当前位置:网站首页>YOLOv5的Tricks | 【Trick12】YOLOv5使用的数据增强方法汇总
YOLOv5的Tricks | 【Trick12】YOLOv5使用的数据增强方法汇总
2022-08-10 23:48:00 【Clichong】
如有错误,恳请指出。
时隔两个多月重新看yolov5的代码显然开始力不从心,当时应该一鼓作气的整理完的。在专栏前面的内容一直介绍的是yolov5训练时候使用的一些技巧,这里用这篇博客最后归纳一下yolov5在数据增强上所使用的技巧。
在yolov3-spp专栏的时候,我介绍过yolov3-spp大致所使用的一些数据增强的方法:
在之前详细的介绍过代码,而在yolov5这里,其实代码是类似的,甚至函数的名字都没有变化,看过源码的朋友就可能知道了,改变的地方其实不是很多,所以这里就不再详细介绍代码的细节了,只是总结一下使用的数据增强。
文章目录
0. 自定义数据集的整体架构
项目中,使用 create_dataloader 函数构建 dataloader 与 dataset,这个部分是整个算法的核心部分之一。实现数据增强的方法就是在构建 dataset 中设置的。
- create_dataloader函数
def create_dataloader(path, imgsz, batch_size, stride, single_cls=False, hyp=None, augment=False, cache=False, pad=0.0,
rect=False, rank=-1, workers=8, image_weights=False, quad=False, prefix=''):
# Make sure only the first process in DDP process the dataset first, and the following others can use the cache
with torch_distributed_zero_first(rank):
dataset = LoadImagesAndLabels(path, imgsz, batch_size,
augment=augment, # augment images
hyp=hyp, # augmentation hyperparameters
rect=rect, # rectangular training
cache_images=cache,
single_cls=single_cls,
stride=int(stride),
pad=pad,
image_weights=image_weights,
prefix=prefix)
batch_size = min(batch_size, len(dataset))
# 这里对num_worker进行更改
# nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, workers]) # number of workers
nw = 0 # 可以适当提高这个参数0, 2, 4, 8, 16…
sampler = torch.utils.data.distributed.DistributedSampler(dataset) if rank != -1 else None
loader = torch.utils.data.DataLoader if image_weights else InfiniteDataLoader
# Use torch.utils.data.DataLoader() if dataset.properties will update during training else InfiniteDataLoader()
dataloader = loader(dataset,
batch_size=batch_size,
num_workers=nw,
sampler=sampler,
pin_memory=True,
collate_fn=LoadImagesAndLabels.collate_fn4 if quad else LoadImagesAndLabels.collate_fn)
return dataloader, dataset
可以看见,在构建 dataloader 的时候,还对batch数据进行了设置,为其设置了批处理的 collate_fn 函数。核心重点,就是 LoadImagesAndLabels 函数,自定义了数据集的处理过程。下面详细对其分析。
- LoadImagesAndLabels函数
class LoadImagesAndLabels(Dataset):
# YOLOv5 train_loader/val_loader, loads images and labels for training and validation
cache_version = 0.5 # dataset labels *.cache version
def __init__(self, path, img_size=640, batch_size=16, augment=False, hyp=None, rect=False, image_weights=False,
cache_images=False, single_cls=False, stride=32, pad=0.0, prefix=''):
self.img_size = img_size
self.augment = augment
self.hyp = hyp
self.image_weights = image_weights
self.rect = False if image_weights else rect
self.mosaic = self.augment and not self.rect # load 4 images at a time into a mosaic (only during training)
self.mosaic_border = [-img_size // 2, -img_size // 2]
self.stride = stride
self.path = path
self.albumentations = Albumentations() if augment else None
....
# 下面省略了许多步骤,不过无伤大雅
....
