),
act_func: nn.Module = nn.GELU,
with_cp: bool = False,
) -> None:
super().__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.act_func = act_func
self.with_cp = with_cp
self.n_outputs = len(out_channels)
self._build_fuse_layers()
def _build_fuse_layers(self):
self.blocks = nn.ModuleList([])
n_inputs = len(self.in_channels)
for i, outc in enumerate(self.out_channels):
blocks = nn.ModuleList([])
start = 0
end = n_inputs
for j in range(start, end):
inc = self.in_channels[j]
if j == i:
blocks.append(nn.Identity())
elif j < i:
block = [
nn.Conv2d(
inc,
inc,
kernel_size=2 ** (i - j) + 1,
stride=2 ** (i - j),
dilation=1,
padding=2 ** (i - j) // 2,
groups=inc,
bias=False,
),
nn.BatchNorm2d(inc),
nn.Conv2d(
inc,
outc,
kernel_size=1,
stride=1,
dilation=1,
padding=0,
groups=1,
bias=True,
),
nn.BatchNorm2d(outc),
]
blocks.append(nn.Sequential(*block))
else:
block = [
nn.Conv2d(
inc,
outc,
kernel_size=1,
stride=1,
dilation=1,
padding=0,
groups=1,
bias=True,
),
nn.BatchNorm2d(outc),
]
block.append(
nn.Upsample(
scale_factor=2 ** (j - i),
mode="nearest",
),
)
blocks.append(nn.Sequential(*block))
self.blocks.append(blocks)
self.act = nn.ModuleList([self.act_func() for _ in self.out_channels])
def forward(
self,
x: Tuple[
Tensor,
],
) -> Tuple[Tensor,]:
out = [None] * len(self.blocks)
n_inputs = len(x)
for i, (blocks, act) in enumerate(zip(self.blocks, self.act)):
start = 0
end = n_inputs
for j, block in zip(range(start, end), blocks):
out[i] = block(x[j]) if out[i] is None else out[i] + block(x[j])
out[i] = act(out[i])
return out
class HRViTStem(nn.Module):
def __init__(
self,
in_channels: int,
out_channels: int,
kernel_size: _size = 3,
stride: _size = 4,
dilation: _size = 1,
groups: int = 1,
bias: bool = True,
) -> None:
super().__init__()
kernel_size = to_2tuple(kernel_size)
stride = to_2tuple(stride)
stride = (stride[0]//2, stride[1]//2)
dilation = to_2tuple(dilation)
# same padding
padding = [
(dilation[i] * (kernel_size[i] - 1) + 1) // 2
for i in range(len(kernel_size))
]
self.conv1 = nn.Conv2d(
in_channels,
out_channels // 2,
kernel_size,
stride=stride,
padding=padding,
dilation=dilation,
groups=groups,
bias=bias,
)
self.bn1 = nn.BatchNorm2d(out_channels // 2)
self.act1 = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(
out_channels // 2,
out_channels,
kernel_size,
stride=stride,
padding=padding,
dilation=dilation,
groups=groups,
bias=bias,
)
self.bn2 = nn.BatchNorm2d(out_channels)
self.act2 = nn.ReLU(inplace=True)
def forward(self, x: Tensor) -> Tensor:
x = self.act1(self.bn1(self.conv1(x)))
x = self.act2(self.bn2(self.conv2(x)))
return x
class HRViTStage(nn.Module):
def __init__(
self,
#### Patch Embed Config ####
in_channels: Tuple[
int,
] = (32, 64, 128, 256),
out_channels: Tuple[
int,
] = (32, 64, 128, 256),
block_list: Tuple[
int,
] = (1, 1, 6, 2),
#### HRViTAttention Config ####
dim_head: int = 32,
ws_list: Tuple[
int,
] = (1, 2, 7, 7),
proj_dropout: float = 0.0,
drop_path_rates: Tuple[float] = (
0.0,
), # different droprate for different attn/mlp
#### MixCFN Config ####
mlp_ratio_list: Tuple[
int,
] = (4, 4, 4, 4),
dropout: float = 0.0,
#### Gradient Checkpointing #####
with_cp: bool = False,
) -> None:
super().__init__()
self.patch_embed = nn.ModuleList(
[
HRViTPatchEmbed(
in_channels=inc,
patch_size=3,
stride=1,
dim=outc,
)
for inc, outc in zip(in_channels, out_channels)
]
) # one patch embedding for each branch
