当前位置:网站首页>学习Apache ShardingSphere解析器源码(一)
学习Apache ShardingSphere解析器源码(一)
2022-08-10 23:44:00 【InfoQ】
1. 写作由来
2. 以Oracle的DropTable功能为例分析
dropTable
: DROP TABLE tableName (CASCADE CONSTRAINTS)? (PURGE)?
;
tableName
: (owner DOT_)? name
;
owner
: identifier
;
name
: identifier
;
identifier
: IDENTIFIER_ | unreservedWord
;
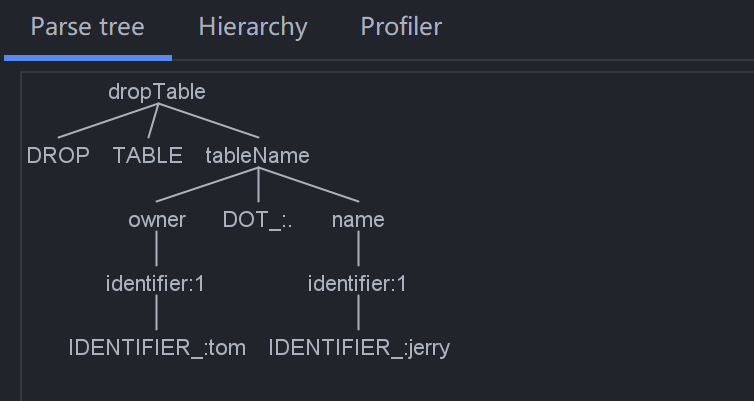
-- 删除用户tom下的jerry表
drop table tom.jerry;
public interface ASTNode {}
public class IdentifierValue implements ASTNode {
private final String name;
public IdentifierValue(String name) {
this.name = name;
}
public String getName() {
return name;
}
}
public class TableName implements ASTNode {
private IdentifierValue owner;
private final IdentifierValue name;
public TableName(IdentifierValue name) {
this.name = name;
}
public void setOwner(IdentifierValue owner) {
this.owner = owner;
}
public Optional<IdentifierValue> getOwner() {
return Optional.ofNullable(owner);
}
public IdentifierValue getName() {
return name;
}
}
public class DropTableStatement implements ASTNode {
private final TableName tableName;
public DropTableStatement(TableName tableName) {
this.tableName = tableName;
}
public TableName getTableName() {
return tableName;
}
@Override
public String toString() {
return "DropTableStatement{" +
"tableName=" + tableName +
'}';
}
}
public class OracleDDLStatementVisitor extends OracleStatementBaseVisitor<ASTNode> {
@Override
public ASTNode visitDropTable(OracleStatementParser.DropTableContext ctx) {
return new DropTableStatement((TableName) visit(ctx.tableName()));
}
@Override
public ASTNode visitTableName(OracleStatementParser.TableNameContext ctx) {
TableName result = new TableName((IdentifierValue) visit(ctx.name()));
if (Objects.nonNull(ctx.owner())) {
result.setOwner((IdentifierValue) visit(ctx.owner()));
}
return result;
}
@Override
public ASTNode visitIdentifier(OracleStatementParser.IdentifierContext ctx) {
return new IdentifierValue(ctx.IDENTIFIER_().getText());
}
}
边栏推荐
- App的回归测试,有什么高效的测试方法?
- 服务器小常识
- Google Chrome73~81版本浏览器的跨域问题解决方案
- 一条SQL查询语句是如何执行的?
- There is no recycle bin for deleted files on the computer desktop, what should I do if the deleted files on the desktop cannot be found in the recycle bin?
- Starting a new journey - Mr. Maple Leaf's first blog
- CW614N铜棒CuZn39Pb3对应牌号
- 7. yaml
- 好用的翻译插件-一键自动翻译插件软件
- How to recover deleted files from the recycle bin, two methods of recovering files from the recycle bin
猜你喜欢
7. yaml
鲜花线上销售管理系统的设计与实现
C language, operators of shift operators (> >, < <) explanation

Parse method's parameter list (including parameter names)

2.0966 铝青铜板CuAl10Ni5Fe4铜棒

C194铜合金C19400铁铜合金

逮到一个阿里 10 年老 测试开发,聊过之后收益良多...
Design and implementation of flower online sales management system
基于SSM实现手机销售商城系统

VR全景+安全科普教育,让学生们提高安全意识
随机推荐
Summary of Confused Knowledge Points for "High Items" in the Soft Examination in the Second Half of 2022 (2)
如何判断一个数为多少进制?
后疫情时代,VR全景营销这样玩更加有趣!
部分准备金银行已经过时
【C语言】二分查找(折半查找)
HPb59-1铅黄铜
The Missing Semester of Your CS Education
【ORACLE】什么时候ROWNUM等于0和ROWNUM小于0,两个条件不等价?
CW614N铜棒CuZn39Pb3对应牌号
[C language] binary search (half search)
MySQL数据库基础操作
2.0966 铝青铜板CuAl10Ni5Fe4铜棒
安科瑞为工业能效行动计划提供EMS解决方案-Susie 周
ROS Experiment Notes - Validation of UZH-FPV Dataset
CDN原理与应用简要介绍
What is the ASIO4ALL
宝塔实测-搭建PHP在线模拟考试系统
Design and Realization of Employment Management System in Colleges and Universities
9. Rest style request processing
Activiti7子流程之Call activity