当前位置:网站首页>AVH 动手实践 (二) | 在 Arm 虚拟硬件上部署 PP-OCR 模型
AVH 动手实践 (二) | 在 Arm 虚拟硬件上部署 PP-OCR 模型
2022-08-11 03:53:00 【飞桨PaddlePaddle】

本期课程,小编将基于计算机视觉领域光学字符识别(OCR)任务中的文本识别任务,带领大家动手完成从模型训练优化到深度学习应用部署的整个端到端的开发流程。你不仅会了解到如何使用飞桨文字识别套件PaddleOCR工具套件完成英文识别模型的训练与适配,还会了解到如何使用深度学习编译器TVM编译飞桨模型并将其直接部署在含有Arm Cortex-M55处理器的Arm Corstone-300虚拟硬件上。
百度与Arm的此次合作,填补了飞桨模型在Arm Cortex-M硬件上的适配空白,同时也增加了Cortex-M硬件上支持的深度学习模型的数量,为开发者提供了更多的选择。
项目概述
经典的深度学习工程是从确认任务目标开始的,我们首先来简单地介绍一下OCR 中的文本识别任务以及本期部署实战课程中我们所使用的工具和平台。
1.1 文本识别任务
文本识别是OCR的一个子任务,旨在识别一个固定区域的的文本内容。在OCR的两阶段方法里,它接在文本检测后面,将图像信息转换为文字信息。在卡证、票据信息抽取与审核、制造业产品溯源、政务医疗文档电子化等产业场景中应用广泛。

图 1:英文文本识别案例(图片来源:ICDAR2015)
1.2 PP-OCRv3
如下图2所示,PP-OCRv3的整体框架示意图与PP-OCRv2类似,但较PP-OCRv2而言,PP-OCRv3针对检测模型和识别模型进行了进一步地优化。例如: 文本识别PP-OCRv3的文本识别模型在PP-OCRv2的基础上引入SVTR,并使用GTC指导训练和模型蒸馏。
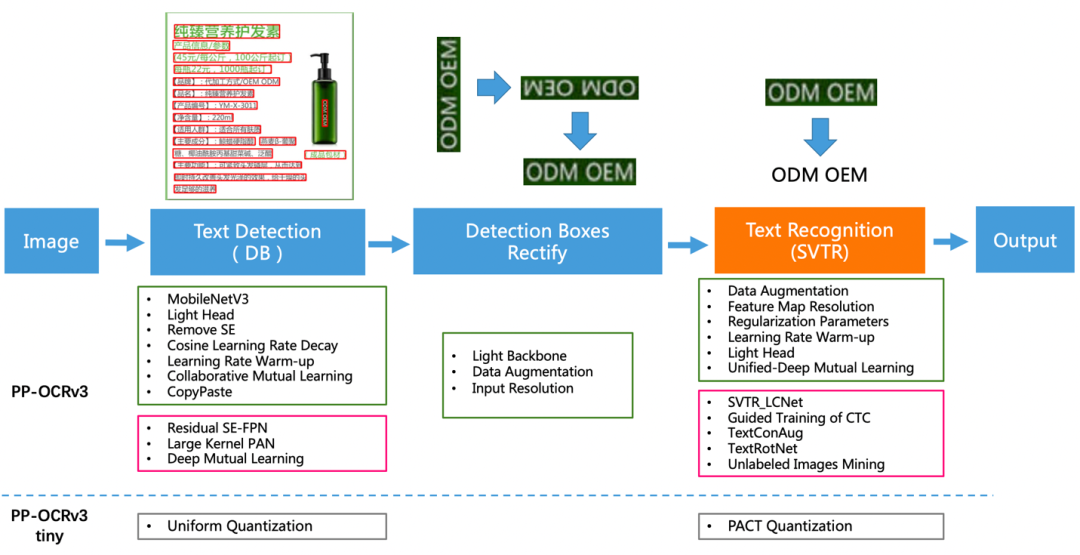
图2:PP-OCRv3系统框图
更多关于PP-OCRv3的特征及优化策略,可查看PP-OCRv3 arXiv技术报告[5].
