当前位置:网站首页>YOLOv5的Tricks | 【Trick13】YOLOv5的detect.py脚本的解析与简化
YOLOv5的Tricks | 【Trick13】YOLOv5的detect.py脚本的解析与简化
2022-08-10 23:48:00 【Clichong】
如有错误,恳请指出。
在之前介绍了一堆yolov5的训练技巧,train.py脚本也介绍得差不多了。之后还有detect和val两个脚本文件,还想把它们总结完。
在之前测试yolov5训练好的模型时,用detect.py脚本简直不要太方便,觉得这个脚本集成了很多功能,今天就分析源码一探究竟。
关于如何使用yolov5来训练自己的数据集在之前已经写了一篇文章记录过:yolov5的使用 | 训练Pascal voc格式的数据集,所以在这篇文章中就主要分析源码,再稍微提及一下detect的可用参数。
文章目录
1. Detect脚本使用
对于测试的都会存放在runs/detect文件目录下,使用例程只需要指定输入的数据,再指定训练好的权重即可
python detect.py --source 0 # webcam
img.jpg # image 单个图像文件
vid.mp4 # video 单个视频文件
path/ # directory 目录文件
path/*.jpg # glob 正则表达式表示
'https://youtu.be/Zgi9g1ksQHc' # YouTube
'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream
具体的配置文件可以通过输入:python detect.py -h(-help) 来查看。对于yolo跑出来的结构都会放在 ./run/detect 文件夹中,然后以exp依次命名,如下所示:
- 1)测试单张图片
python detect.py --source ./data/image/bus.jpg
- 2)测试图片目录
python detect.py --source ./data/image/
- 3)测试单个视频
python detect.py --source ./data/videos/test_movie
- 4)测试视频目录
python detect.py --source ./data/videos/
- 5)测试摄像头
python detect.py --source 0 # 其中0代表是本地摄像头,还有其他的摄像头
ps:摄像头捕捉的视频同样会保存在 ./run/detect 文件夹中。
详细见参考资料1.
2. Detect脚本解析
在detect.py脚本中,主体是run函数,然后对source的来源进行判断。如果是摄像头设置或者网页视频流则设置相关标志,构建 LoadStreams 数据集。如果是普通的目录文件,或者是视频文件图像文件,则构建 LoadImages 数据集。
构造了数据集,接下来就是迭代获取每一张图像 或者是 获取视频的每一帧进行处理,图像文件直接保存,帧图像着写入一个视频对象中。摄像头捕获的帧图像同样写入一个视频对象中。这里设置的视频文件是逐帧处理的,而摄像头捕获调用了一个额外线程不断捕获帧图像,所以只能是处理当前捕获到的帧,所以摄像头文件看起来会有点卡顿。
最后,代码为图像绘制边界框专门构造了一个绘图类 Annotator 来处理。无论是普通图像还是来着视频的帧图像,都是丢到模型获取预测结果然后进行nms处理获取最后的预测结果,然后对框进行重新缩放映射到原图上,然后画框保存文件,结束。
对于代码的解析我已经注释在相应位置了。
2.1 主体部分
- detect.py主要代码
@torch.no_grad()
def run(weights=ROOT / 'yolov5s.pt', # model.pt path(s)
source=ROOT / 'data/images', # file/dir/URL/glob, 0 for webcam
imgsz=640, # inference size (pixels)
conf_thres=0.25, # confidence threshold
iou_thres=0.45, # NMS IOU threshold
max_det=1000, # maximum detections per image
device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
view_img=False, # show results
save_txt=False, # save results to *.txt
save_conf=False, # save confidences in --save-txt labels
save_crop=False, # save cropped prediction boxes
nosave=False, # do not save images/videos
classes=None, # filter by class: --class 0, or --class 0 2 3
agnostic_nms=False, # class-agnostic NMS
augment=False, # augmented inference
visualize=False, # visualize features
update=False, # update all models
project=ROOT / 'runs/detect', # save results to project/name
name='exp', # save results to project/name
exist_ok=False, # existing project/name ok, do not increment
line_thickness=3, # bounding box thickness (pixels)
hide_labels=False, # hide labels
hide_conf=False, # hide confidences
half=False, # use FP16 half-precision inference
dnn=False, # use OpenCV DNN for ONNX inference
):
source = str(source)
save_img = not nosave and not source.endswith('.txt') # save inference images
webcam = source.isnumeric() or source.endswith('.txt') or source.lower().startswith(
('rtsp://', 'rtmp://', 'http://', 'https://'))
# Directories
save_dir = increment_path(Path(project) / name, exist_ok=exist_ok) # increment run
(save_dir / 'labels' if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir
# Initialize
set_logging()
device = select_device(device)
half &= device.type != 'cpu' # half precision only supported on CUDA
# Load model
w = str(weights[0] if isinstance(weights, list) else weights)
classify, suffix, suffixes = False, Path(w).suffix.lower(), ['.pt', '.onnx', '.tflite', '.pb', '']
check_suffix(w, suffixes) # check weights have acceptable suffix
pt, onnx, tflite, pb, saved_model = (suffix == x for x in suffixes) # backend booleans
stride, names = 64, [f'class{
i}' for i in range(1000)] # assign defaults
if pt:
model = torch.jit.load(w) if 'torchscript' in w else attempt_load(weights, map_location=device)
stride = int(model.stride.max()) # model stride
names = model.module.names if hasattr(model, 'module') else model.names # get class names
if half:
model.half() # to FP16
if classify: # second-stage classifier
modelc = load_classifier(name='resnet50', n=2) # initialize
modelc.load_state_dict(torch.load('resnet50.pt', map_location=device)['model']).to(device).eval()
elif onnx:
if dnn:
# check_requirements(('opencv-python>=4.5.4',))
net = cv2.dnn.readNetFromONNX(w)
else:
check_requirements(('onnx', 'onnxruntime'))
import onnxruntime
session = onnxruntime.InferenceSession(w, None)
