当前位置:网站首页>【图像分类】2022-CycleMLP ICLR
【图像分类】2022-CycleMLP ICLR
2022-08-10 02:03:00 【說詤榢】
【图像分类】2022-CycleMLP ICLR
论文题目:CycleMLP: A MLP-like Architecture for Dense Prediction
论文链接:https://arxiv.org/abs/2107.10224
代码链接:https://github.com/ShoufaChen/CycleMLP
视频讲解:https://www.bilibili.com/video/BV1UA4y1Q7Sc
发表时间:2021年7月
作者团队:香港大学
引用:Chen S, Xie E, Ge C, et al. Cyclemlp: A mlp-like architecture for dense prediction[J]. arXiv preprint arXiv:2107.10224, 2021.
引用数:53
1. 简介
1.1 简介
Transformer之后,基于MLP的网络结构设计引起了一波新的研究热潮。这种没有Attention的结构在多个领域任务取得了不凡的结果。
具体分享提纲如下:
- 普通MLP网络结构(MLP-Mixer, gMLP, ResMLP等)的局限性
- Cycle MLP,一种通用的MLP结构
- MLP结构的广泛应用
1.2 摘要
CycleMLP是AS-MLP之外的另外一个可以作为通用骨架的MLP架构(AS-MLP是首个迁移到下游任务的 MLP 架构),MLP-Mixer, ResMLP 与gMLP架构与图像大小相关,因为其不能作为下游任务的通用骨干。
与现在的MLP方法相比,CycleMLP有两个优点:
1)可以处理各种图像大小
2)利用局部窗口实现图像大小的线性计算复杂度。相比之下,以往的mlp具有二次计算复杂度,因为它们空间上的全连接。
作者扩展了MLP架构的适用性,使其成为密集预测任务的通用主干。性能效果:
- 83.2% accuracy on ImageNet-1K classification ( Swin Transformer 83.3%)
- achieves 45.1 mIoU on ADE20K val(Swin 45.2 mIOU)
1.3 存在的问题
尽管在视觉识别任务中得到了很好的结果,但由于两个原因,这些mlp类模型不能用于其他下游任务(比如目标检测与语义分割):
1)这样的模型由具有相同架构的块组成,导致在低分辨率下具有单一尺度的特征。因此,非层次结构使得模型无法提供金字塔特征表示。
2)这些模型无法处理灵活的输入尺度,因此在训练和验证阶段都需要一个固定的输入规模。
3)Spatial FC的计算复杂度是图像大小的平方,这使得现有的mlp类模型难以在高分辨率图像上实现。
对于第一个问题,作者构建了一个层次结构来生成金字塔特征表示。对于第二三个问题,作者提出了一个全连接层的新变种,命名为循环全连接层(Cycle FC),Cycle FC能够处理可变的图像尺度,对图像大小具有线性的计算复杂度。
对于Spatial FC来说,由于需要限定patch的HW大小,所以无法做到可变处理,但是感受野较大,复杂度也较大;而Channel FC,由于线性投影的维度是可以设定的,没有信息交互的过程,但是复杂度较小,所以可以做到可变处理。
2. 网络
2.1 网络架构
类似的,对于输入图像为HxWxC的图像,通过带有重叠的卷积变成一系列的patch(卷积核为7,步长为4,带重叠的卷积效果会更好),然后对channel进行一个线性投影成(H/4)x(W/4)xC。然后,依次在patch tokens上应用几个Cycle FC block,具有相同架构的block被堆叠成一个Stage。在每个Stage中维护token的数量(特征规模)。而在每个阶段转换中,在tokens数量减少的同时,所处理的tokens的channel维度得到扩展。通过该策略有效降低了空间分辨率的复杂性。

- patch embedding module: window size 7, stride 4,最终特征下采样四倍。
- 中间通过跨步卷积实现 2 倍下采样。
- 最终输出为下采样 32 倍的特征。
- 最终使用一个全连接层整合所有 token 的特征。
2.2 CycleFC Block
Cycle FC block由三个并行的Cycle FC算子组成,然后是一个具有两个线性层和中间一个GELU非线性的channel mlp。

Channel FC由特定层的内外通道维度配置。它的结构与图像的尺度无关。因此它是一种尺度不可知的操作,可以处理输入图像的可变尺度,这对于密集预测任务是必不可少的。此外,信道FC的另一个优点是它对图像尺度的线性计算复杂度。然而,它的感受野有限,不能聚合足够的上下文,Channel FC由于缺乏上下文信息而产生较差的结果。
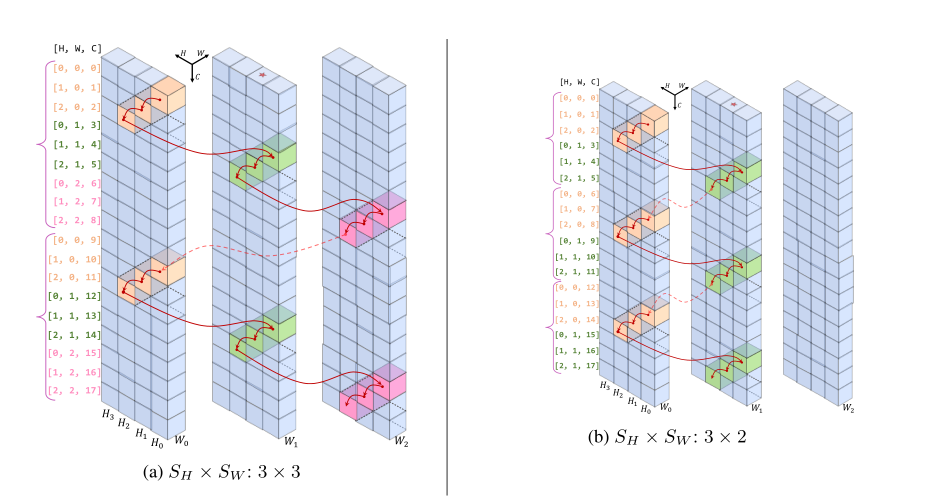
为了在保持计算复杂度的同时扩大感受野,Cycle FC被设计成与Channels FC一样沿着Channels维度进行全连接,但是并不是采样点都位于相同空间位置,而是以阶梯式风格采样点。
import os
import torch
import torch.nn as nn
from timm.data import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
from timm.models.layers import DropPath, trunc_normal_
from timm.models.layers.helpers import to_2tuple
import math
from torch import Tensor
from torch.nn import init
from torch.nn.modules.utils import _pair
from torchvision.ops.deform_conv import deform_conv2d as deform_conv2d_tv
class CycleFC(nn.Module):
def __init__(
self,
in_channels: int,
out_channels: int,
kernel_size, # re-defined kernel_size, represent the spatial area of staircase FC
stride: int = 1,
padding: int = 0,
dilation: int = 1,
groups: int = 1,
bias: bool = True,
):
""" 这里的kernel_size实际使用的时候时3x1或者1x3 """
super(CycleFC, self).__init__()
if in_channels % groups != 0:
raise ValueError('in_channels must be divisible by groups')
if out_channels % groups != 0:
raise ValueError('out_channels must be divisible by groups')
if stride != 1:
raise ValueError('stride must be 1')
if padding != 0:
raise ValueError('padding must be 0')
self.in_channels = in_channels
self.out_channels = out_channels
self.kernel_size = kernel_size
self.stride = _pair(stride)
self.padding = _pair(padding)
self.dilation = _pair(dilation)
self.groups = groups
# 被偏移调整的1x1卷积的权重,由于后面使用torchvision提供的可变形卷积的函数,所以权重需要自己构造
self.weight = nn.Parameter(torch.empty(out_channels, in_channels // groups, 1, 1))
# kernel size == 1
if bias:
self.bias = nn.Parameter(torch.empty(out_channels))
else:
self.register_parameter('bias', None)
# 要注意,这里是在注册一个buffer,是一个常量,不可学习,但是可以保存到模型权重中。
self.register_buffer('offset', self.gen_offset())
def gen_offset(self):
""" 生成卷积核偏移量的核心操作。 要想理解这一函数的操作,需要首先理解后面使用的deform_conv2d_tv的具体用法。 具体可见:https://pytorch.org/vision/0.10/ops.html#torchvision.ops.deform_conv2d 这里对于offset参数的要求是: offset (Tensor[batch_size, 2 * offset_groups * kernel_height * kernel_width, out_height, out_width]) – offsets to be applied for each position in the convolution kernel. 也就是说,对于样本s的输出特征图的通道c中的位置(x,y),这个函数会从offset中取出,形状为 kernel_height*kernel_width的卷积核所对应的偏移参数为 offset[s, 0:2*offset_groups*kernel_height*kernel_width, x, y] 也就是这一系列参数都是对应样本s的单个位置(x,y)的。 针对不同的位置可以有不同的offset,也可以有相同的(下面的实现就是后者)。 对于这2*offset_groups*kernel_height*kernel_width个数,涉及到对于输入特征通道的分组。 将其分成offset_groups组,每份单独拥有一组对应于卷积核中心位置的相对偏移量, 共2*kernel_height*kernel_width个数。 对于每个核参数,使用两个量来描述偏移,即h方向和w方向相对中心位置的偏移, 即下面代码中的减去kernel_height//2或者kernel_width//2。 需要注意的是,当偏移位置位于padding后的tensor边界外,则是将网格使用0补齐。 如果网格上有边界值,则使用边界值和用0补齐的网格顶点来计算双线性插值的结果。 """
offset = torch.empty(1, self.in_channels*2, 1, 1)
start_idx = (self.kernel_size[0] * self.kernel_size[1]) // 2
assert self.kernel_size[0] == 1 or self.kernel_size[1] == 1, self.kernel_size
for i in range(self.in_channels):
if self.kernel_size[0] == 1:
offset[0, 2 * i + 0, 0, 0] = 0
# 这里计算了一个相对偏移位置。
# deform_conv2d使用的以对应输出位置为中心的偏移坐标索引方式
offset[0, 2 * i + 1, 0, 0] = (
(i + start_idx) % self.kernel_size[1] - (self.kernel_size[1] // 2)
)
else:
offset[0, 2 * i + 0, 0, 0] = (
(i + start_idx) % self.kernel_size[0] - (self.kernel_size[0] // 2)
)
offset[0, 2 * i + 1, 0, 0] = 0
return offset
def forward(self, input: Tensor) -> Tensor:
""" Args: input (Tensor[batch_size, in_channels, in_height, in_width]): input tensor """
B, C, H, W = input.size()
return deform_conv2d_tv(input,
self.offset.expand(B, -1, H, W),
self.weight,
self.bias,
stride=self.stride,
padding=self.padding,
dilation=self.dilation)
class CycleMLP(nn.Module):
def __init__(self, dim, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.mlp_c = nn.Linear(dim, dim, bias=qkv_bias)
self.sfc_h = CycleFC(dim, dim, (1, 3), 1, 0)
self.sfc_w = CycleFC(dim, dim, (3, 1), 1, 0)
self.reweight = Mlp(dim, dim // 4, dim * 3)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, H, W, C = x.shape
h = self.sfc_h(x.permute(0, 3, 1, 2)).permute(0, 2, 3, 1)
w = self.sfc_w(x.permute(0, 3, 1, 2)).permute(0, 2, 3, 1)
c = self.mlp_c(x)
a = (h + w + c).permute(0, 3, 1, 2).flatten(2).mean(2)
a = self.reweight(a).reshape(B, C, 3).permute(2, 0, 1).softmax(dim=0).unsqueeze(2).unsqueeze(2)
x = h * a[0] + w * a[1] + c * a[2]
x = self.proj(x)
x = self.proj_drop(x)
return x
class CycleBlock(nn.Module):
def __init__(self, dim, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, skip_lam=1.0, mlp_fn=CycleMLP):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = mlp_fn(dim, qkv_bias=qkv_bias, qk_scale=None, attn_drop=attn_drop)
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer)
self.skip_lam = skip_lam
def forward(self, x):
x = x + self.drop_path(self.attn(self.norm1(x))) / self.skip_lam
x = x + self.drop_path(self.mlp(self.norm2(x))) / self.skip_lam
return x
、
没怎么看懂Cycle FC算子怎么运行的?
文章还给了不同的step_size的效果?当伪内核大小配置为1×1时,Cycle FC退化为普通Channels FC

3. 代码
import os
import torch
import torch.nn as nn
from timm.data import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
from timm.models.layers import DropPath, trunc_normal_
from timm.models.layers.helpers import to_2tuple
import math
from torch import Tensor
from torch.nn import init
from torch.nn.modules.utils import _pair
from torchvision.ops.deform_conv import deform_conv2d as deform_conv2d_tv
def _cfg(url='', **kwargs):
return {
'url': url,
'num_classes': 1000, 'input_size': (3, 224, 224), 'pool_size': None,
'crop_pct': .96, 'interpolation': 'bicubic',
'mean': IMAGENET_DEFAULT_MEAN, 'std': IMAGENET_DEFAULT_STD, 'classifier': 'head',
**kwargs
}
default_cfgs = {
'cycle_S': _cfg(crop_pct=0.9),
'cycle_M': _cfg(crop_pct=0.9),
'cycle_L': _cfg(crop_pct=0.875),
}
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class CycleFC(nn.Module):
""" """
def __init__(
self,
in_channels: int,
out_channels: int,
kernel_size, # re-defined kernel_size, represent the spatial area of staircase FC
stride: int = 1,
padding: int = 0,
dilation: int = 1,
groups: int = 1,
bias: bool = True,
):
super(CycleFC, self).__init__()
if in_channels % groups != 0:
raise ValueError('in_channels must be divisible by groups')
if out_channels % groups != 0:
raise ValueError('out_channels must be divisible by groups')
if stride != 1:
raise ValueError('stride must be 1')
if padding != 0:
raise ValueError('padding must be 0')
self.in_channels = in_channels
self.out_channels = out_channels
self.kernel_size = kernel_size
self.stride = _pair(stride)
self.padding = _pair(padding)
self.dilation = _pair(dilation)
self.groups = groups
self.weight = nn.Parameter(torch.empty(out_channels, in_channels // groups, 1, 1)) # kernel size == 1
if bias:
self.bias = nn.Parameter(torch.empty(out_channels))
else:
self.register_parameter('bias', None)
self.register_buffer('offset', self.gen_offset())
self.reset_parameters()
def reset_parameters(self) -> None:
init.kaiming_uniform_(self.weight, a=math.sqrt(5))
if self.bias is not None:
fan_in, _ = init._calculate_fan_in_and_fan_out(self.weight)
bound = 1 / math.sqrt(fan_in)
init.uniform_(self.bias, -bound, bound)
def gen_offset(self):
""" offset (Tensor[batch_size, 2 * offset_groups * kernel_height * kernel_width, out_height, out_width]): offsets to be applied for each position in the convolution kernel. """
offset = torch.empty(1, self.in_channels*2, 1, 1)
start_idx = (self.kernel_size[0] * self.kernel_size[1]) // 2
assert self.kernel_size[0] == 1 or self.kernel_size[1] == 1, self.kernel_size
for i in range(self.in_channels):
if self.kernel_size[0] == 1:
offset[0, 2 * i + 0, 0, 0] = 0
offset[0, 2 * i + 1, 0, 0] = (i + start_idx) % self.kernel_size[1] - (self.kernel_size[1] // 2)
else:
offset[0, 2 * i + 0, 0, 0] = (i + start_idx) % self.kernel_size[0] - (self.kernel_size[0] // 2)
offset[0, 2 * i + 1, 0, 0] = 0
return offset
def forward(self, input: Tensor) -> Tensor:
""" Args: input (Tensor[batch_size, in_channels, in_height, in_width]): input tensor """
B, C, H, W = input.size()
return deform_conv2d_tv(input, self.offset.expand(B, -1, H, W), self.weight, self.bias, stride=self.stride,
padding=self.padding, dilation=self.dilation)
def extra_repr(self) -> str:
s = self.__class__.__name__ + '('
s += '{in_channels}'
s += ', {out_channels}'
s += ', kernel_size={kernel_size}'
s += ', stride={stride}'
s += ', padding={padding}' if self.padding != (0, 0) else ''