1.3 Arm虚拟硬件(Arm Virtual Hardware, AVH)
作为Arm物联网全面解决方案的核心技术之一,AVH很好地解决了实体硬件所面临的难扩展、难运维等痛点。AVH提供了简单便捷并且可扩展的途径,让IoT应用的开发摆脱了对实体硬件的依赖并使得云原生开发技术在嵌入式物联网、边缘侧机器学习领域得到了应用。尤其是在芯片紧张的当今时代,使用AVH开发者甚至可以在芯片RTL之前便可接触到最新的处理器IP。
目前AVH提供两种形式供开发者使用。一种是托管在AWS以及AWS China上以亚马逊机器镜像AMI形式存在的Arm Corstone和Cortex CPU的虚拟硬件,另外一种则是由Arm以SaaS平台的形式提供的 AVH 第三方硬件。本期课程我们将使用第一种托管在AWS以及AWS China上以亚马逊机器镜像AMI形式存在的Corstone和Cortex CPU的虚拟硬件。
由于目前AWS China账号主要面向企业级开发者开放,个人开发者可访问AWS Marketplace订阅AVH相关服务。参考图3步骤创建AVH AMI实例。
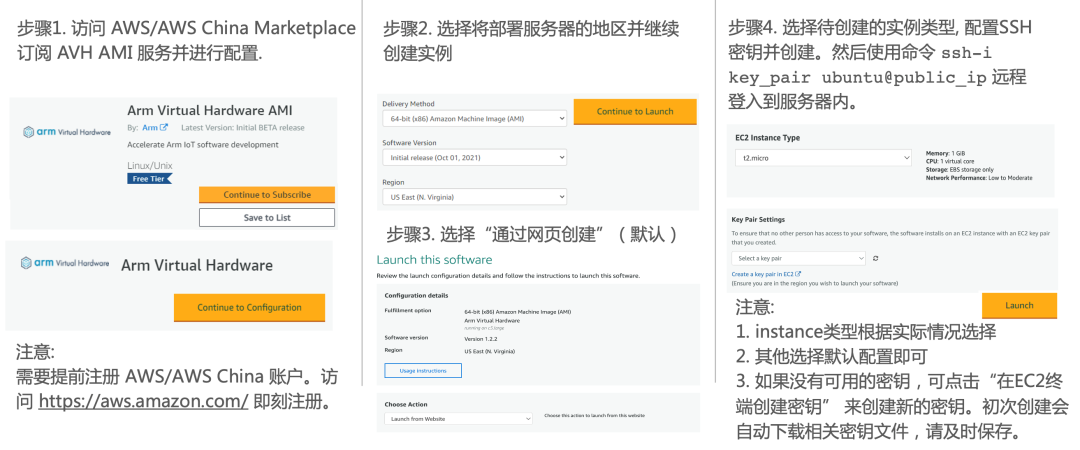
图 3:AVH AMI 创建步骤
(访问AWS Marketplace [6]订阅AVH)
端到端部署流程
接下来小编将重点向大家展示从模型训练到部署的全流程,本期课程所涉及的相关代码已在GitHub仓库开源,欢迎大家下载体验!
