当前位置:网站首页>【ECCV 2022|百万奖金】PSG大赛:追求“最全面”的场景理解
【ECCV 2022|百万奖金】PSG大赛:追求“最全面”的场景理解
2022-08-10 12:35:00 【我爱计算机视觉】
关注公众号,发现CV技术之美

Panoptic Scene Graph Generation
Accepted to ECCV'22 (Paper ID #222, Final Score 2222) 【百年一遇的二?】
Paper link: https://arxiv.org/abs/2207.11247
Project Page: https://psgdataset.org/
OpenPSG Codebase: https://github.com/Jingkang50/OpenPSG
Competition Link: https://www.cvmart.net/race/10349/base
ECCV’22 SenseHuman Workshop Link: https://sense-human.github.io/
基于本论文的PSG比赛已于8月6日正式开始。该赛事隶属于粤港澳大湾区(黄埔)国际算法算例大赛,由琶洲实验室(黄埔)主办,与ECCV’22 SenseHuman Workshop联动。PSG比赛赛道奖金池100万人民币,期待大家报名参加,一同探索最全面的场景理解!
具体赛事信息更新请关注 https://iacc.pazhoulab-huangpu.com/
PSG赛道具体信息请关注 https://github.com/Jingkang50/OpenPSG

PSG模型效果展示
虽然今年已经2022年了,但是当下大多数的计算机视觉任务却仍然只关注于图像感知。比如说,图像分类任务只需要模型识别图像中的物体物体类别。虽然目标检测,图像分割等任务进一步要求找到物体的位置,然而,此类任务仍然不足以说明模型获得了对场景全面深入的理解。以下图1为例,如果计算机视觉模型只检测到图片中的人、大象、栅栏、树木等,我们通常不会认为模型已经理解了图片,而该模型也无法根据理解做出更高级的决策,例如发出“禁止投喂”的警告。
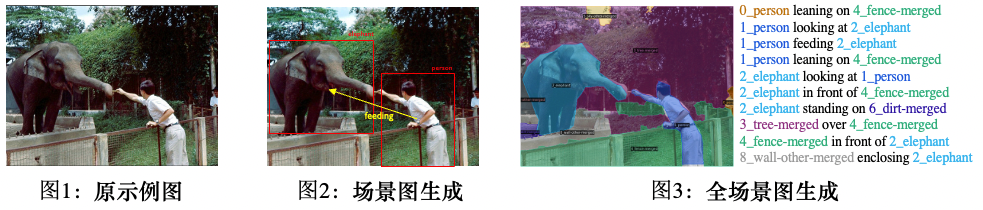
事实上,在智慧城市、自动驾驶、智能制造等许多现实世界的AI场景中,除了对场景中的目标进行定位外,我们通常还期待模型对图像中各个主体之间的关系进行推理和预测。例如,在自动驾驶应用中,自动车需要分析路边的行人是在推车还是在骑自行车。根据不同的情况,相应的后续决策可能都会有所不同。在智能工厂场景中,判断操作员是否操作安全正确也需要监控端的模型有理解主体之间关系的能力。大多数现有的方法都是手动设置一些硬编码的规则。这使得模型缺乏泛化性,难以适应其他特定情况。
场景图生成任务(scene graph generation,或SGG)就旨在解决如上的问题。在对目标物体进行分类和定位的要求之上,SGG任务还需要模型预测对象之间的关系(见图 2)。传统场景图生成任务的数据集通常具有对象的边界框标注,并标注边界框之间的关系。但是,这种设置有几个固有的缺陷:(1)边界框无法准确定位物体:如图2所示,边界框在标注人时不可避免地会包含人周围的物体;(2)背景无法标注:如图2所示,大象身后的树木用bounding box标注,几乎覆盖了整个图像,所以涉及到背景的关系无法准确标注,这也使得场景图无法完全覆盖图像,无法达到全面的场景理解。
因此,我们提出全场景图生成(PSG)任务,携同一个精细标注的大规模PSG数据集。如图 3 所示,该任务利用全景分割来全面准确地定位对象和背景,从而解决场景图生成任务的固有缺点,从而推动该领域朝着全面和深入的场景理解迈进。
我们通过下图的例子再次理解全场景图生成(PSG)任务的优势:

左图来自于SGG任务的传统数据集Visual Genome (VG-150)。可以看到基于检测框的标注通常不准确,而检测框覆盖的像素也不能准确定位物体,尤其是椅子,树木之类的背景。同时,基于检测框的关系标注通常会倾向于的标注一些无聊的关系,如“人有头”,“人穿着衣服”。相比之下,右图中提出的 PSG 任务提供了更全面(包括前景和背景的互动)、更清晰(合适的物体粒度)和更准确(像素级准确)的场景图表示,以推动场景理解领域的发展。
为了支撑我们提出的PSG任务,我们搭建了一个开源代码平台OpenPSG,其中实现了四个双阶段的方法和两个单阶段的方法,方便大家开发、使用、分析。
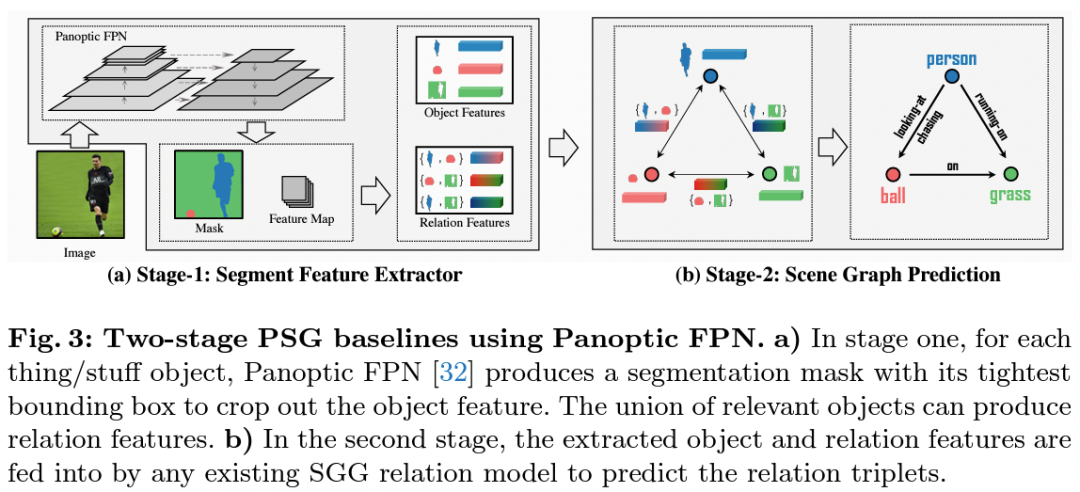
基于Panoptic-FPN的双阶段方法。

基于DETR的单阶段方法。
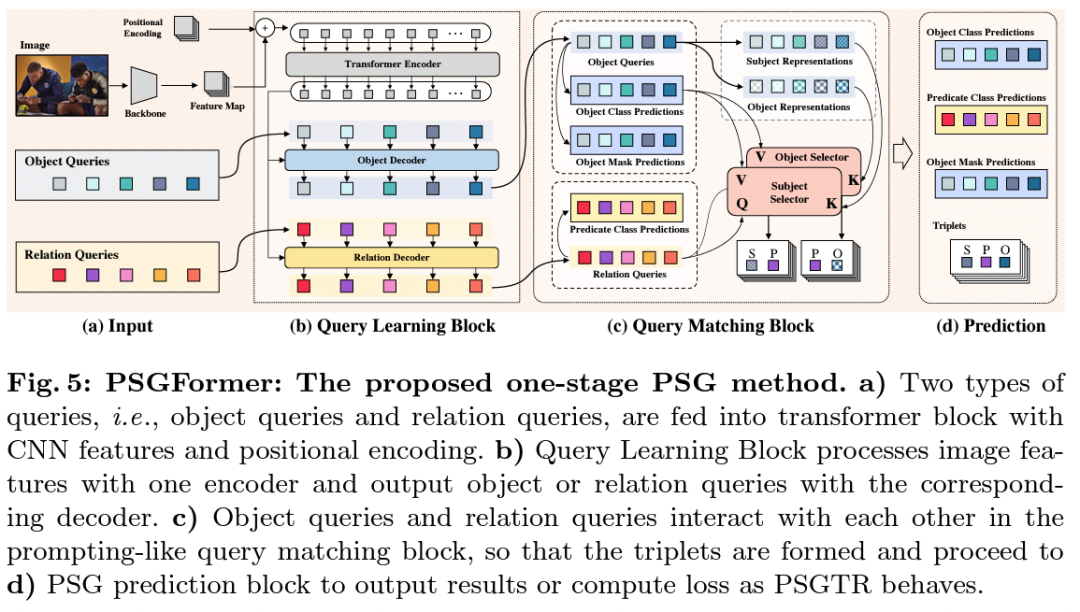
基于双decode的DETR的单阶段方法。
一些结论分享:
大部分在SGG任务上有效的方法在PSG任务上依旧有效。然而有一些利用较强的数据集统计先验,或主谓宾中谓语方向先验的方法可能没那么奏效。这可能是由于PSG数据集相较于传统VG数据集的bias没有那么严重,并且对谓语动词的定义更加清晰可学。因此,我们希望后续的方法关注视觉信息的提取和对图片本身的理解。统计先验可能在刷数据集上有效,但不本质。
相比于双阶段模型,单阶段模型目前能达到更好的效果。这可能得益于单阶段模型有关于关系的监督信号可以直接传递到feature map端,使得关系信号参与了更多的模型学习,有利于对关系的捕捉。但是由于本文只提出了若干基线模型,并没有针对单阶段或双阶段模型进行调优,因此目前还不能说单阶段模型一定强于双阶段模型。这还希望参赛选手继续探索。
相比于传统的SGG任务,PSG任务基于全景分割图进行关系配对,要求对于每个关系中主宾物体的id 进行确认。相比于双阶段直接预测全景分割图完成物体id 的划分,单阶段模型需要通过一系列后处理完成这一步骤。若基于现有单阶段模型进一步改进升级,如何在单阶段模型中更有效的完成物体id的确认,生成更好的全景分割图,仍是一个值得探索的话题。