s += ', dilation={dilation}' if self.dilation != (1, 1) else ''
s += ', groups={groups}' if self.groups != 1 else ''
s += ', bias=False' if self.bias is None else ''
s += ')'
return s.format(**self.__dict__)
class CycleMLP(nn.Module):
def __init__(self, dim, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.mlp_c = nn.Linear(dim, dim, bias=qkv_bias)
self.sfc_h = CycleFC(dim, dim, (1, 3), 1, 0)
self.sfc_w = CycleFC(dim, dim, (3, 1), 1, 0)
self.reweight = Mlp(dim, dim // 4, dim * 3)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, H, W, C = x.shape
h = self.sfc_h(x.permute(0, 3, 1, 2)).permute(0, 2, 3, 1)
w = self.sfc_w(x.permute(0, 3, 1, 2)).permute(0, 2, 3, 1)
c = self.mlp_c(x)
a = (h + w + c).permute(0, 3, 1, 2).flatten(2).mean(2)
a = self.reweight(a).reshape(B, C, 3).permute(2, 0, 1).softmax(dim=0).unsqueeze(2).unsqueeze(2)
x = h * a[0] + w * a[1] + c * a[2]
x = self.proj(x)
x = self.proj_drop(x)
return x
class CycleBlock(nn.Module):
def __init__(self, dim, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, skip_lam=1.0, mlp_fn=CycleMLP):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = mlp_fn(dim, qkv_bias=qkv_bias, qk_scale=None, attn_drop=attn_drop)
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer)
self.skip_lam = skip_lam
def forward(self, x):
x = x + self.drop_path(self.attn(self.norm1(x))) / self.skip_lam
x = x + self.drop_path(self.mlp(self.norm2(x))) / self.skip_lam
return x
class PatchEmbedOverlapping(nn.Module):
""" 2D Image to Patch Embedding with overlapping """
def __init__(self, patch_size=16, stride=16, padding=0, in_chans=3, embed_dim=768, norm_layer=None, groups=1):
super().__init__()
patch_size = to_2tuple(patch_size)
stride = to_2tuple(stride)
padding = to_2tuple(padding)
self.patch_size = patch_size
# remove image_size in model init to support dynamic image size
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=stride, padding=padding, groups=groups)
self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()
def forward(self, x):
x = self.proj(x)
return x
class Downsample(nn.Module):
""" Downsample transition stage """
def __init__(self, in_embed_dim, out_embed_dim, patch_size):
super().__init__()
assert patch_size == 2, patch_size
self.proj = nn.Conv2d(in_embed_dim, out_embed_dim, kernel_size=(3, 3), stride=(2, 2), padding=1)
def forward(self, x):
x = x.permute(0, 3, 1, 2)
x = self.proj(x) # B, C, H, W
x = x.permute(0, 2, 3, 1)
return x
def basic_blocks(dim, index, layers, mlp_ratio=3., qkv_bias=False, qk_scale=None, attn_drop=0.,
drop_path_rate=0., skip_lam=1.0, mlp_fn=CycleMLP, **kwargs):
blocks = []
for block_idx in range(layers[index]):
block_dpr = drop_path_rate * (block_idx + sum(layers[:index])) / (sum(layers) - 1)
blocks.append(CycleBlock(dim, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, drop_path=block_dpr, skip_lam=skip_lam, mlp_fn=mlp_fn))
blocks = nn.Sequential(*blocks)
return blocks
class CycleNet(nn.Module):
""" CycleMLP Network """
def __init__(self, layers, img_size=224, patch_size=4, in_chans=3, num_classes=1000,
embed_dims=None, transitions=None, segment_dim=None, mlp_ratios=None, skip_lam=1.0,
qkv_bias=False, qk_scale=None, drop_rate=0., attn_drop_rate=0., drop_path_rate=0.,
norm_layer=nn.LayerNorm, mlp_fn=CycleMLP, fork_feat=False):
super().__init__()
if not fork_feat:
self.num_classes = num_classes
self.fork_feat = fork_feat
self.patch_embed = PatchEmbedOverlapping(patch_size=7, stride=4, padding=2, in_chans=3, embed_dim=embed_dims[0])
network = []
for i in range(len(layers)):