https://github.com/PaddlePaddle/PaddleOCR/tree/dygraph/deploy/avh
(位于PaddleOCR的分支下deploy目录的avh文件目录中)
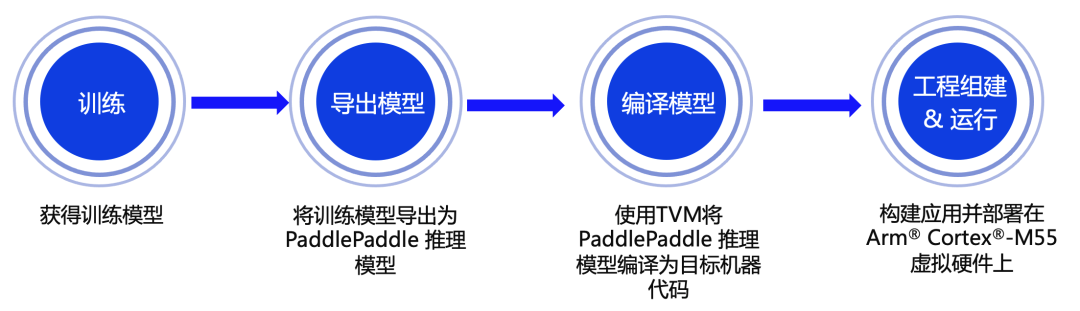
图4:端到端部署流程示意图
2.1 模型训练
PaddleOCR模型使用配置文件(.yml)管理网络训练、评估的参数。在配置文件中,可以设置组建模型、优化器、损失函数、模型前后处理的参数。PaddleOCR从配置文件中读取到这些参数,进而组建出完整的训练流程,完成模型训练。在需要对模型进行优化时,可以通过修改配置文件中的参数完成配置(完整的配置文件说明可以参考文档:配置文件内容与生成[7]),使用简单且便于修改。
为实现与Cortex-M的适配,在模型训练时我们需要修改所使用的配置文件[8]。去掉不支持的算子,同时为优化模型,在模型调优部分使用了BDA (Base Data Augmentation),其包含随机裁剪、随机模糊、随机噪声、图像反色等多个基础数据增强方法。相关配置文件可参考如下代码。
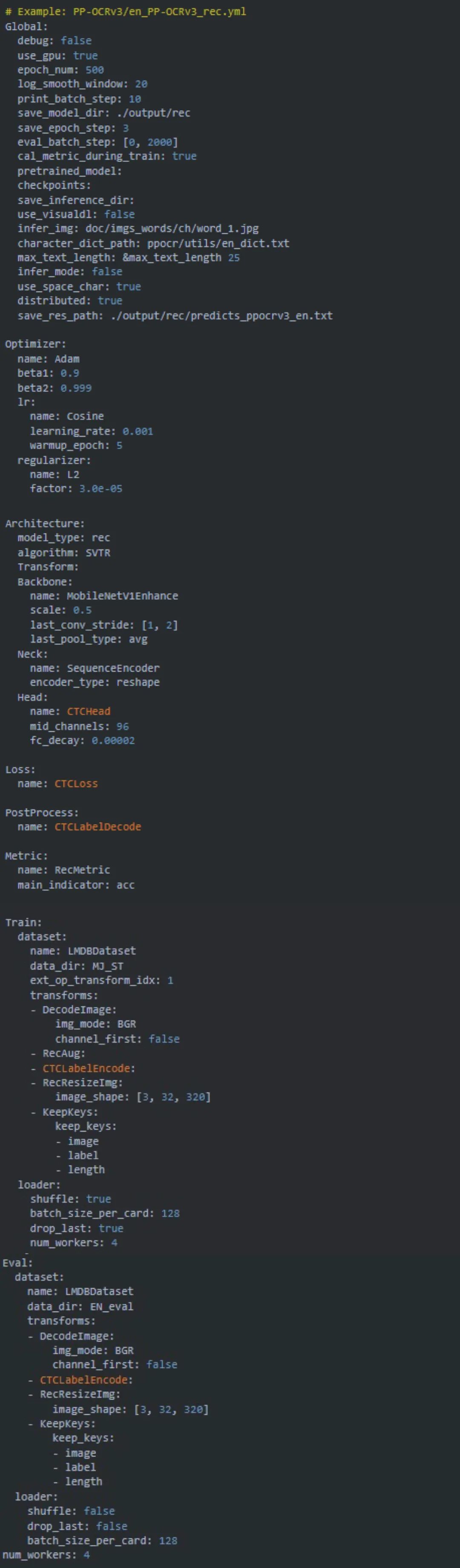
我们使用网上开源英文数据集MJ+ST作为训练测试数据集,并通过以下命令进行模型训练。模型训练周期与训练环境以及数据集大小等均密切相关,大家可根据自身需求进行配置。
# Example training commandpython3 tools/train.py -c configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml -o \ Global. save_model_dir=output/rec/ \ Train.dataset.name=LMDBDataSet \Train.dataset.data_dir=MJ_ST \Eval.dataset.name=LMDBDataSet \Eval.dataset.data_dir=EN_eval \2.2 模型导出
模型训练完成后,还需要将训练好的文本识别模型转换为Paddle Inference模型,才能使用深度学习编译器TVM对其进行编译从而获得适配在Cortex-M处理器上运行的代码。可以参考以下命令导出Paddle Inference模型。
# Example exporting model commandpython3 tools/export_model.py \-c configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml -o \ Global.pretrained_model=output/rec/best_accuracy.pdparams \ Global.save_inference_dir=output/rec/inferInference模型导出后,可以通过以下命令使用PaddleOCR进行推理验证。为便于各位开发者可直接体验和部署,大家可以通过下方链接直接下载我们训练完成并导出的英文文本识别Inference模型。
https://paddleocr.bj.bcebos.com/tvm/ocr_en.tar
