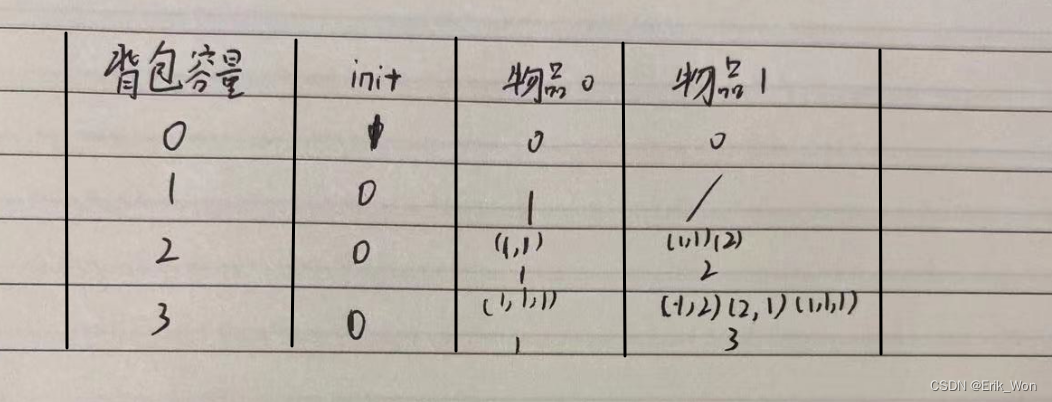
模型蒸馏旨在将教师模型的知识传递给学生模型。一般而言,蒸馏损失函数设置为两个模型输出层的 MSE 或 KL 散度,通过加入内层知识蒸馏(教师模型的中间层向学生模型中间层传递知识)可以在此基础上进一步提升学生模型的表现。然而,内层知识蒸馏存在 skip and search problem ,不容易找到合适的内层映射方式。
本文提出了 RAIL-KD (RAndom Intermediate Layer Knowledge Distillation) 方法,在每一轮训练时,随机选取教师模型的中间层与学生模型中间层建立映射,进行知识蒸馏。可以有效地减少额外计算开销,并且可以有效提升学生模型的泛化能力。

论文标题:
RAIL-KD: RAndom Intermediate Layer Mapping for Knowledge Distillation
论文链接: