当前位置:网站首页>MySQL索引的B+树到底有多高?
MySQL索引的B+树到底有多高?
2022-08-09 10:18:00 【InfoQ】
一、问题
- h:统称索引的高度;
- h1:聚簇索引的高度;
- h2:二级辅助索引的高度;
- k:中间结点的扇出系数。
二、分析

2.1 索引高度h与页面I/O数的关系
SELECT * FROM USER WHERE id=1- 点查询:
- 聚族索引:h1
- 二级索引:
- 覆盖索引:h2
- 回表查询:h2+h1
- 范围查询:这种情况相对比较复杂,但跟点查询的原理类似,读者可自行分析;
- 全表查询:B+树的叶子结点是通过链表连接起来的,对于全表查询,需要从头到尾将所有的叶子结点访问一遍。
2.2 索引高度h的理论计算
k^(h-1)k^(h-1)*n三、查看索引真实高度的方法

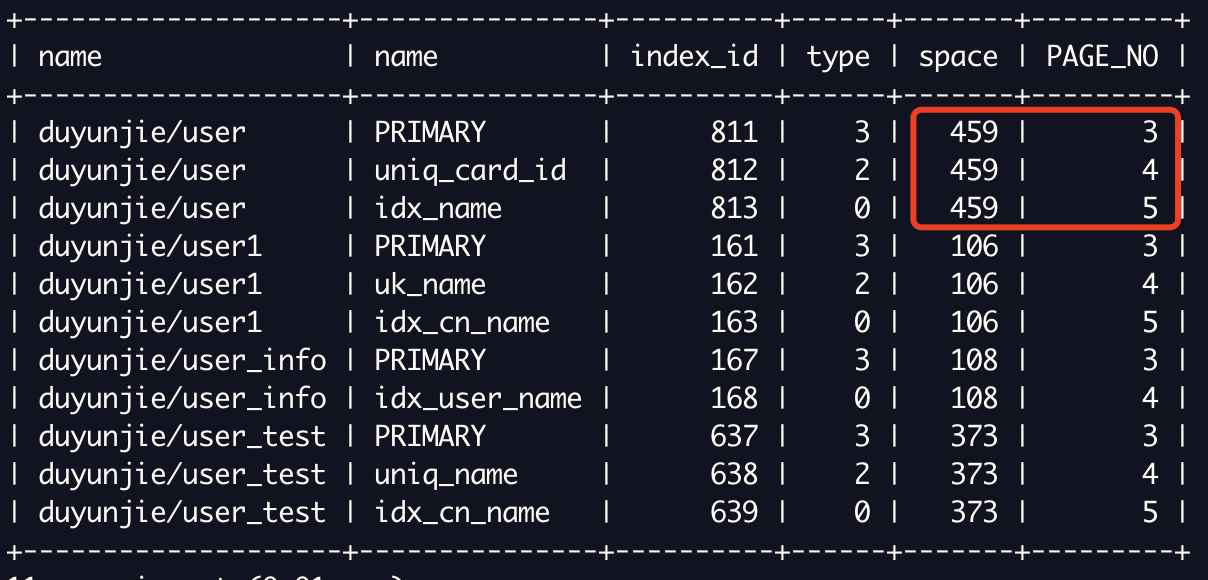
SELECT b.name, a.name, index_id, type, a.space, a.PAGE_NO
FROM information_schema.INNODB_SYS_INDEXES a,
information_schema.INNODB_SYS_TABLES b
WHERE a.table_id = b.table_id
AND a.space <> 0;
hexdump$hexdump -C -s 49216 -n 10 user.ibd
0000c040 00 01 00 00 00 00 00 00 03 2b
16384*3+64- 通过
information_schema.INNODB_SYS_INDEXES和information_schema.INNODB_SYS_TABLES找到对应索引Root页在ibd文件的页面号PAGE_NO(聚簇索引通常为3,其他索引往上累加);
- 通过
hexdump -C -s 16384*PAGE_NO+64 -n 10 user.ibd,前两个字节+1即为索引的高度。
四、验证索引的真实高度
CREATE TABLE `user` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`card_id` INT(11) NOT NULL DEFAULT '0' COMMENT '身份证号',
`name` VARCHAR(32) NOT NULL DEFAULT '' COMMENT '英文名字',
`age` TINYINT(2) UNSIGNED NOT NULL DEFAULT '0' COMMENT '年龄',
`content` VARCHAR(1024) NOT NULL DEFAULT '' COMMENT '附属信息',
`create_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '最近更新时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uniq_card_id` (`card_id`),
KEY `idx_name` (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='用户表';
card_idnamecontent
hexdump -C -s 49216 -n 10 user.ibd && hexdump -C -s 65600 -n 10 user.ibd && hexdump -C -s 81984 -n 10 user.ibdidx_namename五、总结
- 一次查询的页面I/O数跟索引高度h呈正相关,主要分为以下几种情况:
- 点查询:
- 聚族索引:h1
- 二级索引:
- 覆盖索引:h2