def __len__(self):
return len(self.img_files)
# def __iter__(self):
# self.count = -1
# print('ran dataset iter')
# #self.shuffled_vector = np.random.permutation(self.nF) if self.augment else np.arange(self.nF)
# return self
def __getitem__(self, index):
index = self.indices[index] # linear, shuffled, or image_weights
hyp = self.hyp
mosaic = self.mosaic and random.random() < hyp['mosaic']
if mosaic:
# Load mosaic
img, labels = load_mosaic(self, index) # use load_mosaic4
# img, labels = load_mosaic9(self, index) # use load_mosaic9
shapes = None
# MixUp augmentation
if random.random() < hyp['mixup']:
img, labels = mixup(img, labels, *load_mosaic(self, random.randint(0, self.n - 1)))
# img, labels = mixup(img, labels, *load_mosaic9(self, random.randint(0, self.n - 1)))
else:
# Load image
img, (h0, w0), (h, w) = load_image(self, index)
# Letterbox
shape = self.batch_shapes[self.batch[index]] if self.rect else self.img_size # final letterboxed shape
img, ratio, pad = letterbox(img, shape, auto=False, scaleup=self.augment)
shapes = (h0, w0), ((h / h0, w / w0), pad) # for COCO mAP rescaling
labels = self.labels[index].copy()
if labels.size: # normalized xywh to pixel xyxy format
labels[:, 1:] = xywhn2xyxy(labels[:, 1:], ratio[0] * w, ratio[1] * h, padw=pad[0], padh=pad[1])
if self.augment:
img, labels = random_perspective(img, labels,
degrees=hyp['degrees'],
translate=hyp['translate'],
scale=hyp['scale'],
shear=hyp['shear'],
perspective=hyp['perspective'])
nl = len(labels) # number of labels
if nl:
labels[:, 1:5] = xyxy2xywhn(labels[:, 1:5], w=img.shape[1], h=img.shape[0], clip=True, eps=1E-3)
# create_dataloader to set augment
if self.augment:
# Albumentations
img, labels = self.albumentations(img, labels)
nl = len(labels) # update after albumentations
# HSV color-space
# augment_hsv(img, hgain=hyp['hsv_h'], sgain=hyp['hsv_s'], vgain=hyp['hsv_v'])
# Flip up-down
if random.random() < hyp['flipud']:
img = np.flipud(img)
if nl:
labels[:, 2] = 1 - labels[:, 2]
# Flip left-right
if random.random() < hyp['fliplr']:
img = np.fliplr(img)
if nl:
labels[:, 1] = 1 - labels[:, 1]
# Cutouts
# labels = cutout(img, labels, p=0.5)
labels_out = torch.zeros((nl, 6))
if nl:
labels_out[:, 1:] = torch.from_numpy(labels)
# Convert
img = img.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
img = np.ascontiguousarray(img)
return torch.from_numpy(img), labels_out, self.img_files[index], shapes
@staticmethod
def collate_fn(batch):
img, label, path, shapes = zip(*batch) # transposed
for i, l in enumerate(label):
l[:, 0] = i # add target image index for build_targets()
return torch.stack(img, 0), torch.cat(label, 0), path, shapes
@staticmethod
def collate_fn4(batch):
img, label, path, shapes = zip(*batch) # transposed
n = len(shapes) // 4
img4, label4, path4, shapes4 = [], [], path[:n], shapes[:n]
ho = torch.tensor([[0., 0, 0, 1, 0, 0]])
wo = torch.tensor([[0., 0, 1, 0, 0, 0]])
s = torch.tensor([[1, 1, .5, .5, .5, .5]]) # scale
for i in range(n): # zidane torch.zeros(16,3,720,1280) # BCHW
i *= 4
if random.random() < 0.5:
im = F.interpolate(img[i].unsqueeze(0).float(), scale_factor=2., mode='bilinear', align_corners=False)[