# Example infer commandpython3 tools/infer/predict_rec.py --image_dir="path_to_image/word_116.png" \--rec_model_dir="path_to_infer_model/ocr_en" \ --rec_char_dict_path="ppocr/utils/en_dict.txt" \--rec_image_shape="3,32,320"我们使用与后续部署中相同的图进行验证,如下图5所示。预测结果为如下,与图片一致且具有较高的置信度评分,说明我们的推理模型已经基准备完毕了。
Predicts of /Users/lilwu01/Desktop/word_116.png:('QBHOUSE', 0.9867456555366516)
图 5:word_116.png
2.3 模型编译
为实现在Cortex-M上直接完成飞桨模型的部署,我们需要借助深度学习编译器 TVM 来进行相应模型的转换和适配。TVM是一款开源的深度学习编译器, 主要用于解决将各种深度学习框架部署到各种硬件设备上的适配性问题。
如图6所示,它可以接收由飞桨等经典的深度学习训练框架编写的模型并将其转换成可在目标设备上运行推理任务的代码。
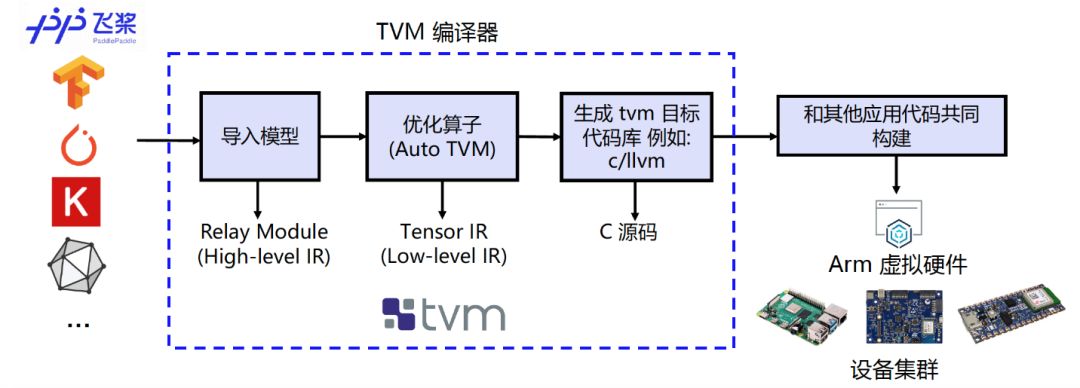
图 6:编译流程示意图
(了解 TVM 更多信息,请访问https://tvm.apache.org)
我们使用TVM的Python应用程序tvmc来完成模型的编译。大家可参考如下命令对Paddle Inference模型进行编译。通过指定 --target=cmsis-nn,c使得模型中CMSIS NN[9] 库支持的算子会卸载到调用CMSIS NN库执行,而不支持的算子则会回调到C代码库。
# Example of Model compiling using tvmcpython3 -m tvm.driver.tvmc compile \path_to_infer_model/ocr_en/inference.pdmodel \ --target=cmsis-nn,c \ --target-cmsis-nn-mcpu=cortex-m55 \ --target-c-mcpu=cortex-m55 \ --runtime=crt \ --executor=aot \ --executor-aot-interface-api=c \ --executor-aot-unpacked-api=1 \ --pass-config tir.usmp.enable=1 \ --pass-config tir.usmp.algorithm=hill_climb \ --pass-config tir.disable_storage_rewrite=1 \--pass-config tir.disable_vectorize=1 \ --output-format=mlf \ --model-format=paddle \ --module-name=rec \ --input-shapes x:[1,3,32,320] \ --output=rec.tar更多关于参数配置详情见:tvmc compile --help。