## we arrange blocks in stages/layers
n_inputs = len(out_channels)
self.branches = nn.ModuleList([])
for i, n_blocks in enumerate(block_list[:n_inputs]):
blocks = []
for j in range(n_blocks):
blocks += [
HRViTBlock(
in_dim=out_channels[i],
dim=out_channels[i],
heads=out_channels[i] // dim_head, # automatically derive heads
proj_dropout=proj_dropout,
mlp_ratio=mlp_ratio_list[i],
drop_path=drop_path_rates[j],
ws=ws_list[i],
with_cp=with_cp,
)
]
blocks = nn.ModuleList(blocks)
self.branches.append(blocks)
self.norm = nn.ModuleList([nn.LayerNorm(outc) for outc in out_channels])
def forward(
self,
x: Tuple[
Tensor,
],
) -> Tuple[Tensor,]:
B = x[0].shape[0]
x = list(x)
H, W = [], []
## patch embed
for i, (xx, embed) in enumerate(zip(x, self.patch_embed)):
xx, h, w = embed(xx)
x[i] = xx
H.append(h)
W.append(w)
## HRViT blocks
for i, (branch, h, w) in enumerate(zip(self.branches, H, W)):
for block in branch:
x[i] = block(x[i], h, w)
## LN at the end of each stage
for i, (xx, norm, h, w) in enumerate(zip(x, self.norm, H, W)):
xx = norm(xx)
xx = xx.reshape(B, h, w, -1).permute(0, 3, 1, 2).contiguous()
x[i] = xx
return x
class HRViT(nn.Module):
def __init__(
self,
#### HRViT Stem Config ####
in_channels: int = 3,
stride: int = 4,
channels: int = 64,
#### Branch Config ####
channel_list: Tuple[Tuple[int,],] = (
(32,),
(32, 64),
(32, 64, 128),
(32, 64, 128),
(32, 64, 128, 256),
(32, 64, 128, 256),
),
block_list: Tuple[Tuple[int]] = (
(1,),
(1, 1),
(1, 1, 6),
(1, 1, 6),
(1, 1, 6, 2),
(1, 1, 2, 2),
),
#### HRViTAttention Config ####
dim_head: int = 32,
ws_list: Tuple[
int,
] = (1, 2, 7, 7),
proj_dropout: float = 0.0,
drop_path_rate: float = 0.0, # different droprate for different attn/mlp
#### HRViTFeedForward Config ####
mlp_ratio_list: Tuple[
int,
] = (4, 4, 4, 4),
dropout: float = 0.0,
#### Classification Head Config ####
num_classes: int = 1000,
head_dropout: float = 0.1,
#### Gradient Checkpointing #####
with_cp: bool = False,
) -> None:
super().__init__()
self.features = []
self.ws_list = ws_list
self.head_dropout = head_dropout
self.with_cp = with_cp
# calculate drop path rates
total_blocks = sum(max(b) for b in block_list)
total_drop_path_rates = (
torch.linspace(0, drop_path_rate, total_blocks).numpy().tolist()
)
cur = 0
self.channel_list = channel_list = [[channels]] + list(channel_list)
# build stem
self.stem = HRViTStem(
in_channels=in_channels, out_channels=channels, kernel_size=3, stride=4
)
# build backbone
for i, blocks in enumerate(block_list):
inc, outc = channel_list[i : i + 2]
depth_per_stage = max(blocks)
self.features.extend(
[
HRViTFusionBlock(
in_channels=inc,
out_channels=inc
if len(inc) == len(outc)
else list(inc) + [outc[-1]],
act_func=nn.GELU,
with_cp=False,
),
HRViTStage(
#### Patch Embed Config ####
in_channels=inc
if len(inc) == len(outc)
else list(inc) + [outc[-1]],
out_channels=outc,
block_list=blocks,
dim_head=dim_head,
#### HRViTBlock Config ####
ws_list=ws_list,
proj_dropout=proj_dropout,
drop_path_rates=total_drop_path_rates[
cur : cur + depth_per_stage
], # different droprate for different attn/mlp
#### MixCFN Config ####
mlp_ratio_list=mlp_ratio_list,
dropout=dropout,
#### Gradient Checkpointing #####
with_cp=with_cp,
),
]
)
cur += depth_per_stage
self.features = nn.Sequential(*self.features)
# build classification head
self.head = HRViTClassifier(
in_channels=channel_list[-1],
num_classes=num_classes,
dropout=head_dropout,
)
@torch.jit.ignore
def no_weight_decay(self):
return {
"pos_embed", "cls_token"}
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=""):
if self.num_classes != num_classes:
logger.info("Reset head to", num_classes)
self.num_classes = num_classes
self.head = HRViTClassifier(
in_channels=self.channel_list[-1],
num_classes=num_classes,
dropout=self.head_dropout,
).cuda()
def forward_features(
self, x: Tensor
) -> Tuple[Tensor,]:
# stem
x = self.stem(x)
# backbone
x = self.features((x,))
return x
def forward(self, x: Tensor) -> Tensor:
# stem and backbone
x = self.forward_features(x)
# classifier
x = self.head(x)
return x
@register_model
def HRViT_b1_224(pretrained=False, **kwargs):
model = HRViT(
stride=4,
channels=64,
channel_list=(
(32,),
(32, 64),
(32, 64, 128),
(32, 64, 128),
(32, 64, 128, 256),
(32, 64, 128, 256),
),
block_list=(
(1,),
(1, 1),
(1, 1, 6),
(1, 1, 6),
(1, 1, 6, 2),
(1, 1, 2, 2),
),
dim_head=32,
ws_list=(1, 2, 7, 7),
proj_dropout=0.0,
# drop_path_rate=0.1,
mlp_ratio_list=(4, 4, 4, 4),
dropout=0.0,
# head_dropout=0.1,
**kwargs,
)
model.default_cfg = default_cfgs["hrvit_224"]
return model
@register_model
def HRViT_b2_224(pretrained=False, **kwargs):
model = HRViT(
stride=4,
channels=64,
channel_list=(
(48,),
(48, 96),
(48, 96, 240),
(48, 96, 240),
(48, 96, 240, 384),
(48, 96, 240, 384),
),
block_list=(
(1,),
(1, 1),
(1, 1, 6),
(1, 1, 6),
(1, 1, 6, 2),
(1, 1, 6, 2),
),
dim_head=24,
ws_list=(1, 2, 7, 7),
proj_dropout=0.0,
# drop_path_rate=0.1,
mlp_ratio_list=(2, 3, 3, 3),
dropout=0.0,
# head_dropout=0.1,
**kwargs,
)
model.default_cfg = default_cfgs["hrvit_224"]
return model
@register_model
def HRViT_b3_224(pretrained=False, **kwargs):
model = HRViT(
stride=4,
channels=64,
channel_list=(
(64,),
(64, 128),
(64, 128, 256),
(64, 128, 256),
(64, 128, 256, 512),
(64, 128, 256, 512),
),
block_list=(
(1,),
(1, 1),
(1, 1, 6),
(1, 1, 6),
(1, 1, 6, 3),
(1, 1, 6, 3),
),
dim_head=32,
ws_list=(1, 2, 7, 7),
proj_dropout=0.0,
# drop_path_rate=0.1,
mlp_ratio_list=(2, 2, 2, 2),
dropout=0.0,
# head_dropout=0.1,
**kwargs,
)
model.default_cfg = default_cfgs["hrvit_224"]
return model
if __name__ == '__main__':
from thop import profile
model = HRViT_b1_224(num_classes=1000)
input = torch.randn(1, 3, 224, 224)
flops, params = profile(model, inputs=(input,))
print("flops:{:.3f}G".format(flops/1e9))
print("params:{:.3f}M".format(params/1e6))
参考资料
Facebook提出HRViT:多尺度高分辨率视觉Transformer - 知乎 (zhihu.com)
【CVPR2022】Multi-Scale High-Resolution Vision Transformer for Semantic Segmentation - 知乎 (zhihu.com)
边栏推荐
猜你喜欢

![[Kali Security Penetration Testing Practice Course] Chapter 8 Web Penetration](/img/5f/907057956658a19306da21c71185ea.png)




随机推荐
781. 森林中的兔子
从滑动标尺模型看企业网络安全能力评估与建设
【红队】ATT&CK - 自启动 - 注册表运行键、启动文件夹
手把手教你搭建ELK-新手必看-第一章:什么是ELK?
liunx PS1 设置
2022杭电多校联赛第七场 题解
Robust Real-time LiDAR-inertial Initialization(实时鲁棒的LiDAR惯性初始化)论文学习
How Microbes Affect Physical Health
T5:Text-toText Transfer Transformer
【红队】ATT&CK - 自启动 - 利用LSA身份验证包自启动机制
程序员的专属浪漫——用3D Engine 5分钟实现烟花绽放效果
Shell编程--awk
xss的DOMPurify过滤框架:一个循环问题以及两个循环问题
MySQL:日志系统介绍 | 错误日志 | 查询日志 | 二进制日志:bin-log数据恢复实践 | 慢日志查询
2022.8.8 Exam written in memory (memory)
【图像分类】2022-CycleMLP ICLR
one of the variables needed for gradient computation has been modified by an inplace
16. 最接近的三数之和
IDEA自动生成serialVersionUID
【Kali安全渗透测试实践教程】第9章 无线网络渗透