stage = basic_blocks(embed_dims[i], i, layers, mlp_ratio=mlp_ratios[i], qkv_bias=qkv_bias,
qk_scale=qk_scale, attn_drop=attn_drop_rate, drop_path_rate=drop_path_rate,
norm_layer=norm_layer, skip_lam=skip_lam, mlp_fn=mlp_fn)
network.append(stage)
if i >= len(layers) - 1:
break
if transitions[i] or embed_dims[i] != embed_dims[i+1]:
patch_size = 2 if transitions[i] else 1
network.append(Downsample(embed_dims[i], embed_dims[i+1], patch_size))
self.network = nn.ModuleList(network)
if self.fork_feat:
# add a norm layer for each output
self.out_indices = [0, 2, 4, 6]
for i_emb, i_layer in enumerate(self.out_indices):
if i_emb == 0 and os.environ.get('FORK_LAST3', None):
# TODO: more elegant way
"""For RetinaNet, `start_level=1`. The first norm layer will not used. cmd: `FORK_LAST3=1 python -m torch.distributed.launch ...` """
layer = nn.Identity()
else:
layer = norm_layer(embed_dims[i_emb])
layer_name = f'norm{
i_layer}'
self.add_module(layer_name, layer)
else:
# Classifier head
self.norm = norm_layer(embed_dims[-1])
self.head = nn.Linear(embed_dims[-1], num_classes) if num_classes > 0 else nn.Identity()
self.apply(self.cls_init_weights)
def cls_init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, CycleFC):
trunc_normal_(m.weight, std=.02)
nn.init.constant_(m.bias, 0)
def init_weights(self, pretrained=None):
""" mmseg or mmdet `init_weight` """
if isinstance(pretrained, str):
pass
# logger = get_root_logger()
# load_checkpoint(self, pretrained, map_location='cpu', strict=False, logger=logger)
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=''):
self.num_classes = num_classes
self.head = nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()
def forward_embeddings(self, x):
x = self.patch_embed(x)
# B,C,H,W-> B,H,W,C
x = x.permute(0, 2, 3, 1)
return x
def forward_tokens(self, x):
outs = []
for idx, block in enumerate(self.network):
x = block(x)
if self.fork_feat and idx in self.out_indices:
norm_layer = getattr(self, f'norm{
idx}')
x_out = norm_layer(x)
outs.append(x_out.permute(0, 3, 1, 2).contiguous())
if self.fork_feat:
return outs
B, H, W, C = x.shape
x = x.reshape(B, -1, C)
return x
def forward(self, x):
x = self.forward_embeddings(x)
# B, H, W, C -> B, N, C
x = self.forward_tokens(x)
if self.fork_feat:
return x
x = self.norm(x)
cls_out = self.head(x.mean(1))
return cls_out
def CycleMLP_B1(pretrained=False, **kwargs):
transitions = [True, True, True, True]
layers = [2, 2, 4, 2]
mlp_ratios = [4, 4, 4, 4]
embed_dims = [64, 128, 320, 512]
model = CycleNet(layers, embed_dims=embed_dims, patch_size=7, transitions=transitions,
mlp_ratios=mlp_ratios, mlp_fn=CycleMLP, **kwargs)
model.default_cfg = default_cfgs['cycle_S']
return model
def CycleMLP_B2(pretrained=False, **kwargs):
transitions = [True, True, True, True]
layers = [2, 3, 10, 3]
mlp_ratios = [4, 4, 4, 4]
embed_dims = [64, 128, 320, 512]
model = CycleNet(layers, embed_dims=embed_dims, patch_size=7, transitions=transitions,
mlp_ratios=mlp_ratios, mlp_fn=CycleMLP, **kwargs)
model.default_cfg = default_cfgs['cycle_S']
return model
def CycleMLP_B3(pretrained=False, **kwargs):
transitions = [True, True, True, True]
layers = [3, 4, 18, 3]
mlp_ratios = [8, 8, 4, 4]
embed_dims = [64, 128, 320, 512]
model = CycleNet(layers, embed_dims=embed_dims, patch_size=7, transitions=transitions,
mlp_ratios=mlp_ratios, mlp_fn=CycleMLP, **kwargs)
model.default_cfg = default_cfgs['cycle_M']
return model
def CycleMLP_B4(pretrained=False, **kwargs):
transitions = [True, True, True, True]