编译后的模型可在–output参数指定路径下查看。(此处为当前目录下的rec.tar压缩包内)2.4 模型部署
参考图3所示的AVH AMI实例 (instance) 创建的流程并通过ssh命令远程登录到实例中去,当看到如图7下所示的提示画面说明已经成功登入。
图7:AVH AMI 成功登录界面
成功登入后大家可以切换到“/opt/VHT” 以及“/opt”目录下查看当前版本AVH AMI所支持的Corstone和Cortex CPU虚拟硬件。下8图为部分1.2.3版本AVH AMI所支持的AVH列表。本期部署课程中所使用的正是Corstone-300虚拟硬件 (VHT_Corstone_SSE-300_Ethos-U55),其内含有Cortex-M55处理器,Arm Ethos-U55处理器及一些基本外设。更多关于Corstone-300虚拟硬件的相关信息,欢迎访问Arm开发者社区的技术文档[10]技术文档进行查看。
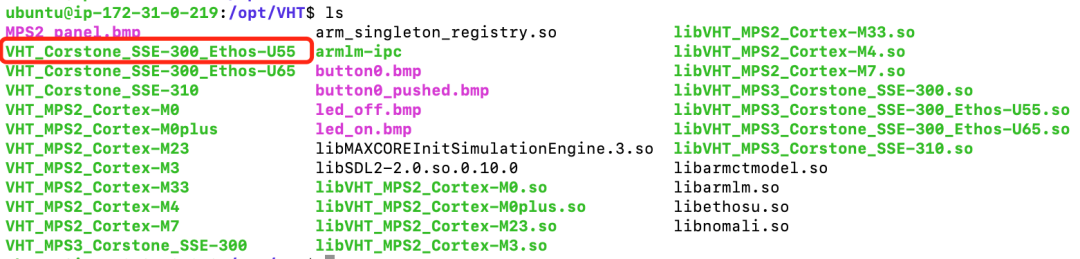
图 8:1.2.3 版本 AVH AMI 所支持的 AVH 部分示意图
2.1-2.3 中所述的模型训练、导出、编译等步骤均可以选择在本地机器上完成或者在AVH AMI中完成,大家可根据个人需求确定。为便于开发者朋友更直观地体验如何在AVH上完成飞桨模型部署,我们为大家提供了部署的示例代码来帮助大家自动化的完成环境配置,机器学习应用构建以及在含有Cortex-M55的Corstone-300虚拟硬件上执行并获取结果。
登入AVH AMI实例后,可以输入以下命令来完成模型部署和查看应用执行结果。run_demo.shrun_demo.sh [11]脚本将会执行图9所示的以下6个步骤来自动化的完成应用构建和执行,执行结果如图10所示。
$ git clone https://github.com/PaddlePaddle/PaddleOCR.git $ cd PaddleOCR$ git pull origin dygraph$ cd deploy/avh $ ./run_demo.sh
图 9:部署流程示意图 (run_demo.sh 脚本中定义)
不难看出,该飞桨英文识别模型在含有Cortex-M55处理器的Corstone-300虚拟硬件上的推理结果与2.2章节中在服务器主机上直接进行推理的推理结果高度一致,说明将飞桨PaddlePaddle模型直接部署在Cortex-M55虚拟硬件上运行良好。
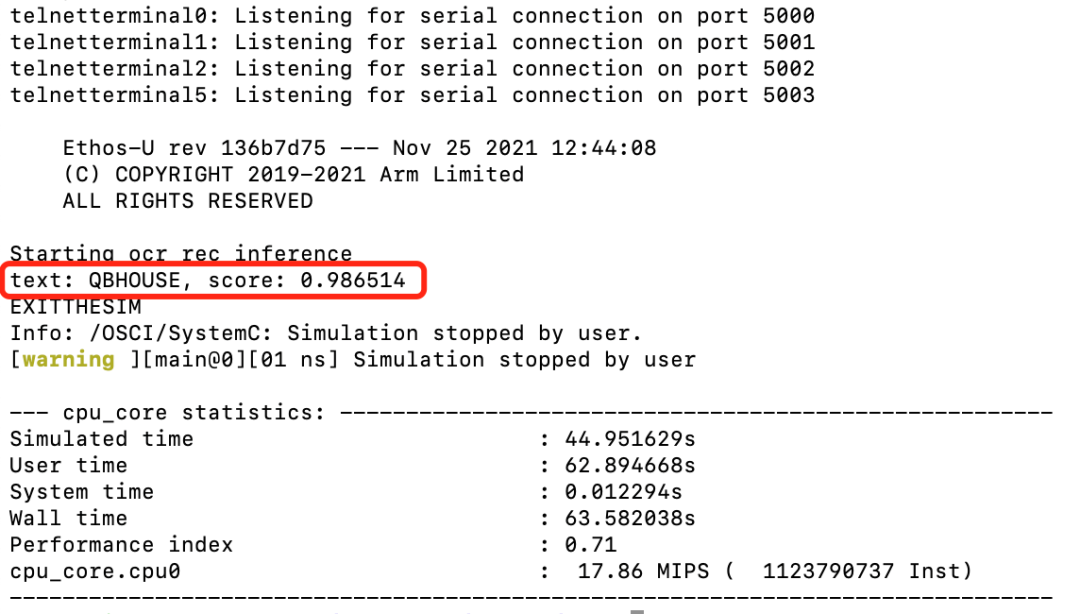
图 10:Corstone-300 (含 Cortex-M55)虚拟硬件运行结果
总结