0].type(img[i].type())
l = label[i]
else:
im = torch.cat((torch.cat((img[i], img[i + 1]), 1), torch.cat((img[i + 2], img[i + 3]), 1)), 2)
l = torch.cat((label[i], label[i + 1] + ho, label[i + 2] + wo, label[i + 3] + ho + wo), 0) * s
img4.append(im)
label4.append(l)
for i, l in enumerate(label4):
l[:, 0] = i # add target image index for build_targets()
return torch.stack(img4, 0), torch.cat(label4, 0), path4, shapes4
大致的函数代码如上所示,但是其实有很多的繁琐步骤。self.rect 是都进行矩形训练,但是一般来说是进行矩形推理来加快推理速度。cache_image 是为了缓存图像,以空间换时间。这些内容我都省略掉,没有贴上来。
自定义数据集的重点是 __getitem__ 函数,各种数据增强的方式就是在这里进行的。所以我对部分代码进行了省略,只贴出了重要的部分。
1. Mosaic数据增强
这个部分之前已经介绍过了,不过值得一提的是,这里yolov5还额外提出了一个9图的mosaic操作,就是把之前的4个图像换成了9张图像,拼接在一起处理,图像更大了而且label也更多,训练一张这样的拼接图像等同与训练了9张小图。
- 操作示例

- Mosaic(4张)实现代码
def load_mosaic(self, index):
# YOLOv5 4-mosaic loader. Loads 1 image + 3 random images into a 4-image mosaic
labels4, segments4 = [], []
s = self.img_size
yc, xc = [int(random.uniform(-x, 2 * s + x)) for x in self.mosaic_border] # mosaic center x, y
indices = [index] + random.choices(self.indices, k=3) # 3 additional image indices
random.shuffle(indices)
for i, index in enumerate(indices):
# Load image
img, _, (h, w) = load_image(self, index)
# place img in img4
if i == 0: # top left
img4 = np.full((s * 2, s * 2, img.shape[2]), 114, dtype=np.uint8) # base image with 4 tiles
x1a, y1a, x2a, y2a = max(xc - w, 0), max(yc - h, 0), xc, yc # xmin, ymin, xmax, ymax (large image)
x1b, y1b, x2b, y2b = w - (x2a - x1a), h - (y2a - y1a), w, h # xmin, ymin, xmax, ymax (small image)
elif i == 1: # top right
x1a, y1a, x2a, y2a = xc, max(yc - h, 0), min(xc + w, s * 2), yc
x1b, y1b, x2b, y2b = 0, h - (y2a - y1a), min(w, x2a - x1a), h
elif i == 2: # bottom left
x1a, y1a, x2a, y2a = max(xc - w, 0), yc, xc, min(s * 2, yc + h)
x1b, y1b, x2b, y2b = w - (x2a - x1a), 0, w, min(y2a - y1a, h)
elif i == 3: # bottom right
x1a, y1a, x2a, y2a = xc, yc, min(xc + w, s * 2), min(s * 2, yc + h)
x1b, y1b, x2b, y2b = 0, 0, min(w, x2a - x1a), min(y2a - y1a, h)
img4[y1a:y2a, x1a:x2a] = img[y1b:y2b, x1b:x2b] # img4[ymin:ymax, xmin:xmax]
padw = x1a - x1b
padh = y1a - y1b
# Labels
labels, segments = self.labels[index].copy(), self.segments[index].copy()
if labels.size:
labels[:, 1:] = xywhn2xyxy(labels[:, 1:], w, h, padw, padh) # normalized xywh to pixel xyxy format
segments = [xyn2xy(x, w, h, padw, padh) for x in segments]
labels4.append(labels)
segments4.extend(segments)
# Concat/clip labels
labels4 = np.concatenate(labels4, 0)
for x in (labels4[:, 1:], *segments4):
np.clip(x, 0, 2 * s, out=x) # clip when using random_perspective()
# img4, labels4 = replicate(img4, labels4) # replicate
# Augment
img4, labels4, segments4 = copy_paste(img4, labels4, segments4, p=self.hyp['copy_paste'])
img4, labels4 = random_perspective(img4, labels4, segments4,
degrees=self.hyp['degrees'],
translate=self.hyp['translate'],
scale=self.hyp['scale'],
shear=self.hyp['shear'],
perspective=self.hyp['perspective'],
border=self.mosaic_border) # border to remove
return img4, labels4
- Mosaic(9张)实现代码
def load_mosaic9(self, index):