- 回表查询:h2+h1
- 范围查询:这种情况相对比较复杂,但跟点查询的原理类似,读者可自行分析;
- 全表查询:B+树的叶子结点是通过链表连接起来的,对于全表查询,需要从头到尾将所有的叶子结点访问一遍。
- 索引高度通常为2~4层。在高度h=3、主键为int类型、行记录大小为1KB时,可索引的总行数为1170^2*16=2190W。这也是很多大厂将2000W作为分库分表标准的原因;
- 查看索引真实高度的方法如下:
- 通过
information_schema.INNODB_SYS_INDEXES和information_schema.INNODB_SYS_TABLES找到对应索引Root页在ibd文件的页面号PAGE_NO(聚簇索引通常为3,其他索引往上累加);
- 通过
hexdump -C -s 16384*PAGE_NO+64 -n 10 user.ibd,前两个字节+1即为索引的高度。
- 索引高度h也跟索引字段的数据类型有关。如果是int或short,扇出系数大,索引效率更好,整个索引看起来属于“矮胖”型;而如果是varchar(32)等,那扇出系数就低了,整个索引看起来属于“瘦高”型,索引效率自然要低些。所以我们在字段选取类型时,其类型越简单效率越好。
#聚簇索引(第一个)
hexdump -C -s 49216 -n 10 user.ibd
#第二个索引
hexdump -C -s 65600 -n 10 user.ibd
#第三个索引
hexdump -C -s 81984 -n 10 user.ibd
waterystone边栏推荐
猜你喜欢
RTP
多线程(基础)
Quick sort eight sorts (3) 】 【 (dynamic figure deduction Hoare, digging holes, front and rear pointer method)
编解码(seq2seq)+注意机制(attention) 详细讲解
Demand side power load forecasting (Matlab code implementation)

《刷题日记》2
动态内存管理

Win系统 - 罗技 G604 鼠标蓝灯闪烁、失灵解决方案

使用.NET简单实现一个Redis的高性能克隆版(四、五)

学长告诉我,大厂MySQL都是通过SSH连接的
随机推荐
Loop nesting and basic operations on lists
阿里神作!吃透这份资料入厂率高达99%
史上最小白之《Word2vec》详解
学长告诉我,大厂MySQL都是通过SSH连接的
用Word写代码
[贴装专题] 基于多目视觉的手眼标定
基于信号量与环形队列实现读写异步缓存队列
深度学习--生成对抗网络(Generative Adversarial Nets)
Throwing a question? The execution speed of the Count operation in the Mysql environment is very slow. You need to manually add an index to the primary key---MySql optimization 001
JDBC中的增删改查操作
Super detailed MySQL basic operations
Dream Notes 0809
MySQL全文索引
踩坑scrollIntoView
antd的Table列选择、列拓展
相伴成长,彼此成就 用友U9 cloud做好制造业数智化升级的同路人
WUSTOJ:n个素数构成等差数列
快速解决MySQL插入中文数据时报错或乱码问题
EndNoteX9 OR X 20 Guide
Technology Sharing | Sending Requests Using cURL