当前位置:网站首页>How tall is the B+ tree of the MySQL index?
How tall is the B+ tree of the MySQL index?
2022-08-09 10:29:00 【InfoQ】
一、问题
- h:Collectively referred to as the height of the index;
- h1:The height of the clustered index;
- h2:The height of the secondary secondary index;
- k:The fan-out coefficient of the intermediate node.
二、分析

2.1 索引高度h与页面I/O数的关系
SELECT * FROM USER WHERE id=1- 点查询:
- 聚族索引:h1
- 二级索引:
- 覆盖索引:h2
- 回表查询:h2+h1
- 范围查询:这种情况相对比较复杂,But the principle is similar to the point query,读者可自行分析;
- 全表查询:B+The leaves of the tree are connected by a linked list,For full table queries,All leaf nodes need to be visited from beginning to end.
2.2 索引高度htheoretical calculations
k^(h-1)k^(h-1)*n三、See how to index the true height

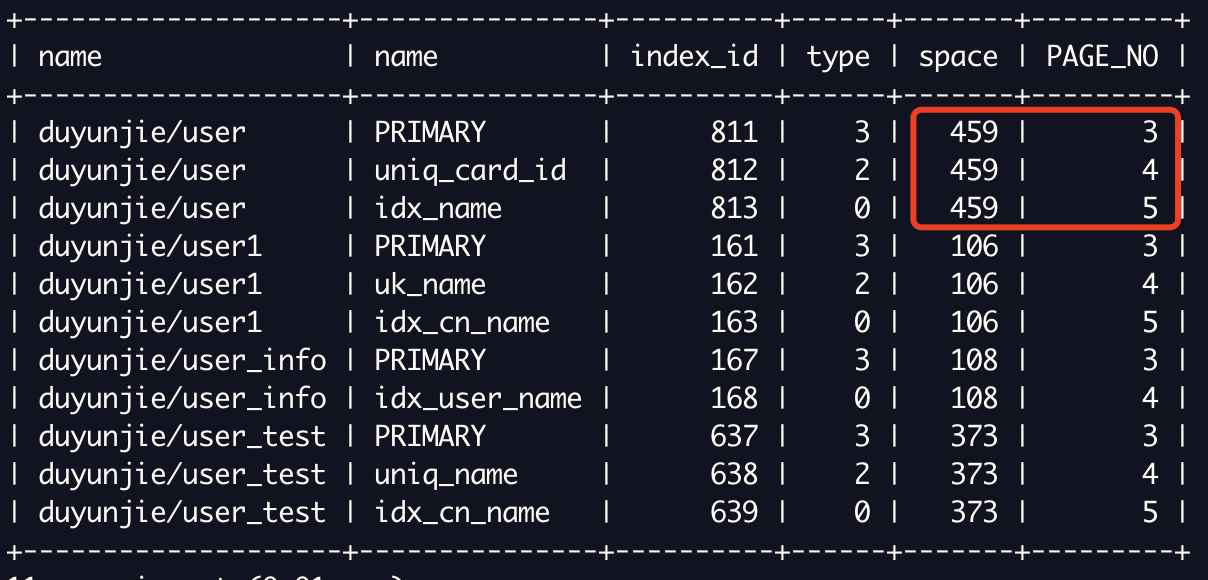
SELECT b.name, a.name, index_id, type, a.space, a.PAGE_NO
FROM information_schema.INNODB_SYS_INDEXES a,
information_schema.INNODB_SYS_TABLES b
WHERE a.table_id = b.table_id
AND a.space <> 0;
hexdump$hexdump -C -s 49216 -n 10 user.ibd
0000c040 00 01 00 00 00 00 00 00 03 2b
16384*3+64- 通过
information_schema.INNODB_SYS_INDEXES和information_schema.INNODB_SYS_TABLES找到对应索引Root页在ibdThe page number of the filePAGE_NO(Clustered indexes are usually 3,Other indexes accumulate upwards);
- 通过
hexdump -C -s 16384*PAGE_NO+64 -n 10 user.ibd,前两个字节+1is the height of the index.
四、Verify the true height of the index
CREATE TABLE `user` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`card_id` INT(11) NOT NULL DEFAULT '0' COMMENT '身份证号',
`name` VARCHAR(32) NOT NULL DEFAULT '' COMMENT '英文名字',
`age` TINYINT(2) UNSIGNED NOT NULL DEFAULT '0' COMMENT '年龄',
`content` VARCHAR(1024) NOT NULL DEFAULT '' COMMENT '附属信息',
`create_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '最近更新时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uniq_card_id` (`card_id`),
KEY `idx_name` (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='用户表';
card_idnamecontent
hexdump -C -s 49216 -n 10 user.ibd && hexdump -C -s 65600 -n 10 user.ibd && hexdump -C -s 81984 -n 10 user.ibdidx_namename五、总结
- page for one queryI/Onumber and index heighth呈正相关,主要分为以下几种情况:
- 点查询:
- 聚族索引:h1
- 二级索引:
- 覆盖索引:h2
- 回表查询:h2+h1
- 范围查询:这种情况相对比较复杂,But the principle is similar to the point query,读者可自行分析;
- 全表查询:B+The leaves of the tree are connected by a linked list,For full table queries,All leaf nodes need to be visited from beginning to end.
- The index height is usually 2~4层.在高度h=3、主键为int类型、The row record size is 1KB时,The total number of indexable rows is 1170^2*16=2190W.这也是Many big manufacturers will2000WAs a sub-library sub-table standard的原因;
- Here's how to check the true height of the index:
- 通过
information_schema.INNODB_SYS_INDEXES和information_schema.INNODB_SYS_TABLES找到对应索引Root页在ibdThe page number of the filePAGE_NO(Clustered indexes are usually 3,Other indexes accumulate upwards);
- 通过
hexdump -C -s 16384*PAGE_NO+64 -n 10 user.ibd,前两个字节+1is the height of the index.
- 索引高度hIt is also related to the data type of the index field.如果是int或short,扇出系数大,Indexing is more efficient,The entire index appears to belong“矮胖”型;而如果是varchar(32)等,The fan-out coefficient is lower,The entire index appears to belong“瘦高”型,The indexing efficiency is naturally lower.So when we select the type in the field,其The simpler the type, the better the efficiency.
#聚簇索引(第一个)
hexdump -C -s 49216 -n 10 user.ibd
#第二个索引
hexdump -C -s 65600 -n 10 user.ibd
#第三个索引
hexdump -C -s 81984 -n 10 user.ibd
waterystone边栏推荐
- 【原创】VMware Workstation实现Openwrt软路由功能,非ESXI,内容非常详细!
- 极域Killer 1.0代码
- Unix Environment Programming Chapter 14 14.4 I/O Multiplexing
- 3D printed this DuPont cable management artifact, and the desktop is no longer messy
- Database connection operations for MySQL and MyEclipse
- WUSTOJ:n个素数构成等差数列
- libavcodec.dll导致游戏不能运行及explorer关闭
- 循环嵌套以及列表的基本操作
- SQL Server查询优化
- 编解码(seq2seq)+注意机制(attention) 详细讲解
猜你喜欢
Transformer+Embedding+Self-Attention原理详解

