当前位置:网站首页>Dolphinscheduler集成Flink任务踩坑记录
Dolphinscheduler集成Flink任务踩坑记录
2022-04-23 06:03:00 【若小鱼】
1、关于Flink打包
flink任务编写完成,在本地运行调试正常后,我打包提交到Dolphinscheduler平台进行测试。运行后没多久就报错:
[taskAppId=TASK-10-108-214]:[138] - -> java.lang.NoClassDefFoundError: org/apache/flink/streaming/connectors/kafka/FlinkKafkaConsumer
at com.bigdata.flink.FlinkKafka.main(FlinkKafka.java:30)
Caused by: java.lang.ClassNotFoundException: org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer

看日志详情,我们可以看到任务已经开始准备提交了,但是在环境里找不到FlinkKafkaConsumer。
flink run -m yarn-cluster -ys 1 -yjm 1G -ytm 2G -yqu default -p 1 -sae -c com.bigdata.flink.FlinkKafka flink-job/bigdata-flink.jar
我的打包方式是通过IDEA 菜单的Build Artfacts…打出的jar文件很小,而且依赖包也都没有被打进去。
于是换了一种方式:
- 配置pom文件
<build>
<!--<pluginManagement>-->
<plugins>
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>build-helper-maven-plugin</artifactId>
<version>1.8</version>
<executions>
<execution>
<id>add-source</id>
<phase>generate-sources</phase>
<goals>
<goal>add-source</goal>
</goals>
<configuration>
<sources>
<source>src/main/scala</source>
<source>src/test/scala</source>
</sources>
</configuration>
</execution>
<execution>
<id>add-test-source</id>
<phase>generate-sources</phase>
<goals>
<goal>add-test-source</goal>
</goals>
<configuration>
<sources>
<source>src/test/scala</source>
</sources>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.1.5</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
<configuration>
<scalaVersion>2.11.8</scalaVersion>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>utf-8</encoding>
</configuration>
<executions>
<execution>
<phase>compile</phase>
<goals>
<goal>compile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<appendAssemblyId>false</appendAssemblyId>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<!-- 此处指定main方法入口的class -->
<mainClass>com.bigdata.flink.FlinkKafka</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>assembly</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
<!--</pluginManagement>-->
</build>
- 执行maven下的package命令;可以看到这种打包方式执行后的jar包里包含了所需的依赖包。
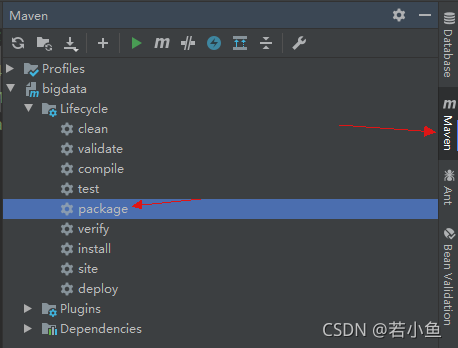
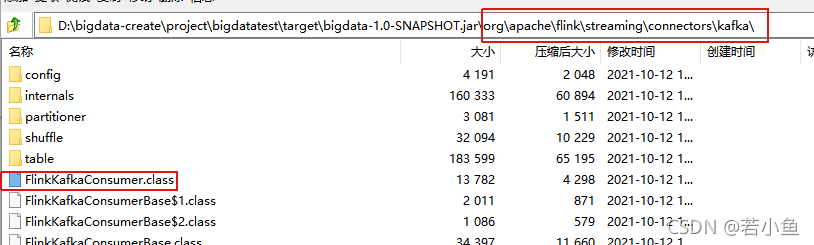
2、HADOOP_CLASSPATH环境变量配置
环境依赖的问题解决后,在执行中又出现了HADOOP_CLASSPATH环境变量的报错。
taskAppId=TASK-10-112-218]:[138] - ->
------------------------------------------------------------
The program finished with the following exception:
org.apache.flink.client.program.ProgramInvocationException: The main method caused an error: No Executor found. Please make sure to export the HADOOP_CLASSPATH environment variable or have hadoop in your classpath. For more information refer to the "Deployment" section of the official Apache Flink documentation.
at org.apache.flink.client.program.PackagedProgram.callMainMethod(PackagedProgram.java:372)
at org.apache.flink.client.program.PackagedProgram.invokeInteractiveModeForExecution(PackagedProgram.java:222)
at org.apache.flink.client.ClientUtils.executeProgram(ClientUtils.java:114)
at org.apache.flink.client.cli.CliFrontend.executeProgram(CliFrontend.java:812)
at org.apache.flink.client.cli.CliFrontend.run(CliFrontend.java:246)
at org.apache.flink.client.cli.CliFrontend.parseAndRun(CliFrontend.java:1054)
at org.apache.flink.client.cli.CliFrontend.lambda$main$10(CliFrontend.java:1132)
at org.apache.flink.runtime.security.contexts.NoOpSecurityContext.runSecured(NoOpSecurityContext.java:28)
at org.apache.flink.client.cli.CliFrontend.main(CliFrontend.java:1132)
Caused by: java.lang.IllegalStateException: No Executor found. Please make sure to export the HADOOP_CLASSPATH environment variable or have hadoop in your classpath. For more information refer to the "Deployment" section of the official Apache Flink documentation.
这次需要修改worker所在节点的flink文件。
- 找到 flink/bin/flink文件
- 在第一行加入
export HADOOP_CLASSPATH=`hadoop classpath`
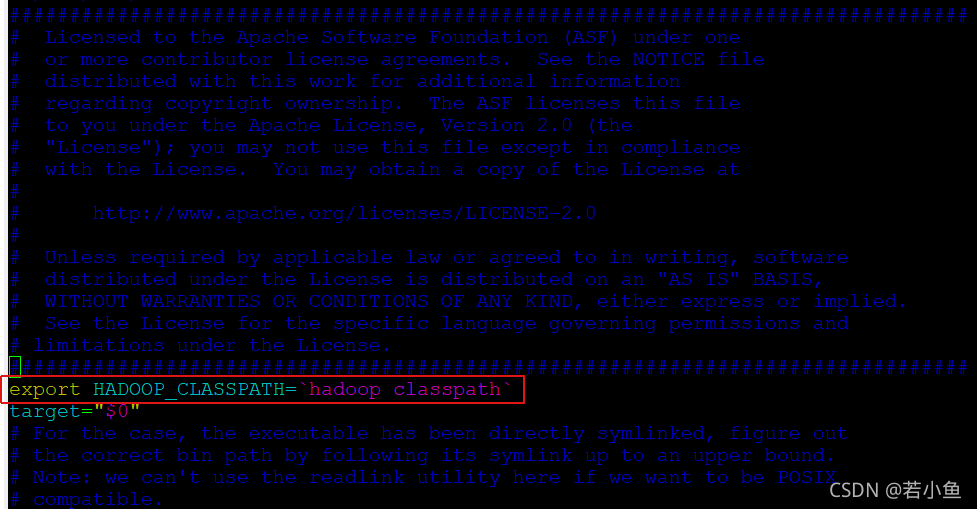
- 无需重启集群机器,直接重跑flink任务即可。
版权声明
本文为[若小鱼]所创,转载请带上原文链接,感谢
https://blog.csdn.net/weixin_44162809/article/details/121563639
边栏推荐
- 【Lombok快速入门】
- Winter combat camp hands-on combat - cloud essential environment preparation, hands-on practical operation, quickly build lamp environment, lead mouse cloud Xiaobao backpack without shadow
- 异常记录-15
- Openvswitch compilation and installation
- 通过源码探究@ModelAndView如何实现数据与页面的转发
- Build a cloud blog based on ECS (polite experience)
- VirtualBox如何修改“网络地址转换(NAT)”网络模式下分配给虚拟机的IP网段
- 10g数据库使用大内存主机时不能启动的问题
- Thanos Compactor组件使用
- MySQL【ACID+隔离级别+ redo log + undo log】
猜你喜欢