本期课程,小编带领大家学习了如何将PP-OCRv3中发布的英文识别模型 (完成算子适配后) 部署在Corstone-300的虚拟硬件平台上。在下期推送中,我们将以计算机视觉领域的目标检测任务(Detection)为目标,一步步地带领大家动手完成从模型训练优化到深度学习应用部署的整个端到端的开发流程,敬请期待下一期内容:AVH动手实践 (三) |在Arm虚拟硬件上部署PP-PicoDet模型。
参考链接集锦:
[1] 飞桨官网:https://www.paddlepaddle.org.cn
[2] PaddleOCR GitHub:
https://github.com/PaddlePaddle/PaddleOCR
[3] Arm虚拟硬件(AVH)官网: https://avh.arm.com/
[4] Arm虚拟硬件第三方硬件平台注册报名链接: https://www.arm.com/resources/contact-us/virtual-hardware-boards
[5] PP-OCRv3 arXiv 技术报告:
https://arxiv.org/abs/2206.03001v2
[6] AWS Marketplace:
https://aws.amazon.com/marketplace/pp/prodview-urbpq7yo5va7g?ref_=unifiedsearch
[7] 配置文件内容与生成:
https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.5/doc/doc_ch/config.md
[8] 英文文本识别模型配置文件:
https://github.com/PaddlePaddle/PaddleOCR/blob/dygraph/configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml
[9] Arm CMSIS NN GitHub:
https://github.com/ARM-software/CMSIS_5/tree/develop/CMSIS/NN
[10] Arm Corstone SSE-300技术参考文档:
https://developer.arm.com/documentation/101773/latest
[11] 示例代码中run_demo.sh脚本:
https://github.com/PaddlePaddle/PaddleOCR/blob/dygraph/deploy/avh/run_demo.sh

关注【飞桨PaddlePaddle】公众号
获取更多技术内容~
本文同步分享在 博客“飞桨PaddlePaddle”(CSDN)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
边栏推荐
- console.log alternatives you didn't know about
- When EasyCVR is connected to the GB28181 device, what is the reason that the device is connected normally but the video cannot be played?