END
欢迎加入「图像分割」交流群备注:分割

边栏推荐
- Loudi Center for Disease Control and Prevention Laboratory Design Concept Description
- 娄底植物细胞实验室建设基本组成要点
- M²BEV: Multi-Camera Joint 3D Detection and Segmentation with Unified Bird’s-Eye View Representation
- Proprietary cloud ABC Stack, the real strength!
- 娄底污水处理厂实验室建设管理
- Alibaba Cloud Jia Zhaohui: Cloud XR platform supports Bizhen Technology to present a virtual concert of national style sci-fi
- 一种能让大型数据聚类快2000倍的方法,真不戳
- bgp dual plane experiment routing strategy to control traffic
- Real-time data warehouse practice of Baidu user product flow and batch integration
- Efficient and Robust 2D-to-BEV Representation Learning via Geometry-guided Kernel Transformer Paper Notes
猜你喜欢

shell:常用小工具(sort、uniq、tr、cut)

bgp dual plane experiment routing strategy to control traffic

多线程下自旋锁设计基本思想

关于flask中static_folder 和 static_url_path参数理解

漏洞管理计划的未来趋势

漏洞管理计划的未来趋势
wirshark 常用操作及 tcp 三次握手过程实例分析

2022年8月中国数据库排行榜:openGauss重夺榜眼,PolarDB反超人大金仓
bgp双平面实验 路由策略控制流量

Solve the idea that unit tests cannot use Scanner
随机推荐
生成树协议STP(Spanning Tree Protocol)
Custom filters and interceptors implement ThreadLocal thread closure
YTU 2295: KMP模式匹配 一(串)
M²BEV: Multi-Camera Joint 3D Detection and Segmentation with Unified Bird’s-Eye View Representation
神经网络可视化有3D版本了,美到沦陷!(已开源)
Overview of Loudi Petrochemical Experiment Design and Construction Planning
M²BEV: Multi-Camera Joint 3D Detection and Segmentation with Unified Bird’s-Eye View Representation
OTA自动化测试解决方案---整体方案介绍
交换机的基础知识
Prada, big show?In the yuan in the universe that!
中科院深圳先进技术院合成所赵国屏院士组2022年招聘启事
BEVDet4D: Exploit Temporal Cues in Multi-camera 3D Object Detection 论文笔记
「企业架构」应用架构概述
查看 CUDA cudnn 版本 & 测试 cuda 和 cudnn 有效性「建议收藏」
专有云ABC Stack,真正的实力派!
C#报错 The ‘xmins‘ attribute is not supported in this context
瑞幸「翻身」?恐言之尚早
Solve the idea that unit tests cannot use Scanner
Blast!ByteDance successfully landed, only because the interview questions of LeetCode algorithm were exhausted
一文详解 implementation api embed