Dolphinscheduler调度spark任务踩坑记录

Winter combat camp hands-on combat - MySQL database rapid deployment practice lead mouse cloud Xiaobao
Chaos带你快速上手混沌工程

OVS and OVS + dpdk architecture analysis
Prometheus Thanos快速指南

Implementation of multi tenant read and write in Prometheus cortex

实践使用PolarDB和ECS搭建门户网站

10g数据库使用大内存主机时不能启动的问题

Typical application scenarios of alicloud log service SLS

qs.stringify 接口里把入参转为&连接的字符串(配合application/x-www-form-urlencoded请求头)
随机推荐
volatile 关键字的三大特点【数据可见性、指令禁止重排性、不保证操作原子性】
如何通过dba_hist_active_sess_history分析数据库历史性能问题
将数组中指定的对象排在数组的前边
Alertmanager重复/缺失告警现象探究及两个关键参数group_wait和group_interval的释义
Thanos compact component test summary (processing historical data)
Ali vector library Icon tutorial (online, download)
ORACLE环境遇到的ORA-600 [qkacon:FJswrwo]
PG SQL截取字符串到指定字符位置
[shell script exercise] batch add the newly added disks to the specified VG
异常记录-21
prometheus告警记录持久化(历史告警保存与统计)
阿里矢量库的图标使用教程(在线,下载)
Thanos如何为不同租户配置不同的数据保留时长
ORACLE表有逻辑坏块时EXPDP导出报错排查
Practice using polardb and ECs to build portal websites
Prometheus Thanos快速指南
[ES6 quick start]
Oracle Performance Analysis Tool: oswatcher
Prometheus alarm record persistence (historical alarm saving and Statistics)
用反射与注解获取两个不同对象间的属性值差异