- En-us is an invalid culture error solution when Docker links sqlserver
- [ADI low-power 2k code] Based on ADuCM4050, ADXL363, TMP75 acceleration, temperature detection and serial port printing, buzzer playing music (lone warrior)
- 这些云自动化测试工具值得拥有
- A brief analysis of whether programmatic futures trading or manual order is better?
- QueryDet: Cascading Sparse Query Accelerates Small Object Detection at High Resolution
- Graphical LeetCode - 640. Solving Equations (Difficulty: Moderate)
- 获取Qt的安装信息:包括安装目录及各种宏地址
- 【FPGA】名词缩写
猜你喜欢
![[C Language] Getting Started](/img/5e/484e3d426a6f1cc0d792a9ba330695.png)
[C Language] Getting Started
![Binary tree related code questions [more complete] C language](/img/85/a109eed69cd54be3c8290e8dd67b7c.png)
Binary tree related code questions [more complete] C language

When EasyCVR is connected to the GB28181 device, what is the reason that the device is connected normally but the video cannot be played?

Interchangeability Measurements and Techniques - Calculation of Deviations and Tolerances, Drawing of Tolerance Charts, Selection of Fits and Tolerance Classes
高校就业管理系统设计与实现
![[FPGA] Design Ideas - I2C Protocol](/img/ad/7bd52222e81b81a02b72cd3fbc5e16.png)
[FPGA] Design Ideas - I2C Protocol

What is Machine Reinforcement Learning?What is the principle?

Echart地图的省级,以及所有地市级下载与使用

The last update time of the tables queried by the two nodes of the rac standby database is inconsistent

LeetCode刷题第16天之《239滑动窗口最大值》
随机推荐
Read the article, high-performance and predictable data center network
Redis老了吗?Redis与Dragonfly性能比较
Paper Accuracy - 2017 CVPR "High-Resolution Image Inpainting using Multi-Scale Neural Patch Synthesis"
C语言 recv()函数、recvfrom()函数、recvmsg()函数
Is Redis old?Performance comparison between Redis and Dragonfly
MySQL数据库存储引擎以及数据库的创建、修改与删除
Use jackson to parse json data in detail
这些云自动化测试工具值得拥有
Interchangeable Measurement Techniques - Geometric Errors
Multi-serial port RS485 industrial gateway BL110
【FPGA】day20-I2C读写EEPROM
A large horse carries 2 stone of grain, a middle horse carries 1 stone of grain, and two ponies carry one stone of grain. It takes 100 horses to carry 100 stone of grain. How to distribute it?
“顶梁柱”滑坡、新增长极难担重任,阿里“蹲下”是为了跳更高?
Kubernetes集群搭建Zabbix监控平台
华南师范宋宇老师课堂对话论文翻译
EasyCVR接入GB28181设备时,设备接入正常但视频无法播放是什么原因?
LeetCode814算题第15天二叉树系列值《814 二叉树剪枝》
Basic understanding of MongoDB (2)
Which one to choose for mobile map development?
学编程的第十三天