当前位置:网站首页>利用mindspore下面mindzoo里面的yolov3-darknet53进行目标识别,模型训练不收敛
利用mindspore下面mindzoo里面的yolov3-darknet53进行目标识别,模型训练不收敛
2022-08-11 08:52:00 【小乐快乐】
Modelzoo中yolov3-darknet53代码(mindspore1.1源码中的modelzoo)。
运行环境:mindspore-gpu1.4.1 docker,python3.7.5
【操作步骤&问题现象】
1、数据方面:原始数据是公开比赛数据xinye,标注标准是coco2014格式。数据的组织形式是按照yolov3-darknet53. 其中训练数据1300张,大小为960*720(width*height).原始数据图片和标注可视化后形式如下:

同时下载了
darknet53.conv.74
并用自带的工具进行格式转换生成了backbone_darknet53.ckpt.
2、训练过程如下:
尝试了对两种形式的数据进行训练:
A。直接用原始数据,没有做任何图片放缩。因为源码里面已经对图片做了416*416的切割。运行脚本run_distribute_train_gpu.sh 分别以lr=0.001,epoch=320,和lr=0.0003,epoch=2000进行训练,前者loss减少到170后者loss减少到127就不动了。模型不收敛,从而无法进行后处理。(加载了预训练模型)
B。对原始数据进行加工,把960*720的图片放缩到416*416(宽和高按照不同比例放缩),标注文件坐标进行相应放缩。运行脚本run_distribute_train_gpu.sh 分别以lr=0.001,epoch=320,和lr=0.0003,epoch=2000进行训练,前者loss减少到180左右后者loss减少到120左右就不动了。模型不收敛,从而无法进行后处理。(加载了预训练模型)
3、为了验证是不是数据本身不收敛。组内其他人员用基于pytorch的yolo3对同样的原始数据进行训练(源码为
https://github.com/ultralytics/yolov3,2.7k),模型收敛,loss减少到0.0..一下,模型收敛,从而后处理很正常。
我的问题是:是我的数据处理不正常,还是图片没有增强,还是预训练模型处理不正确,还是要调节其他参数(比赛数据有很多小物体)。应该向哪个方向改进。pytorch组内
对于多个物体的场景可以通过配置文件中配置适当参数,yolov3-darknet53中没看到相应接口。能否给下宝贵意见,多谢!
【截图信息】
日志

1. 针对小目标的检测,通常是通过修改anchor大小来匹配,你可以通过default_config.yaml里面的anchor_scales配置来进行修改。通常这个anchor_scales,是通过在训练集上做聚类来得到的。也可以考虑根据感觉来手动调整。
如果是希望通过修改模型结构来适配小目标,那就只能手动修改代码了,配置文件中没有对应的选项。
2. 检测模型通常对超参比较敏感,如果不收敛,可以考虑加大一下调参的范围,比如lr扩大10倍到0.01的级别。
另外,不知道你的配置修改是在什么地方改的,如果是在yaml文件里改的,有可能会被bash文件里的配置覆盖。
同时,由于可选cosine等周期学习率,改超参配置的时候,还要注意一下bash文件里的T_Max选项,是用来控制周期长度的,如果是希望学习率单调下降,通常配置和总epoch数一致。
3. 模型不收敛的问题,通常是由于梯度异常导致的训练,会直接更新出一个很离谱的权重。你可以查看一下训练中间状态的权重文件,看是否存在一些极大的异常值,比如绝对值有好几十亿这种,如果有的话,可以考虑加一些梯度后处理或者溢出检测机制来避免使用异常梯度来更新权重。
边栏推荐
猜你喜欢
如何通过开源数据库管理工具 DBeaver 连接 TDengine
Continuous Integration/Continuous Deployment (2) Jenkins & SonarQube
2022-08-10:为了给刷题的同学一些奖励,力扣团队引入了一个弹簧游戏机, 游戏机由 N 个特殊弹簧排成一排,编号为 0 到 N-1, 初始有一个小球在编号 0 的弹簧处。若小球在编号为 i 的弹
Nuget找不到包的问题处理
Jupyter Notebook 插件 contrib nbextension 安装使用
One network cable to transfer files between two computers
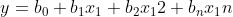
机器学习(三)多项式回归
mysql数据查询因为查询的时间跨度过大导致cup爆满应该怎么办

【实战系列】OpenApi设计规范
磁盘管理:磁盘结构
随机推荐
Unity3D——自定义类的Inspector面板的修改
for循环和单击相应函数的执行顺序问题
Features of LoRa Chips
dsu on tree(树上启发式合并)学习笔记
DataGrip配置OceanBase
picker选择器出现object解决办法
WiFi cfg80211
Kotlin算法入门求自由落体
机器学习(三)多项式回归
《剑指offer》题解——week3(持续更新)
Jupyter Notebook 插件 contrib nbextension 安装使用
Initial use of IDEA
你有对象类,我有结构体,Go lang1.18入门精炼教程,由白丁入鸿儒,go lang结构体(struct)的使用EP06
Go 语言的诞生
Openlayers 聚合图、权重聚合图以及聚合图点击事件
Kotlin算法入门兔子数量优化及拓展
用 Antlr 重构脚本解释器
Kotlin算法入门求完全数
框架外的PHP读取.env文件(php5.6、7.3可用版)
仙人掌之歌——大规模高速扩张(1)