使用.NET简单实现一个Redis的高性能克隆版(四、五)
BERT预训练模型(Bidirectional Encoder Representations from Transformers)-原理详解
antd表单
第二周作业
程序员的专属浪漫——用3D Engine 5分钟实现烟花绽放效果
![[Halcon&定位] 解决Roi区域外的模板匹配成功](/img/ad/549c7e6336ef62469a7c71e6bfcb42.png)
[Halcon&定位] 解决Roi区域外的模板匹配成功
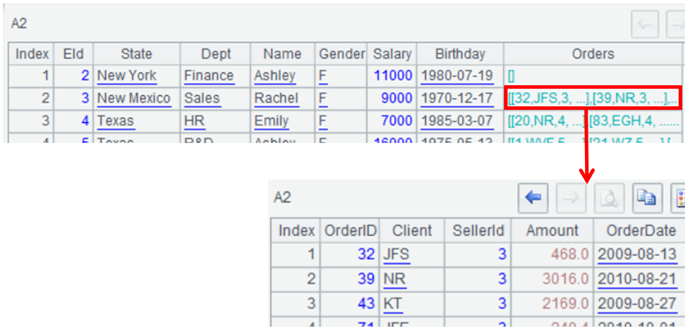
开源SPL,WebService/Restful广泛应用于程序间通讯,如微服务、数据交换、公共或私有的数据服务等。
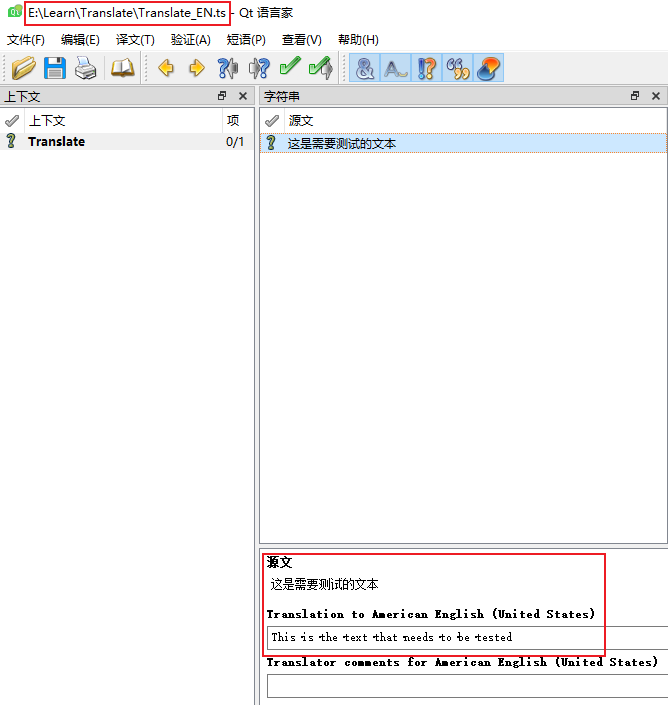
Qt 国际化翻译
The common problems in laptops, continuously updated
随机推荐
需求侧电力负荷预测(Matlab代码实现)
Loop nesting and basic operations on lists
循环嵌套以及列表的基本操作
编解码(seq2seq)+注意机制(attention) 详细讲解
Technology Sharing | Sending Requests Using cURL
踩坑scrollIntoView
Win7 远程桌面限制IP
深度学习--神经网络(基础讲解)
LM小型可编程控制器软件(基于CoDeSys)笔记二十六:plc的数据存储区(模拟量输入通道部分)
Redis + NodeJS 实现一个能处理海量数据的异步任务队列系统
markdown转ipynb--利用包notedown
浅析JWT安全问题
常用语言图表库总结
深度学习--循环神经网络(Recurrent Neural Network)
MySQL备份与恢复
虚拟列表key复用问题
unix环境编程 第十五章 15.6 XSI IPC
antd的Table列选择、列拓展
函数二
MySQL执行过程及执行顺序