layers = [3, 8, 27, 3]
mlp_ratios = [8, 8, 4, 4]
embed_dims = [64, 128, 320, 512]
model = CycleNet(layers, embed_dims=embed_dims, patch_size=7, transitions=transitions,
mlp_ratios=mlp_ratios, mlp_fn=CycleMLP, **kwargs)
model.default_cfg = default_cfgs['cycle_L']
return model
def CycleMLP_B5(pretrained=False, **kwargs):
transitions = [True, True, True, True]
layers = [3, 4, 24, 3]
mlp_ratios = [4, 4, 4, 4]
embed_dims = [96, 192, 384, 768]
model = CycleNet(layers, embed_dims=embed_dims, patch_size=7, transitions=transitions,
mlp_ratios=mlp_ratios, mlp_fn=CycleMLP, **kwargs)
model.default_cfg = default_cfgs['cycle_L']
return model
class CycleMLP_B1_feat(CycleNet):
def __init__(self, **kwargs):
transitions = [True, True, True, True]
layers = [2, 2, 4, 2]
mlp_ratios = [4, 4, 4, 4]
embed_dims = [64, 128, 320, 512]
super(CycleMLP_B1_feat, self).__init__(layers, embed_dims=embed_dims, patch_size=7, transitions=transitions,
mlp_ratios=mlp_ratios, mlp_fn=CycleMLP, fork_feat=True)
class CycleMLP_B2_feat(CycleNet):
def __init__(self, **kwargs):
transitions = [True, True, True, True]
layers = [2, 3, 10, 3]
mlp_ratios = [4, 4, 4, 4]
embed_dims = [64, 128, 320, 512]
super(CycleMLP_B2_feat, self).__init__(layers, embed_dims=embed_dims, patch_size=7, transitions=transitions,
mlp_ratios=mlp_ratios, mlp_fn=CycleMLP, fork_feat=True)
class CycleMLP_B3_feat(CycleNet):
def __init__(self, **kwargs):
transitions = [True, True, True, True]
layers = [3, 4, 18, 3]
mlp_ratios = [8, 8, 4, 4]
embed_dims = [64, 128, 320, 512]
super(CycleMLP_B3_feat, self).__init__(layers, embed_dims=embed_dims, patch_size=7, transitions=transitions,
mlp_ratios=mlp_ratios, mlp_fn=CycleMLP, fork_feat=True)
class CycleMLP_B4_feat(CycleNet):
def __init__(self, **kwargs):
transitions = [True, True, True, True]
layers = [3, 8, 27, 3]
mlp_ratios = [8, 8, 4, 4]
embed_dims = [64, 128, 320, 512]
super(CycleMLP_B4_feat, self).__init__(layers, embed_dims=embed_dims, patch_size=7, transitions=transitions,
mlp_ratios=mlp_ratios, mlp_fn=CycleMLP, fork_feat=True)
class CycleMLP_B5_feat(CycleNet):
def __init__(self, **kwargs):
transitions = [True, True, True, True]
layers = [3, 4, 24, 3]
mlp_ratios = [4, 4, 4, 4]
embed_dims = [96, 192, 384, 768]
super(CycleMLP_B5_feat, self).__init__(layers, embed_dims=embed_dims, patch_size=7, transitions=transitions,
mlp_ratios=mlp_ratios, mlp_fn=CycleMLP, fork_feat=True)
边栏推荐
- Open3D 中点细分(网格细分)
- 2022.8.9考试游记总结
- 【二叉树-中等】1379. 找出克隆二叉树中的相同节点
- 2022.8.9 Exam Cube Sum--1100 Question Solutions
- T5:Text-toText Transfer Transformer
- Write a drop-down refresh component
- Redis - Basic operations and usage scenarios of String|Hash|List|Set|Zset data types
- Go语言JSON文件的读写操作
- [Kali Security Penetration Testing Practice Tutorial] Chapter 6 Password Attack
- Golang nil的妙用
猜你喜欢





随机推荐
浅写一个下拉刷新组件
从滑动标尺模型看企业网络安全能力评估与建设
What is a Cross-Site Request Forgery (CSRF) attack?How to defend?
2022.8.8 Exam written in memory (memory)
深度学习(五) CNN卷积神经网络
Unity3D创建道路插件EasyRoads的使用
one of the variables needed for gradient computation has been modified by an inplace
实操|风控模型中常用的这三种预测方法与多分类场景的实现
推荐几款好用的MySQL开源客户端,建议收藏
[Kali Security Penetration Testing Practice Course] Chapter 8 Web Penetration
Redis - Basic operations and usage scenarios of String|Hash|List|Set|Zset data types
2022.8.8考试清洁工老马(sweeper)题解
【二叉树-中等】687. 最长同值路径
实例043:作用域、类的方法与变量
控制台中查看莫格命令的详细信息
On the Harvest of Travel
将信号与不同开始时间对齐
数据治理(五):元数据管理
2022.8.9考试独特的投标拍卖--800题解
2022.8.8 exam sweeps the horse (sweeper) antithesis