else: # TensorFlow models
check_requirements(('tensorflow>=2.4.1',))
import tensorflow as tf
if pb: # https://www.tensorflow.org/guide/migrate#a_graphpb_or_graphpbtxt
def wrap_frozen_graph(gd, inputs, outputs):
x = tf.compat.v1.wrap_function(lambda: tf.compat.v1.import_graph_def(gd, name=""), []) # wrapped import
return x.prune(tf.nest.map_structure(x.graph.as_graph_element, inputs),
tf.nest.map_structure(x.graph.as_graph_element, outputs))
graph_def = tf.Graph().as_graph_def()
graph_def.ParseFromString(open(w, 'rb').read())
frozen_func = wrap_frozen_graph(gd=graph_def, inputs="x:0", outputs="Identity:0")
elif saved_model:
model = tf.keras.models.load_model(w)
elif tflite:
interpreter = tf.lite.Interpreter(model_path=w) # load TFLite model
interpreter.allocate_tensors() # allocate
input_details = interpreter.get_input_details() # inputs
output_details = interpreter.get_output_details() # outputs
int8 = input_details[0]['dtype'] == np.uint8 # is TFLite quantized uint8 model
imgsz = check_img_size(imgsz, s=stride) # check image size
# Dataloader
if webcam:
view_img = check_imshow()
cudnn.benchmark = True # set True to speed up constant image size inference
dataset = LoadStreams(source, img_size=imgsz, stride=stride, auto=pt) # 摄像头或者网页视频的数据集构建
bs = len(dataset) # batch_size
else:
dataset = LoadImages(source, img_size=imgsz, stride=stride, auto=pt) # 图像文件与视频文件的数据集构建
bs = 1 # batch_size 单进程
vid_path, vid_writer = [None] * bs, [None] * bs
# Run inference
if pt and device.type != 'cpu':
model(torch.zeros(1, 3, *imgsz).to(device).type_as(next(model.parameters()))) # run once
dt, seen = [0.0, 0.0, 0.0], 0
# 首先执行__iter__函数构建一个迭代器,最后每执行迭代一次就执行一次__next__函数
# 返回是的文件路径,缩放图,原图,视频源属性(当读取图片时为None, 读取视频时为视频源)
for path, img, im0s, vid_cap in dataset:
t1 = time_sync()
if onnx:
img = img.astype('float32')
else:
# 格式转化+半精度设置
img = torch.from_numpy(img).to(device)
img = img.half() if half else img.float() # uint8 to fp16/32
img = img / 255.0 # 0 - 255 to 0.0 - 1.0
# [h w c] -> [1 h w c]
if len(img.shape) == 3:
img = img[None] # expand for batch dim
t2 = time_sync()
dt[0] += t2 - t1
# Inference
if pt: # 主要是下面两行,其他的都无关
visualize = increment_path(save_dir / Path(path).stem, mkdir=True) if visualize else False
# pred shape=[1, num_boxes, xywh+obj_conf+classes] = [1, 18900, 25]
pred = model(img, augment=augment, visualize=visualize)[0]
elif onnx:
if dnn:
net.setInput(img)
pred = torch.tensor(net.forward())
else:
pred = torch.tensor(session.run([session.get_outputs()[0].name], {
session.get_inputs()[0].name: img}))
else: # tensorflow model (tflite, pb, saved_model)
imn = img.permute(0, 2, 3, 1).cpu().numpy() # image in numpy
if pb:
pred = frozen_func(x=tf.constant(imn)).numpy()
elif saved_model:
pred = model(imn, training=False).numpy()
elif tflite:
if int8:
scale, zero_point = input_details[0]['quantization']
imn = (imn / scale + zero_point).astype(np.uint8) # de-scale
interpreter.set_tensor(input_details[0]['index'], imn)
interpreter.invoke()
pred = interpreter.get_tensor(output_details[0]['index'])
if int8:
scale, zero_point = output_details[0]['quantization']
pred = (pred.astype(np.float32) - zero_point) * scale # re-scale
pred[..., 0] *= imgsz[1] # x
pred[..., 1] *= imgsz[0] # y
pred[..., 2] *= imgsz[1] # w
pred[..., 3] *= imgsz[0] # h
pred = torch.tensor(pred)
t3 = time_sync()
dt[1] += t3 - t2
# NMS 非极大值抑制处理
# pred是一个list,存储了每张图像的最后预测结果,由于这里的图像和视频都是一张,所以list里面只会有一个内容(det)
pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)
dt[2] += time_sync() - t3
# Second-stage classifier (optional)
if classify:
pred = apply_classifier(pred, modelc, img, im0s)
# Process predictions
# 对每张图像的预测结果的每个预测内容依次处理
for i, det in enumerate(pred): # per image
seen += 1
if webcam: # batch_size >= 1
p, s, im0, frame = path[i], f'{
i}: ', im0s[i].copy(), dataset.count
else:
p, s, im0, frame = path, '', im0s.copy(), getattr(dataset, 'frame', 0)
# 当前图片路径 如 F:\yolo_v5\yolov5-U\data\images\bus.jpg
p = Path(p) # to Path
# 图片/视频的保存路径save_path 如 runs\\detect\\exp8\\bus.jpg
save_path = str(save_dir / p.name) # img.jpg
# txt文件(保存预测框坐标)保存路径 如 runs\\detect\\exp8\\labels\\bus
txt_path = str(save_dir / 'labels' / p.stem) + ('' if dataset.mode == 'image' else f'_{
frame}') # img.txt
s += '%gx%g ' % img.shape[2:] # print string: wxh
# gn = [w, h, w, h] 用于后面的归一化
gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwh
imc = im0.copy() if save_crop else im0 # for save_crop
# 创建了一个类用来对图像画框与添加文本信息
annotator = Annotator(im0, line_width=line_thickness, example=str(names))
if len(det):
# Rescale boxes from img_size to im0 size
# 将预测信息(相对img_size 640)映射回原图 img0 size, det:xyxy + conf + cls
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], im0.shape).round()
# Print results
# 输出信息s + 检测到的各个类别的目标个数 (每张图像都会有一个这样的信息,对视频来说是每帧)
for c in det[:, -1].unique():
n = (det[:, -1] == c).sum() # detections per class
s += f"{
n} {
names[int(c)]}{
's' * (n > 1)}, " # add to string
# Write results
# 对每个预测对象依次绘制在原图中 + 保存在txt文件中
for *xyxy, conf, cls in reversed(det):
# 将每个图片的预测信息分别存入save_dir/labels下的xxx.txt中 每行: class_id+score+xywh
if save_txt: # Write to file
# 将xyxy(左上角 + 右下角)格式转换为xywh(中心的 + 宽高)格式 并除以gn(whwh)做归一化 转为list再保存
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # label format
with open(txt_path + '.txt', 'a') as f:
f.write(('%g ' * len(line)).rstrip() % line + '\n')
# 在原图上绘制边界框
if save_img or save_crop or view_img: # Add bbox to image
c = int(cls) # integer class
# 在name这个列表字典中获取label名称
label = None if hide_labels else (names[c] if hide_conf else f'{
names[c]} {
conf:.2f}')
# 根据缩放后的预测边界框信息xyxy在原图上画框
annotator.box_label(xyxy, label, color=colors(c, True))
if save_crop:
# 如果需要就将预测到的目标剪切出来 保存成图片 保存在save_dir/crops下
save_one_box(xyxy, imc, file=save_dir / 'crops' / names[c] / f'{
p.stem}.jpg', BGR=True)
# Print time (inference-only)
print(f'{
s}Done. ({
t3 - t2:.3f}s)')
# Stream results
# 获得画框后的原图
im0 = annotator.result()
# 是否需要显示我们预测后的结果 img0(此时已将pred结果可视化到了img0中)
if view_img:
cv2.imshow(str(p), im0)
cv2.waitKey(1) # 1 millisecond
# Save results (image with detections)
if save_img:
# 如果当前处理的文件是图像,直接写入对应的目录下
if dataset.mode == 'image':
cv2.imwrite(save_path, im0)
# 如果当前处理的文件是视频,判断是否在处理同一个视频
# 这里的i对于处理视频任务或者是图像任务的时候是没用的,因为此时pred只有一张图像,所以i一直为0
else: # 'video' or 'stream'
# 如果不是同一个视频,则重新构建一个视频写入对象
if vid_path[i] != save_path: # new video
# 更新路径信息,使得之后可以跳过判断
vid_path[i] = save_path
# 释放上一次视频处理的缓存信息
if isinstance(vid_writer[i], cv2.VideoWriter):
vid_writer[i].release() # release previous video writer
# 获取当前视频的一些信息
if vid_cap: # video
# 获取当前视频的帧率与宽高,设置同样的格式,以确保相同帧率与宽高的视频输出
fps = vid_cap.get(cv2.CAP_PROP_FPS)
w = int(vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH))
h = int(vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
# 摄像头的视频流设置帧数为30
else: # stream
fps, w, h = 30, im0.shape[1], im0.shape[0]
save_path += '.mp4'
# 创建写入视频对象,设置格式
vid_writer[i] = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*'mp4v'), fps, (w, h))
# 如果是同一个视频,跳过上面的判断直接逐帧写入视频文件中
# 如果不是同一个视频,则创建新的视频写入对象,同样逐帧写入视频文件中
vid_writer[i].write(im0)
# Print results
# 打印最后的相关信息
t = tuple(x / seen * 1E3 for x in dt) # speeds per image
print(f'Speed: %.1fms pre-process, %.1fms inference, %.1fms NMS per image at shape {
(1, 3, *imgsz)}' % t)
if save_txt or save_img:
s = f"\n{
len(list(save_dir.glob('labels/*.txt')))} labels saved to {
save_dir / 'labels'}" if save_txt else ''
print(f"Results saved to {
colorstr('bold', save_dir)}{
s}")
if update:
strip_optimizer(weights) # update model (to fix SourceChangeWarning)
2.2 数据集构建
这里代码中还实现了一个 LoadWebcam 的类,但是没有用上,就不做过多解析了。
- LoadImages类代码
class LoadImages:
# YOLOv5 image/video dataloader, i.e. `python detect.py --source image.jpg/vid.mp4`
def __init__(self, path, img_size=640, stride=32, auto=True):
# 这里的图像和文件只能是当前目录下,如果是在目录的目录下是不会处理的
p = str(Path(path).resolve()) # os-agnostic absolute path
if '*' in p: # 如果是采用正则表达式题,则可以使用glob获取相关的文件路径
files = sorted(glob.glob(p, recursive=True)) # glob
elif os.path.isdir(p): # 如果是一个目录路径,提取目录文件中所有含有'*'的文件
files = sorted(glob.glob(os.path.join(p, '*.*'))) # dir
elif os.path.isfile(p): # 如果是一个文件则直接获取
files = [p] # files
else:
raise Exception(f'ERROR: {
p} does not exist')
# 分别存储图像文件的全部路径和视频文件的全部路径
images = [x for x in files if x.split('.')[-1].lower() in IMG_FORMATS]
videos = [x for x in files if x.split('.')[-1].lower() in VID_FORMATS]
ni, nv = len(images), len(videos)
self.img_size = img_size
self.stride = stride
# 按顺序,先处理完全部图像文件再处理视频文件
self.files = images + videos
self.nf = ni + nv # number of files
# 是否是视频文件的标志
self.video_flag = [False] * ni + [True] * nv
self.mode = 'image'
self.auto = auto
if any(videos):
# 如果含有视频文件,则先对第一个视频文件初始化opencv的视频模块
self.new_video(videos[0]) # new video
else:
self.cap = None
assert self.nf > 0, f'No images or videos found in {
p}. ' \
f'Supported formats are:\nimages: {
IMG_FORMATS}\nvideos: {
VID_FORMATS}'
# dataset开始迭代时执行一次开始时
def __iter__(self):
self.count = 0
return self
# dataset每迭代一次执行一次
def __next__(self):
# 当全部图像或者视频处理完时退出迭代训练
if self.count == self.nf:
raise StopIteration
# 当前处理的文件路径
path = self.files[self.count]
# 如果当前处理的是视频,利用opencv逐帧读取
if self.video_flag[self.count]:
# Read video
self.mode = 'video'
# 依次读取每一帧(处理完一帧写入一个视频文件后继续处理下一帧)
# ret_val为一个bool变量,直到视频读取完毕之前都为True
ret_val, img0 = self.cap.read()
# 当前视频帧全部读取完时
if not ret_val:
# 当前视频处理完成,获取下一个待处理视频文件的索引
self.count += 1
self.cap.release()
# 如果处理完最后一个视频就处理完所有的待处理文件就退出迭代
if self.count == self.nf: # last video
raise StopIteration
# 继续下一个文件处理
else:
path = self.files[self.count] # 获取下一个视频文件的路径
self.new_video(path) # 重新初始化opencv对象
ret_val, img0 = self.cap.read() # 继续开始逐帧读取
# 准备下一帧索引,直到视频文件全部读取完,返回的ret_val即为False
self.frame += 1
# 打印视频的当前任务位置,当前处理帧位置,当前的处理视频路径,后续还有其他补充信息
# eg: video 1/2 (13/5642) E:\videos\test_movie.mp4: 384x640 1 bird, 1 kite, Done. (0.225s)
print(f'video {
self.count + 1}/{
self.nf} ({
self.frame}/{
self.frames}) {
path}: ', end='')
# 如果当前处理的是图像,直接利用opencv读取
else:
# 一个图像文件就是一个任务,读取完直接count+1
# Read image
self.count += 1
img0 = cv2.imread(path) # BGR
assert img0 is not None, 'Image Not Found ' + path
# 打印图像的当前任务位置,当前的处理图像路径,后续还有其他补充信息
print(f'image {
self.count}/{
self.nf} {
path}: ', end='')
# Padded resize 重新缩放到下采样尺寸
img = letterbox(img0, self.img_size, stride=self.stride, auto=self.auto)[0]
# Convert
img = img.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
img = np.ascontiguousarray(img)
return path, img, img0, self.cap
# 一开始与一个视频任务完成时需要执行,确保迭代对象可以一直持续获取,只是需要区分好视频任务
def new_video(self, path):
self.frame = 0 # 帧数记录
self.cap = cv2.VideoCapture(path) # 获取视频对象
self.frames = int(self.cap.get(cv2.CAP_PROP_FRAME_COUNT)) # 得到视频中的总帧数
def __len__(self):
return self.nf # number of files
解析:
在处理普通目录下的图像和视频文件时,这里会先处理完所有的图像文件,然后再处理视频文件。然后当一个视频文件处理完时,需要立刻的进行下一个视频文件的处理,以让dataset一直迭代。但最后dataset迭代完成时,使用全部的视频文件已经处理结束了。
- LoadStreams类代码
class LoadStreams:
# YOLOv5 streamloader, i.e. `python detect.py --source 'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP streams`
def __init__(self, sources='streams.txt', img_size=640, stride=32, auto=True):
self.mode = 'stream'
self.img_size = img_size
self.stride = stride
# 如果sources为一个保存了多个视频流的文件 获取每一个视频流,保存为一个列表
if os.path.isfile(sources):
with open(sources, 'r') as f:
sources = [x.strip() for x in f.read().strip().splitlines() if len(x.strip())]
else:
# 反之,只有一个视频流文件就直接保存
sources = [sources]
n = len(sources)
# 初始化图片 fps 总帧数 线程数
self.imgs, self.fps, self.frames, self.threads = [None] * n, [0] * n, [0] * n, [None] * n
self.sources = [clean_str(x) for x in sources] # clean source names for later
self.auto = auto
# 这里将多个视频流分别独立,各自构建一个线程进行动态读取,i表示的是第几个视频流的数据
for i, s in enumerate(sources): # index, source
# Start thread to read frames from video stream
# 打印当前视频index/总视频数/视频流地址
print(f'{
i + 1}/{
n}: {
s}... ', end='')
if 'youtube.com/' in s or 'youtu.be/' in s: # if source is YouTube video
check_requirements(('pafy', 'youtube_dl'))
import pafy
s = pafy.new(s).getbest(preftype="mp4").url # YouTube URL
s = eval(s) if s.isnumeric() else s # i.e. s = '0' local webcam
# s='0'打开本地摄像头,否则打开视频流地址(分别独立的构建一个视频对象)
cap = cv2.VideoCapture(s)
# 对于b站链接,油管链接,是打不开的,在这里会进行报错
assert cap.isOpened(), f'Failed to open {
s}'
# 获取视频的宽和长
w = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
h = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
# 获取每个视频流的帧率(摄像头的帧率为30)
self.fps[i] = max(cap.get(cv2.CAP_PROP_FPS) % 100, 0) or 30.0 # 30 FPS fallback
# 获取每个视频流的帧数(摄像头的帧数为0 所以设置为'inf')
self.frames[i] = max(int(cap.get(cv2.CAP_PROP_FRAME_COUNT)), 0) or float('inf') # infinite stream fallback
# 对每个视频流读取当前画面
_, self.imgs[i] = cap.read() # guarantee first frame
# 创建多线程读取视频流,daemon表示主线程结束时子线程也结束
# 其中args=([i, cap, s])是传入给update函数的参数
self.threads[i] = Thread(target=self.update, args=([i, cap, s]), daemon=True)
print(f" success ({
self.frames[i]} frames {
w}x{
h} at {
self.fps[i]:.2f} FPS)")
self.threads[i].start()
print('') # newline
# check for common shapes
# 依次对每个视频流数据进行缩放处理,然后拼接在一起
s = np.stack([letterbox(x, self.img_size, stride=self.stride, auto=self.auto)[0].shape for x in self.imgs])
self.rect = np.unique(s, axis=0).shape[0] == 1 # rect inference if all shapes equal
if not self.rect:
print('WARNING: Different stream shapes detected. For optimal performance supply similarly-shaped streams.')
# 这个函数是在后台进行的
def update(self, i, cap, stream):
# Read stream `i` frames in daemon thread
n, f, read = 0, self.frames[i], 1 # frame number, frame array, inference every 'read' frame
# n是当前处理的帧数,f是总帧数,当当前帧数大于总帧数时处理结束
# 对于摄像头的视频流来说总帧数无穷大'inf',所以会一直循环执行
while cap.isOpened() and n < f:
n += 1
# _, self.imgs[index] = cap.read()
cap.grab()
# 处理每一帧数据,read表示每多少帧处理一次
if n % read == 0:
# 读取当前帧
success, im = cap.retrieve()
# 在后台获取图像,等待迭代获取最新图像
if success:
self.imgs[i] = im
else:
print('WARNING: Video stream unresponsive, please check your IP camera connection.')
self.imgs[i] *= 0
cap.open(stream) # re-open stream if signal was lost
# 这里个人觉得是等待一帧处理的时间来进行推理,让推理速度追上读取速度
time.sleep(1 / self.fps[i]) # wait time
def __iter__(self):
self.count = -1
return self
def __next__(self):
self.count += 1
if not all(x.is_alive() for x in self.threads) or cv2.waitKey(1) == ord('q'): # q to quit
cv2.destroyAllWindows()
raise StopIteration
# Letterbox
# 对所有的视频流图像进行缩放处理然后构建成一个列表
img0 = self.imgs.copy()
img = [letterbox(x, self.img_size, stride=self.stride, auto=self.rect and self.auto)[0] for x in img0]
# Stack
# 将缩放后的图像列表拼接在一起,直接丢进模型进行预测处理
# 如果source=0调用本地摄像头,那么每次这里的img只有一张图像,代表只有一个视频流的输入数据
img = np.stack(img, 0)
# Convert
img = img[..., ::-1].transpose((0, 3, 1, 2)) # BGR to RGB, BHWC to BCHW
img = np.ascontiguousarray(img)
return self.sources, img, img0, None
def __len__(self):
# len(dataset) 表示返回当前同时处理多少个视频流
return len(self.sources) # 1E12 frames = 32 streams at 30 FPS for 30 years
解析:
这里主要的实现思路是为每个视频流都开了一个线程来不断的捕获帧图像,然后主线程对帧图像进行一个常规的推理处理。但是需要注意,这里获取的帧图像和推理速度之间会有一个时间差,就是说获取真图像的速度可能太快了,前一帧的图像可能还没处理完就已经捕获了下一帧了,这样就会漏帧检测,所以需要适当的添加一个等待的时间。
# 这里个人觉得是等待一帧处理的时间来进行推理,让推理速度追上读取速度
time.sleep(1 / self.fps[i]) # wait time
这个等待时间与推理速度之间有什么关系,我还是不太了解。
- LoadWebcam类代码
class LoadWebcam: # for inference
# YOLOv5 local webcam dataloader, i.e. `python detect.py --source 0`
def __init__(self, pipe='0', img_size=640, stride=32):
self.img_size = img_size
self.stride = stride
self.pipe = eval(pipe) if pipe.isnumeric() else pipe
self.cap = cv2.VideoCapture(self.pipe) # video capture object
self.cap.set(cv2.CAP_PROP_BUFFERSIZE, 3) # set buffer size
def __iter__(self):
self.count = -1
return self
def __next__(self):
self.count += 1
if cv2.waitKey(1) == ord('q'): # q to quit
self.cap.release()
cv2.destroyAllWindows()
raise StopIteration
# Read frame
ret_val, img0 = self.cap.read()
img0 = cv2.flip(img0, 1) # flip left-right
# Print
assert ret_val, f'Camera Error {
self.pipe}'
img_path = 'webcam.jpg'
print(f'webcam {
self.count}: ', end='')
# Padded resize
img = letterbox(img0, self.img_size, stride=self.stride)[0]
# Convert
img = img.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
img = np.ascontiguousarray(img)
return img_path, img, img0, None
def __len__(self):
return 0
2.3 绘图部分
这里主要是使用了 Annotator 类来进行绘制边界框与label信息。
- Annotator类代码
class Annotator:
if RANK in (-1, 0):
check_font() # download TTF if necessary
# YOLOv5 Annotator for train/val mosaics and jpgs and detect/hub inference annotations
def __init__(self, im, line_width=None, font_size=None, font='Arial.ttf', pil=False, example='abc'):
assert im.data.contiguous, 'Image not contiguous. Apply np.ascontiguousarray(im) to Annotator() input images.'
self.pil = pil or not is_ascii(example) or is_chinese(example)
# 默认使用opencv
if self.pil: # use PIL
self.im = im if isinstance(im, Image.Image) else Image.fromarray(im)
self.draw = ImageDraw.Draw(self.im)
self.font = check_font(font='Arial.Unicode.ttf' if is_chinese(example) else font,
size=font_size or max(round(sum(self.im.size) / 2 * 0.035), 12))
else: # use cv2
self.im = im
# 设置框宽度
self.lw = line_width or max(round(sum(im.shape) / 2 * 0.003), 2) # line width
def box_label(self, box, label='', color=(128, 128, 128), txt_color=(255, 255, 255)):
# Add one xyxy box to image with label
if self.pil or not is_ascii(label):
self.draw.rectangle(box, width=self.lw, outline=color) # box
if label:
w, h = self.font.getsize(label) # text width, height
outside = box[1] - h >= 0 # label fits outside box
self.draw.rectangle([box[0],
box[1] - h if outside else box[1],
box[0] + w + 1,
box[1] + 1 if outside else box[1] + h + 1], fill=color)
# self.draw.text((box[0], box[1]), label, fill=txt_color, font=self.font, anchor='ls') # for PIL>8.0
self.draw.text((box[0], box[1] - h if outside else box[1]), label, fill=txt_color, font=self.font)
else: # cv2
# 获取边界框的两个点
p1, p2 = (int(box[0]), int(box[1])), (int(box[2]), int(box[3]))
# 根据两个点坐标绘制边界框
cv2.rectangle(self.im, p1, p2, color, thickness=self.lw, lineType=cv2.LINE_AA)
# 在边界框左上角绘制label信息
if label:
tf = max(self.lw - 1, 1) # font thickness
# 获取label的宽度高度
w, h = cv2.getTextSize(label, 0, fontScale=self.lw / 3, thickness=tf)[0] # text width, height
outside = p1[1] - h - 3 >= 0 # label fits outside box
p2 = p1[0] + w, p1[1] - h - 3 if outside else p1[1] + h + 3
# 绘制label的背景框(填充色)
cv2.rectangle(self.im, p1, p2, color, -1, cv2.LINE_AA) # filled
# 绘制label的字符串
cv2.putText(self.im, label, (p1[0], p1[1] - 2 if outside else p1[1] + h + 2), 0, self.lw / 3, txt_color,
thickness=tf, lineType=cv2.LINE_AA)
def rectangle(self, xy, fill=None, outline=None, width=1):
# Add rectangle to image (PIL-only)
self.draw.rectangle(xy, fill, outline, width)
def text(self, xy, text, txt_color=(255, 255, 255)):
# Add text to image (PIL-only)
w, h = self.font.getsize(text) # text width, height
self.draw.text((xy[0], xy[1] - h + 1), text, fill=txt_color, font=self.font)
def result(self):
# Return annotated image as array
return np.asarray(self.im)
主要的调用过程很简单:
# 初始化,传入原图
annotator = Annotator(im0, line_width=line_thickness, example=str(names))
# 在原图上依次绘制每个label信息与对应的预测边界框
for *xyxy, conf, cls in reversed(det):
...
annotator.box_label(xyxy, label, color=colors(c, True))
...
# 返回画框后的图像
im0 = annotator.result()
3. Detect脚本简化
yolov5的源码对detect脚本写得非常的详细,集成了很多功能,但对我来说需求可能没有那么大,然后为了便于自己学习与查看,这里我对detect脚本进行了简化,分别为单个图像,单个视频和摄像头信息编写了一个检测脚本。
3.1 单图像推理
- 自己写的参考代码
# 功能:单图像推理
def run_image(image_path, save_path, img_size=640, stride=32, augment=False, visualize=False):
weights = r'weights/yolov5s.pt'
device = 'cpu'
save_path += os.path.basename(image_path)
# 导入模型
model = attempt_load(weights, map_location=device)
img_size = check_img_size(img_size, s=stride)
names = model.names
# Padded resize
img0 = cv2.imread(image_path)
img = letterbox(img0, img_size, stride=stride, auto=True)[0]
# Convert
img = img.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
img = np.ascontiguousarray(img)
img = torch.from_numpy(img).to(device)
img = img.float() / 255.0 # 0 - 255 to 0.0 - 1.0
img = img[None] # [h w c] -> [1 h w c]
# inference
pred = model(img, augment=augment, visualize=visualize)[0]
pred = non_max_suppression(pred, conf_thres=0.25, iou_thres=0.45, max_det=1000)
# plot label
det = pred[0]
annotator = Annotator(img0.copy(), line_width=3, example=str(names))
if len(det):
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], img0.shape).round()
for *xyxy, conf, cls in reversed(det):
c = int(cls) # integer class
label = f'{
names[c]} {
conf:.2f}'
annotator.box_label(xyxy, label, color=colors(c, True))
# write video
im0 = annotator.result()
cv2.imwrite(save_path, im0)
print(f'Inference {
image_path} finish, save to {
save_path}')
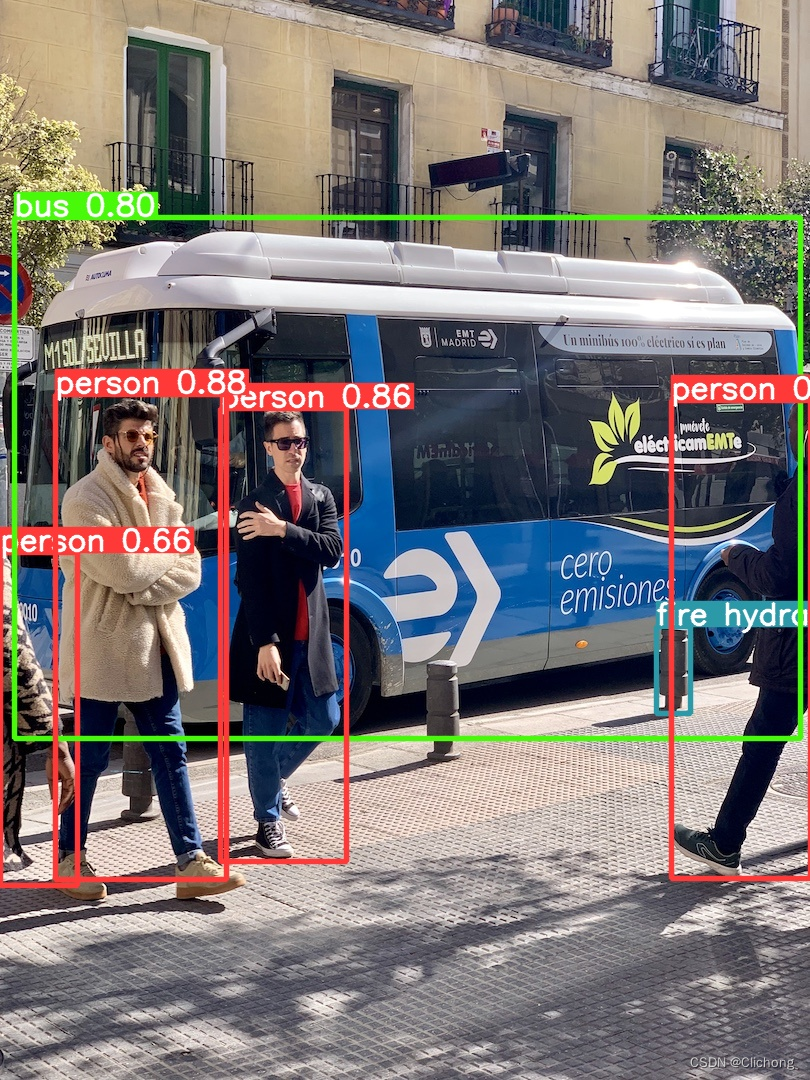
推理后的图像:
3.2 单视频推理
- 自己写的参考代码
# 功能:单视频推理
def run_video(video_path, save_path, img_size=640, stride=32, augment=False, visualize=False):
weights = r'weights/yolov5s.pt'
device = 'cpu'
# 导入模型
model = attempt_load(weights, map_location=device)
img_size = check_img_size(img_size, s=stride)
names = model.names
# 读取视频对象
cap = cv2.VideoCapture(video_path)
frame = 0 # 开始处理的帧数
frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT)) # 待处理的总帧数
# 获取当前视频的帧率与宽高,设置同样的格式,以确保相同帧率与宽高的视频输出
fps = cap.get(cv2.CAP_PROP_FPS)
w = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
h = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
save_path += os.path.basename(video_path)
vid_writer = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*'mp4v'), fps, (w, h))
while frame <= frames:
# 读取帧图像
ret_val, img0 = cap.read()
if not ret_val:
break
frame += 1
print(f'video {
frame}/{
frames} {
save_path}')
# Padded resize
img = letterbox(img0, img_size, stride=stride, auto=True)[0]
# Convert
img = img.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
img = np.ascontiguousarray(img)
img = torch.from_numpy(img).to(device)
img = img.float() / 255.0 # 0 - 255 to 0.0 - 1.0
img = img[None] # [h w c] -> [1 h w c]
# inference
pred = model(img, augment=augment, visualize=visualize)[0]
pred = non_max_suppression(pred, conf_thres=0.25, iou_thres=0.45, max_det=1000)
# plot label
det = pred[0]
annotator = Annotator(img0.copy(), line_width=3, example=str(names))
if len(det):
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], img0.shape).round()
for *xyxy, conf, cls in reversed(det):
c = int(cls) # integer class
label = f'{
names[c]} {
conf:.2f}'
annotator.box_label(xyxy, label, color=colors(c, True))
# write video
im0 = annotator.result()
vid_writer.write(im0)
vid_writer.release()
cap.release()
print(f'{
video_path} finish, save to {
save_path}')
最后的输出结果:
在对应的目录文件下会生成检测视频,由于是逐帧检测的,所以视频不会压缩,长度也不会改变。

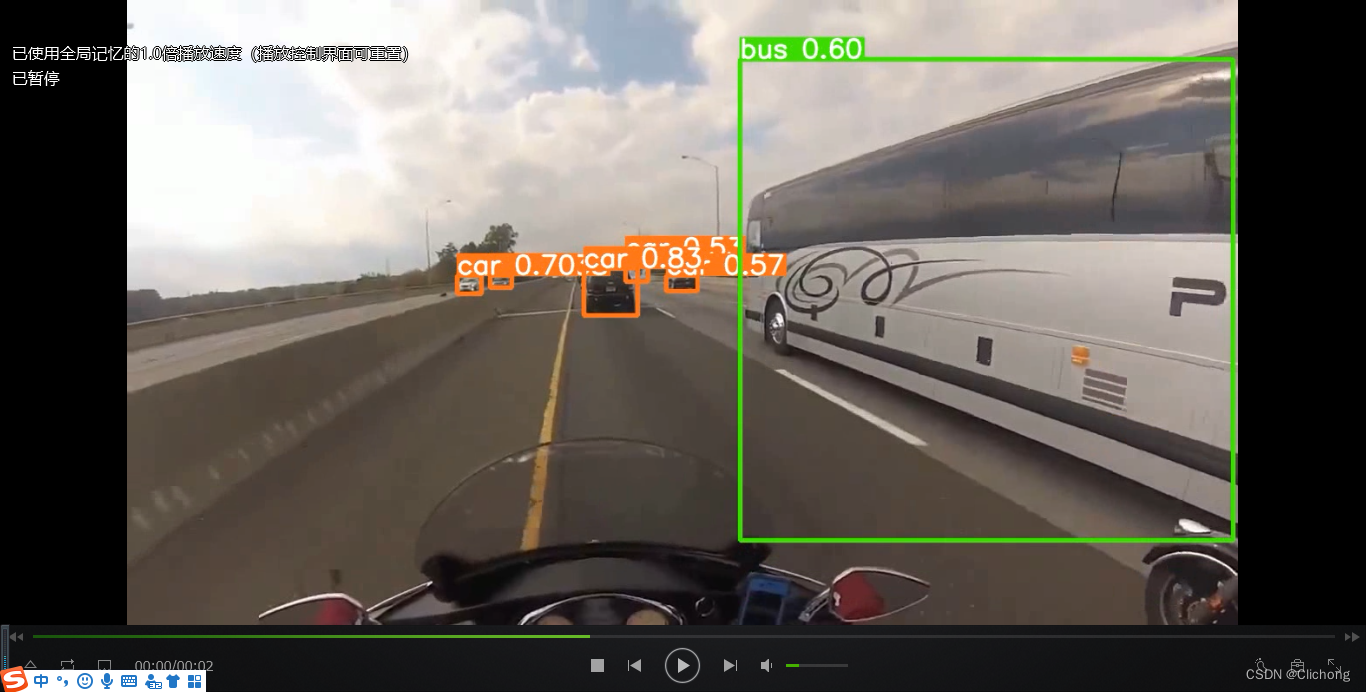
推理视频的部分截图:
3.3 摄像头推理
- 自己写的参考代码
def run_webcam(save_path, img_size=640, stride=32, augment=False, visualize=False):
weights = r'weights/yolov5s.pt'
device = 'cpu'
# 导入模型
model = attempt_load(weights, map_location=device)
img_size = check_img_size(img_size, s=stride)
names = model.names
# 读取视频对象: 0 表示打开本地摄像头
cap = cv2.VideoCapture(0)
frame = 0 # 开始处理的帧数
# 获取当前视频的帧率与宽高,设置同样的格式,以确保相同帧率与宽高的视频输出
ret_val, img0 = cap.read()
fps, w, h = 30, img0.shape[1], img0.shape[0]
vid_writer = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*'mp4v'), fps, (w, h))
# 按q退出循环
while True:
ret_val, img0 = cap.read()
if cv2.waitKey(1) == ord('q'):
cap.release()
cv2.destroyAllWindows()
break
if not ret_val:
break
frame += 1
print(f'video {
frame} {
save_path}')
# Padded resize
img = letterbox(img0, img_size, stride=stride, auto=True)[0]
# Convert
img = img.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
img = np.ascontiguousarray(img)
img = torch.from_numpy(img).to(device)
img = img.float() / 255.0 # 0 - 255 to 0.0 - 1.0
img = img[None] # [h w c] -> [1 h w c]
# inference
pred = model(img, augment=augment, visualize=visualize)[0]
pred = non_max_suppression(pred, conf_thres=0.25, iou_thres=0.45, max_det=1000)
# plot label
det = pred[0]
annotator = Annotator(img0.copy(), line_width=3, example=str(names))
if len(det):
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], img0.shape).round()
for *xyxy, conf, cls in reversed(det):
c = int(cls) # integer class
label = f'{
names[c]} {
conf:.2f}'
annotator.box_label(xyxy, label, color=colors(c, True))
# write video
im0 = annotator.result()
cv2.imshow('webcam:0', im0)
cv2.waitKey(1)
vid_writer.write(im0)
# 按q退出循环
vid_writer.release()
cap.release()
print(f'Webcam finish, save to {
save_path}')
按q退出摄像头的推理,然后推理完一帧再捕获下一帧进行推理,所以在最后的保存视频中推理的速度看起来会有点加速的感觉。正常按q退出视频可以正常打开视频,但是如果直接中断程序,视频是无法打开的。
这里就不展示摄像头推理了,在推理的过程中会实时显示,同时写入文件夹中。正常退出显示:

3.4 测试代码
- 参考测试代码
class Test:
def test_image(self):
test_path = r"data/images/bus.jpg"
save_path = r"runs/detect/"
run_image(test_path, save_path)
def test_video(self):
test_path = r"data/videos/demo.mp4"
save_path = r"runs/detect/"
run_video(test_path, save_path)
def test_webcam(self):
save_path = r"runs/detect/webcam.mp4"
run_webcam(save_path)
if __name__ == '__main__':
test = Test()
test.test_webcam()
参考资料:
边栏推荐
猜你喜欢


![[C language] binary search (half search)](/img/24/4e7b54963ac9df4a3244232c32c435.png)



随机推荐
9. Rest style request processing
Mysql.慢Sql
回收站的文件删了怎么恢复,回收站文件恢复的两种方法
11. 自定义转换器
IEEE的论文哪里可以下载?
推进牛仔服装的高质量发展
定时器,同步API和异步API,文件系统模块,文件流
App的回归测试,有什么高效的测试方法?
ASIO4ALL是什么
镜头之滤光片---关于日夜两用双通滤光片
逮到一个阿里 10 年老 测试开发,聊过之后收益良多...
Promise in detail
图像识别和语义分割的区别
Microsoft: Into Focus with Scott Guthrie Scott Hanselman Rajesh Jha and Kevin Scott | KEY11
Server Tips
14. Thymeleaf
[C Language Chapter] Detailed explanation of bitwise operators (“<<”, “>>”, “&”, “|”, “^”, “~”)
Geogebra 教程之 01 什么是Geogebra,真的可以提高我们数学水平么?
【C语言】猜数字游戏的实现
16. File upload