# YOLOv5 9-mosaic loader. Loads 1 image + 8 random images into a 9-image mosaic
labels9, segments9 = [], []
s = self.img_size
indices = [index] + random.choices(self.indices, k=8) # 8 additional image indices
random.shuffle(indices)
for i, index in enumerate(indices):
# Load image
img, _, (h, w) = load_image(self, index)
# place img in img9
if i == 0: # center
img9 = np.full((s * 3, s * 3, img.shape[2]), 114, dtype=np.uint8) # base image with 4 tiles
h0, w0 = h, w
c = s, s, s + w, s + h # xmin, ymin, xmax, ymax (base) coordinates
elif i == 1: # top
c = s, s - h, s + w, s
elif i == 2: # top right
c = s + wp, s - h, s + wp + w, s
elif i == 3: # right
c = s + w0, s, s + w0 + w, s + h
elif i == 4: # bottom right
c = s + w0, s + hp, s + w0 + w, s + hp + h
elif i == 5: # bottom
c = s + w0 - w, s + h0, s + w0, s + h0 + h
elif i == 6: # bottom left
c = s + w0 - wp - w, s + h0, s + w0 - wp, s + h0 + h
elif i == 7: # left
c = s - w, s + h0 - h, s, s + h0
elif i == 8: # top left
c = s - w, s + h0 - hp - h, s, s + h0 - hp
padx, pady = c[:2]
x1, y1, x2, y2 = [max(x, 0) for x in c] # allocate coords
# Labels
labels, segments = self.labels[index].copy(), self.segments[index].copy()
if labels.size:
labels[:, 1:] = xywhn2xyxy(labels[:, 1:], w, h, padx, pady) # normalized xywh to pixel xyxy format
segments = [xyn2xy(x, w, h, padx, pady) for x in segments]
labels9.append(labels)
segments9.extend(segments)
# Image
img9[y1:y2, x1:x2] = img[y1 - pady:, x1 - padx:] # img9[ymin:ymax, xmin:xmax]
hp, wp = h, w # height, width previous
# Offset
yc, xc = [int(random.uniform(0, s)) for _ in self.mosaic_border] # mosaic center x, y
img9 = img9[yc:yc + 2 * s, xc:xc + 2 * s]
# Concat/clip labels
labels9 = np.concatenate(labels9, 0)
labels9[:, [1, 3]] -= xc
labels9[:, [2, 4]] -= yc
c = np.array([xc, yc]) # centers
segments9 = [x - c for x in segments9]
for x in (labels9[:, 1:], *segments9):
np.clip(x, 0, 2 * s, out=x) # clip when using random_perspective()
# img9, labels9 = replicate(img9, labels9) # replicate
# Augment
img9, labels9 = random_perspective(img9, labels9, segments9,
degrees=self.hyp['degrees'],
translate=self.hyp['translate'],
scale=self.hyp['scale'],
shear=self.hyp['shear'],
perspective=self.hyp['perspective'],
border=self.mosaic_border) # border to remove
return img9, labels9
使用这两个方法的方式很简单,只需要改变两个地方就可以了,如下所示:
mosaic = self.mosaic and random.random() < hyp['mosaic']
if mosaic:
# Load mosaic
img, labels = load_mosaic(self, index) # use load_mosaic4
# img, labels = load_mosaic9(self, index) # use load_mosaic9
shapes = None
# MixUp augmentation
if random.random() < hyp['mixup']:
img, labels = mixup(img, labels, *load_mosaic(self, random.randint(0, self.n - 1)))
# img, labels = mixup(img, labels, *load_mosaic9(self, random.randint(0, self.n - 1)))
需要注意,这里的Mosaic函数并不只有Mosaic操作,还包含了仿射变换 random_perspective 与 copy_paste 操作,下面会介绍到。
2. Copy paste数据增强
中文名叫复制粘贴大法,将部分目标随机的粘贴到图片中,前提是数据要有segments数据才行,即每个目标的实例分割信息。下面是Copy paste原论文中的示意图。
- 操作示例

- 实现代码
def copy_paste(im, labels, segments, p=0.5):
# Implement Copy-Paste augmentation https://arxiv.org/abs/2012.07177, labels as nx5 np.array(cls, xyxy)
n = len(segments)
if p and n:
h, w, c = im.shape # height, width, channels
im_new = np.zeros(im.shape, np.uint8)
for j in random.sample(range(n), k=round(p * n)):
l, s = labels[j], segments[j]
box = w - l[3], l[2], w - l[1], l[4]
ioa = bbox_ioa(box, labels[:, 1:5]) # intersection over area
if (ioa < 0.30).all(): # allow 30% obscuration of existing labels
labels = np.concatenate((labels, [[l[0], *box]]), 0)
segments.append(np.concatenate((w - s[:, 0:1], s[:, 1:2]), 1))
cv2.drawContours(im_new, [segments[j].astype(np.int32)], -1, (255, 255, 255), cv2.FILLED)
result = cv2.bitwise_and(src1=im, src2=im_new)
result = cv2.flip(result, 1) # augment segments (flip left-right)
i = result > 0 # pixels to replace
# i[:, :] = result.max(2).reshape(h, w, 1) # act over ch
im[i] = result[i] # cv2.imwrite('debug.jpg', im) # debug
return im, labels, segments
在加载马赛克数据增强的时候,是自动使用这个方法的:
# Augment
img4, labels4, segments4 = copy_paste(img4, labels4, segments4, p=self.hyp['copy_paste'])
如果选择不用,可以直接选择注释掉即可。一般来说,在训练自定义数据集的时候,肯定没有相关的掩码,所以其实也没有用到。
3. Random affine仿射变换
yolov5的仿射变换包含随机旋转、平移、缩放、错切操作,和yolov3-spp一样,代码都没有改变。据配置文件里的超参数发现只使用了Scale和Translation即缩放和平移。
- 操作示例

- 实现代码
def random_perspective(im, targets=(), segments=(), degrees=10, translate=.1, scale=.1, shear=10, perspective=0.0,
border=(0, 0)):
# torchvision.transforms.RandomAffine(degrees=(-10, 10), translate=(.1, .1), scale=(.9, 1.1), shear=(-10, 10))
# targets = [cls, xyxy]
height = im.shape[0] + border[0] * 2 # shape(h,w,c)
width = im.shape[1] + border[1] * 2
# Center
C = np.eye(3)
C[0, 2] = -im.shape[1] / 2 # x translation (pixels)
C[1, 2] = -im.shape[0] / 2 # y translation (pixels)
# Perspective
P = np.eye(3)
P[2, 0] = random.uniform(-perspective, perspective) # x perspective (about y)
P[2, 1] = random.uniform(-perspective, perspective) # y perspective (about x)
# Rotation and Scale
R = np.eye(3)
a = random.uniform(-degrees, degrees)
# a += random.choice([-180, -90, 0, 90]) # add 90deg rotations to small rotations
s = random.uniform(1 - scale, 1 + scale)
# s = 2 ** random.uniform(-scale, scale)
R[:2] = cv2.getRotationMatrix2D(angle=a, center=(0, 0), scale=s)
# Shear
S = np.eye(3)
S[0, 1] = math.tan(random.uniform(-shear, shear) * math.pi / 180) # x shear (deg)
S[1, 0] = math.tan(random.uniform(-shear, shear) * math.pi / 180) # y shear (deg)
# Translation
T = np.eye(3)
T[0, 2] = random.uniform(0.5 - translate, 0.5 + translate) * width # x translation (pixels)
T[1, 2] = random.uniform(0.5 - translate, 0.5 + translate) * height # y translation (pixels)
# Combined rotation matrix
M = T @ S @ R @ P @ C # order of operations (right to left) is IMPORTANT
if (border[0] != 0) or (border[1] != 0) or (M != np.eye(3)).any(): # image changed
if perspective:
im = cv2.warpPerspective(im, M, dsize=(width, height), borderValue=(114, 114, 114))
else: # affine
im = cv2.warpAffine(im, M[:2], dsize=(width, height), borderValue=(114, 114, 114))
# Visualize
# import matplotlib.pyplot as plt
# ax = plt.subplots(1, 2, figsize=(12, 6))[1].ravel()
# ax[0].imshow(im[:, :, ::-1]) # base
# ax[1].imshow(im2[:, :, ::-1]) # warped
# Transform label coordinates
n = len(targets)
if n:
use_segments = any(x.any() for x in segments)
new = np.zeros((n, 4))
if use_segments: # warp segments
segments = resample_segments(segments) # upsample
for i, segment in enumerate(segments):
xy = np.ones((len(segment), 3))
xy[:, :2] = segment
xy = xy @ M.T # transform
xy = xy[:, :2] / xy[:, 2:3] if perspective else xy[:, :2] # perspective rescale or affine
# clip
new[i] = segment2box(xy, width, height)
else: # warp boxes
xy = np.ones((n * 4, 3))
xy[:, :2] = targets[:, [1, 2, 3, 4, 1, 4, 3, 2]].reshape(n * 4, 2) # x1y1, x2y2, x1y2, x2y1
xy = xy @ M.T # transform
xy = (xy[:, :2] / xy[:, 2:3] if perspective else xy[:, :2]).reshape(n, 8) # perspective rescale or affine
# create new boxes
x = xy[:, [0, 2, 4, 6]]
y = xy[:, [1, 3, 5, 7]]
new = np.concatenate((x.min(1), y.min(1), x.max(1), y.max(1))).reshape(4, n).T
# clip
new[:, [0, 2]] = new[:, [0, 2]].clip(0, width)
new[:, [1, 3]] = new[:, [1, 3]].clip(0, height)
# filter candidates
i = box_candidates(box1=targets[:, 1:5].T * s, box2=new.T, area_thr=0.01 if use_segments else 0.10)
targets = targets[i]
targets[:, 1:5] = new[i]
return im, targets
在加载马赛克数据增强的时候,同样是自动默认同时使用这个方法的。如果不想使用,直接注释即可。
# Augment
img4, labels4, segments4 = copy_paste(img4, labels4, segments4, p=self.hyp['copy_paste'])
img4, labels4 = random_perspective(img4, labels4, segments4,
degrees=self.hyp['degrees'],
translate=self.hyp['translate'],
scale=self.hyp['scale'],
shear=self.hyp['shear'],
perspective=self.hyp['perspective'],
border=self.mosaic_border) # border to remove
而且,如果选择不适应马赛克数据增强,而是选择其他的数据增强方式,仿射变换同样会被使用到。
if mosaic:
# Load mosaic
img, labels = load_mosaic(self, index) # use load_mosaic4
...
else:
# Load image
img, (h0, w0), (h, w) = load_image(self, index)
...
if self.augment:
img, labels = random_perspective(img, labels,
degrees=hyp['degrees'],
translate=hyp['translate'],
scale=hyp['scale'],
shear=hyp['shear'],
perspective=hyp['perspective'])
其原理,可以参考之前的文章:数据增强 | 旋转、平移、缩放、错切、HSV增强
4. MixUp数据增强
这个比较熟悉了,就是调整透明度两张图像叠加在一起。代码中只有较大的模型才使用到了MixUp,而且每次只有10%的概率会使用到。
- 操作示例
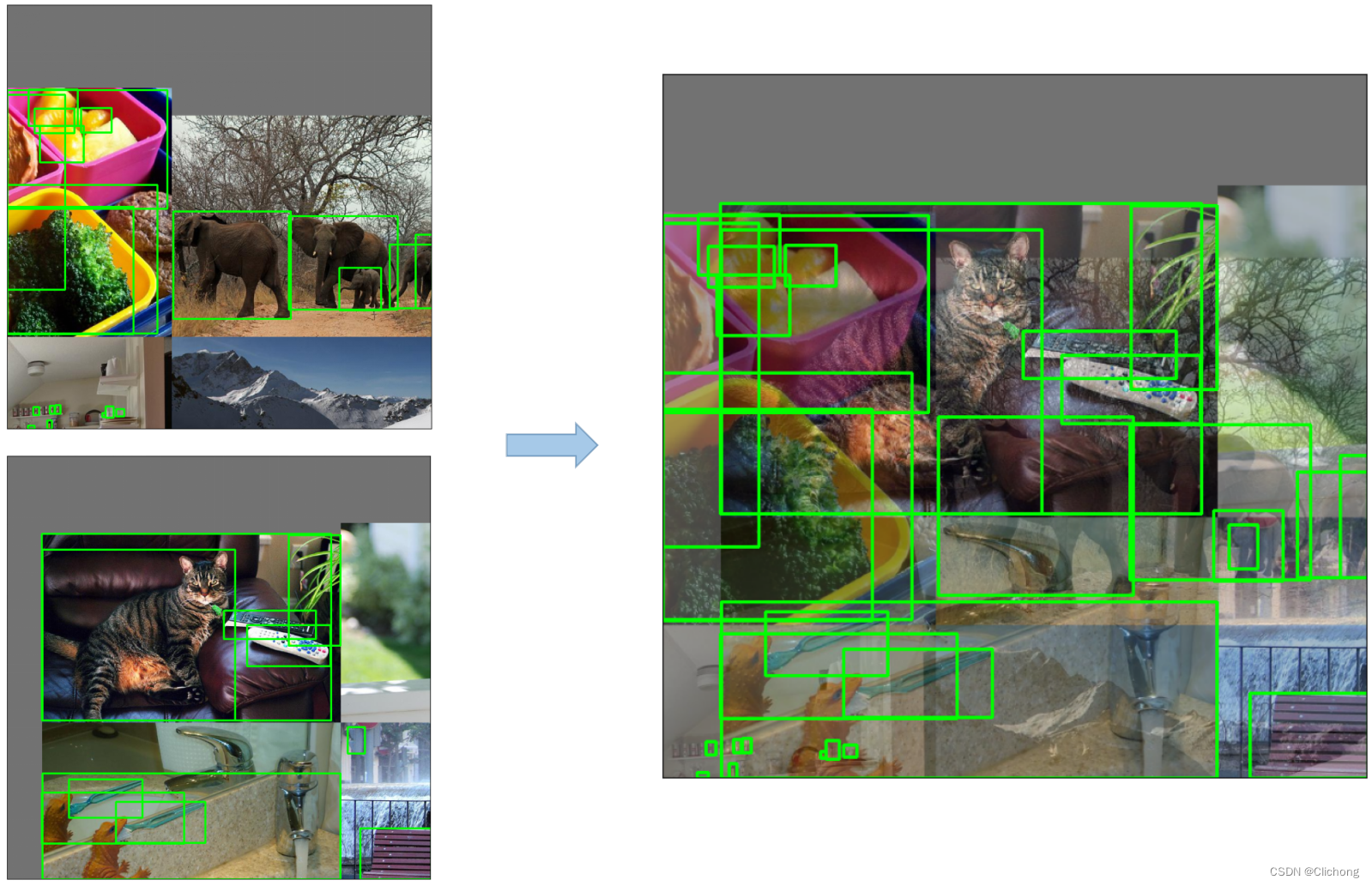
- 实现代码
def mixup(im, labels, im2, labels2):
# Applies MixUp augmentation https://arxiv.org/pdf/1710.09412.pdf
r = np.random.beta(32.0, 32.0) # mixup ratio, alpha=beta=32.0
im = (im * r + im2 * (1 - r)).astype(np.uint8)
labels = np.concatenate((labels, labels2), 0)
return im, labels
可以看见,实现只需要几行代码,比较简单的。这个方法在多数的计算机视觉模型中都有使用到。
在调用马赛克处理的时候,MixUp有一定的几率会被使用到
# MixUp augmentation
if random.random() < hyp['mixup']:
img, labels = mixup(img, labels, *load_mosaic(self, random.randint(0, self.n - 1)))
# img, labels = mixup(img, labels, *load_mosaic9(self, random.randint(0, self.n - 1)))
5. HSV随机增强图像
随机增强图像HSV在 数据增强 | 旋转、平移、缩放、错切、HSV增强 这篇文章中也有介绍到。不过在yolov5中,这里默认是注释掉不使用的。
- 操作示例

- 实现代码
def augment_hsv(im, hgain=0.5, sgain=0.5, vgain=0.5):
# HSV color-space augmentation
if hgain or sgain or vgain:
r = np.random.uniform(-1, 1, 3) * [hgain, sgain, vgain] + 1 # random gains
hue, sat, val = cv2.split(cv2.cvtColor(im, cv2.COLOR_BGR2HSV))
dtype = im.dtype # uint8
x = np.arange(0, 256, dtype=r.dtype)
lut_hue = ((x * r[0]) % 180).astype(dtype)
lut_sat = np.clip(x * r[1], 0, 255).astype(dtype)
lut_val = np.clip(x * r[2], 0, 255).astype(dtype)
im_hsv = cv2.merge((cv2.LUT(hue, lut_hue), cv2.LUT(sat, lut_sat), cv2.LUT(val, lut_val)))
cv2.cvtColor(im_hsv, cv2.COLOR_HSV2BGR, dst=im) # no return needed
在选择进行数据增强的配置中,默认注释不使用,如下所示:
# create_dataloader to set augment
if self.augment:
# Albumentations
img, labels = self.albumentations(img, labels)
nl = len(labels) # update after albumentations
# HSV color-space
# augment_hsv(img, hgain=hyp['hsv_h'], sgain=hyp['hsv_s'], vgain=hyp['hsv_v'])
6. 随机水平翻转
这个就是如字面意思,随机上下左右的水平翻转
- 操作示例
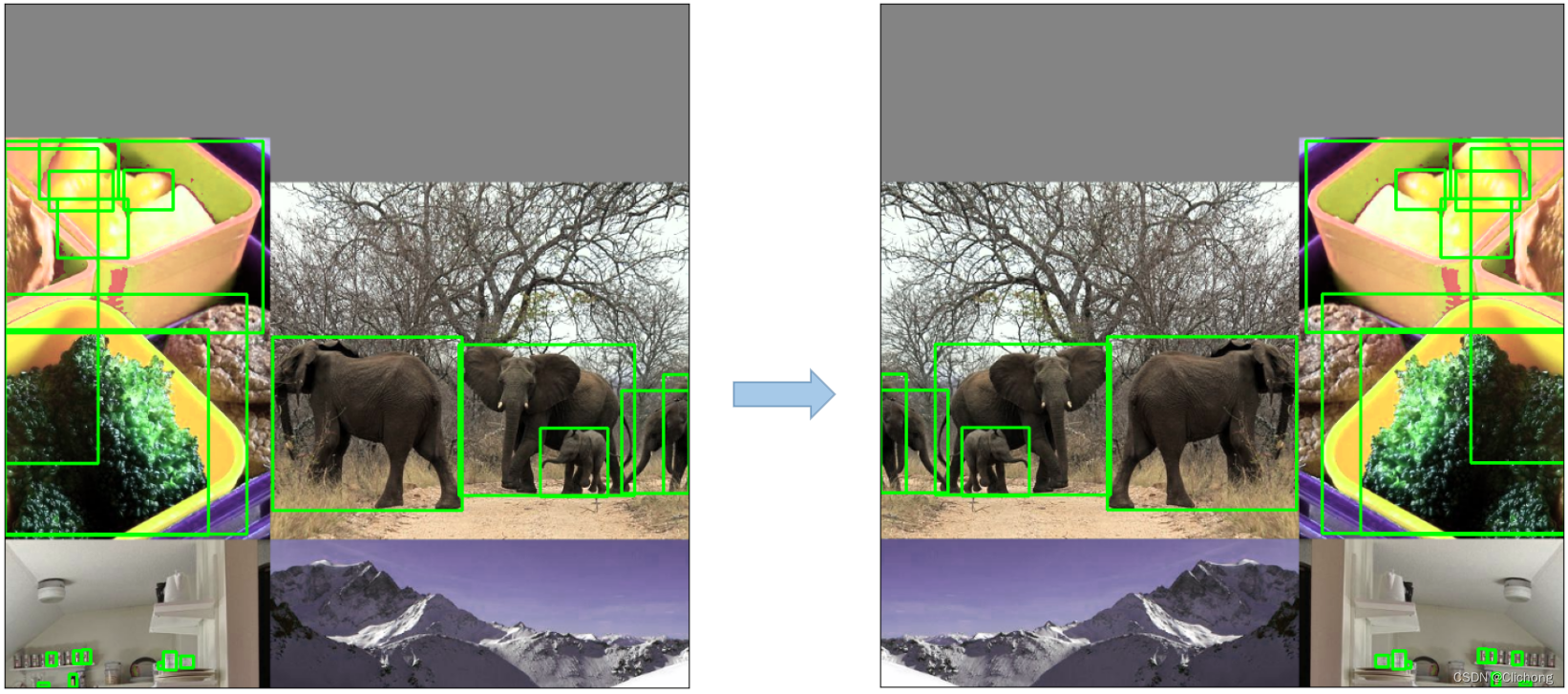
- 实现代码
# Flip up-down
if random.random() < hyp['flipud']:
img = np.flipud(img)
if nl:
labels[:, 2] = 1 - labels[:, 2]
# Flip left-right
if random.random() < hyp['fliplr']:
img = np.fliplr(img)
if nl:
labels[:, 1] = 1 - labels[:, 1]
7. Cutout数据增强
Cutout是一种新的正则化方法。训练时随机把图片的一部分减掉,这样能提高模型的鲁棒性。它的来源是计算机视觉任务中经常遇到的物体遮挡问题。通过cutout生成一些类似被遮挡的物体,不仅可以让模型在遇到遮挡问题时表现更好,还能让模型在做决定时更多地考虑环境。
Cutout数据增强在之前也见过很多次了。在yolov5的代码中默认也是不启用的。
- 操作实例
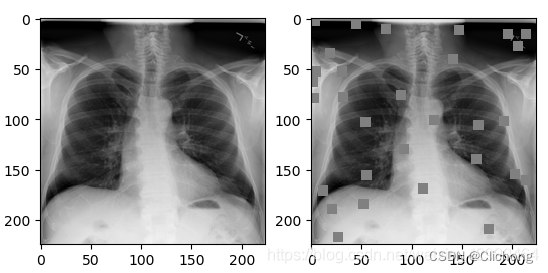
- 实现代码
def cutout(im, labels, p=0.5):
# Applies image cutout augmentation https://arxiv.org/abs/1708.04552
if random.random() < p:
h, w = im.shape[:2]
scales = [0.5] * 1 + [0.25] * 2 + [0.125] * 4 + [0.0625] * 8 + [0.03125] * 16 # image size fraction
for s in scales:
mask_h = random.randint(1, int(h * s)) # create random masks
mask_w = random.randint(1, int(w * s))
# box
xmin = max(0, random.randint(0, w) - mask_w // 2)
ymin = max(0, random.randint(0, h) - mask_h // 2)
xmax = min(w, xmin + mask_w)
ymax = min(h, ymin + mask_h)
# apply random color mask
im[ymin:ymax, xmin:xmax] = [random.randint(64, 191) for _ in range(3)]
# return unobscured labels
if len(labels) and s > 0.03:
box = np.array([xmin, ymin, xmax, ymax], dtype=np.float32)
ioa = bbox_ioa(box, labels[:, 1:5]) # intersection over area
labels = labels[ioa < 0.60] # remove >60% obscured labels
return labels
源码中默认是不启动的
# Cutouts
# labels = cutout(img, labels, p=0.5)
8. Albumentations数据增强工具包
Albumentations 数据增强工具包在之前已经介绍过,见:Yolo系列 | Yolov4v5的模型结构与正负样本匹配
- github地址:https://github.com/albumentations-team/albumentations
- docs使用文档:https://albumentations.ai/docs
其涵盖了绝大部分的数据增强方式,如下:

- yolov5代码
class Albumentations:
# YOLOv5 Albumentations class (optional, only used if package is installed)
def __init__(self):
self.transform = None
try:
import albumentations as A
check_version(A.__version__, '1.0.3') # version requirement
self.transform = A.Compose([
A.Blur(p=0.01),
A.MedianBlur(p=0.01),
A.ToGray(p=0.01),
A.CLAHE(p=0.01),
A.RandomBrightnessContrast(p=0.0),
A.RandomGamma(p=0.0),
A.ImageCompression(quality_lower=75, p=0.0)],
bbox_params=A.BboxParams(format='yolo', label_fields=['class_labels']))
logging.info(colorstr('albumentations: ') + ', '.join(f'{
x}' for x in self.transform.transforms if x.p))
except ImportError: # package not installed, skip
pass
except Exception as e:
logging.info(colorstr('albumentations: ') + f'{
e}')
def __call__(self, im, labels, p=1.0):
if self.transform and random.random() < p:
new = self.transform(image=im, bboxes=labels[:, 1:], class_labels=labels[:, 0]) # transformed
im, labels = new['image'], np.array([[c, *b] for c, b in zip(new['class_labels'], new['bboxes'])])
return im, labels
- 自己调用代码
import albumentations as A
class Albumentations:
# YOLOv5 Albumentations class (optional, only used if package is installed)
def __init__(self):
self.transform = A.Compose([
A.Blur(p=0.15), # 随机模糊
A.GaussianBlur(p=0.15), # 高斯滤波器模糊
A.MedianBlur(p=0.15), # 中值滤波器模糊输入图像
A.GaussNoise(p=0.15), # 高斯噪声应用于输入图像
A.InvertImg(0.15), # 通过从255中减去像素值来反转输入图像
A.ToGray(p=0.15), # 将输入的 RGB 图像转换为灰度
A.CLAHE(p=0.15), # 自适应直方图均衡
A.ChannelShuffle(p=0.15), # 随机重新排列输入 RGB 图像的通道
A.ColorJitter(p=0.25), # 随机改变图像的亮度、对比度和饱和度
A.FancyPCA(p=0.25), # 使用FancyPCA增强RGB图像
A.Sharpen(p=0.15), # 锐化输入图像并将结果与原始图像叠加
A.HueSaturationValue(p=0.15), # 随机改变输入图像的色调、饱和度和值
A.RandomBrightnessContrast(p=0.15), # 随机改变输入图像的亮度和对比度
# 与random_perspective函数重复
# A.Rotate(limit=20, p=0.35), # 随机旋转
# A.HorizontalFlip(p=0.35), # 水平翻转
# A.VerticalFlip(p=0.35), # 垂直翻转
# A.Perspective(p=0.35), # 透视变换
A.ImageCompression(quality_lower=75, p=0.01)], # 减少图像的 Jpeg、WebP 压缩
# yolo格式的边界框坐标的格式: [x_center, y_center, width, height]
bbox_params=A.BboxParams(format='yolo', label_fields=['class_labels']))
logging.info(colorstr('albumentations: ') + ', '.join(f'{
x}' for x in self.transform.transforms if x.p))
def __call__(self, im, labels, p=1.0):
if self.transform and random.random() < p:
new = self.transform(image=im, bboxes=labels[:, 1:], class_labels=labels[:, 0]) # transformed
im, labels = new['image'], np.array([[c, *b] for c, b in zip(new['class_labels'], new['bboxes'])])
return im, labels
可以看见,使用方法类似于pytorch的transform。使用的方法是类似的。
不过,在Albumentations提供的数据增强方式比pytorch官方的更多,使用也比较方便。
参考资料:
2. YOLOv5 (6.0/6.1) brief summary
边栏推荐
猜你喜欢
IEEE的论文哪里可以下载?

Starting a new journey - Mr. Maple Leaf's first blog
8. WEB 开发-静态资源访问

Why do programming languages have the concept of variable types?
SAS data processing technology (1)
![[C language] binary search (half search)](/img/24/4e7b54963ac9df4a3244232c32c435.png)
[C language] binary search (half search)
15. 拦截器-HandlerInterceptor
![[Excel knowledge and skills] Convert text numbers to numeric format](/img/7e/16a068025ec2639b343436c7f5b245.png)
[Excel knowledge and skills] Convert text numbers to numeric format
14. Thymeleaf
Geogebra 教程之 02 Geogebra初学者的 8 个基本要素
随机推荐
2022下半年软考「高项」易混淆知识点汇总(2)
9. Rest style request processing
Design and Realization of Employment Management System in Colleges and Universities
Promise in detail
SQL injection base - order by injection, limit, wide byte
C language, operators of shift operators (> >, < <) explanation
VR全景+安全科普教育,让学生们提高安全意识
Excel English automatic translation into Chinese tutorial
2. Dependency management and automatic configuration
Lens filter---about day and night dual-pass filter
鲲鹏编译调试及原生开发工具基础知识
NOR FLASH闪存芯片ID应用之软件保护场景
Is there a way out in the testing industry if it is purely business testing?
Jvm.分析工具(jconsole,jvisualvm,arthas,jprofiler,mat)
后疫情时代,VR全景营销这样玩更加有趣!
[21天学习挑战赛——内核笔记](五)——devmem读写寄存器调试
proxy代理服务_2
高校就业管理系统设计与实现
给肯德基打工的调料商,年赚两亿
11. Custom Converter