当前位置:网站首页>从TRPO到PPO(理论分析与数学证明)
从TRPO到PPO(理论分析与数学证明)
2022-08-09 23:00:00 【行者AI】
本文首发于行者AI
引言
一篇关于强化学习算法的理论推导,或许可以帮助你理解PPO算法背后的原理,从而找到改进PPO算法的灵感…
马尔可夫决策过程由 ( S , A , P , r , ρ 0 , γ ) (S, A, P, r, \rho_0, \gamma) (S,A,P,r,ρ0,γ)六个元素构成。其中 S S S是一个有限的状态空间集合, A A A是一个有限的动作空间集合。 P : S × A × S → R P: S \times A \times S \rightarrow \mathbb{R} P:S×A×S→R 表示状态转移概率函数,例如 P ( s ′ ∣ s , a ) = 0.6 P(s'|s,a)=0.6 P(s′∣s,a)=0.6表示的含义就是在状态 s s s处执行动作 a a a到达的状态为 s ′ s' s′的概率为0.6。 r : S → R r: S\rightarrow \mathbb{R} r:S→R是奖励函数, ρ 0 : S → R \rho_0: S\rightarrow\mathbb{R} ρ0:S→R是初始状态分布概率函数, γ ∈ ( 0 , 1 ) \gamma\in (0,1) γ∈(0,1)是折扣因子。
让 π \pi π表示一个随机策略函数 π : S × A → [ 0 , 1 ] \pi: S\times A\rightarrow [0,1] π:S×A→[0,1],例如 π ( s , a ) = 0.5 \pi(s,a)=0.5 π(s,a)=0.5表示在状态 s s s处选择动作 a a a的概率为0.5。令 η ( π ) \eta(\pi) η(π)表示基于策略 π \pi π的长期期望折扣奖励: η ( π ) = E s 0 , a 0 , … [ ∑ t = 0 ∞ γ t r ( s t ) ] \eta(\pi) = \mathbb{E}_{s_0, a_0,\ldots}[\sum\limits_{t=0}^{\infty}\gamma^t r(s_t)] η(π)=Es0,a0,…[t=0∑∞γtr(st)], 其中 s 0 ∼ ρ 0 ( s 0 ) , a t ∼ π ( a t ∣ s t ) , s t + 1 ∼ P ( s t + 1 ∣ s t , a t ) s_0\sim \rho_0(s_0), a_t\sim \pi(a_t|s_t), s_{t+1}\sim P(s_{t+1}|s_t,a_t) s0∼ρ0(s0),at∼π(at∣st),st+1∼P(st+1∣st,at)。
下面给出状态价值函数、状态动作价值函数、优势函数的定义:
(1)状态动作价值函数:
Q π ( s t , a t ) = E s t + 1 , a t + 1 , … [ ∑ l = 0 ∞ γ l r ( s t + l ) ] Q_\pi(s_t,a_t) = \mathbb{E}_{s_{t+1},a_{t+1},\ldots}[\sum\limits_{l=0}^\infty\gamma^lr(s_{t+l})] Qπ(st,at)=Est+1,at+1,…[l=0∑∞γlr(st+l)]
表示的是在状态 s t s_t st处执行动作 a t a_t at后获得的长期期望折扣奖励。
(2)状态价值函数:
V π ( s t ) = E a t , s t + 1 , … [ ∑ l = 0 ∞ γ l r ( s t + l ) ] = E a t [ Q π ( s t , a t ) ] V_\pi(s_t) = \mathbb{E}_{a_t, s_{t+1},\ldots}[\sum\limits_{l=0}^\infty\gamma^lr(s_{t+l})] = \mathbb{E}_{a_t}[Q_\pi(s_t, a_t)] Vπ(st)=Eat,st+1,…[l=0∑∞γlr(st+l)]=Eat[Qπ(st,at)]
表示从状态 s t s_t st开始获得的长期期望折扣奖励。
(3)优势函数:
A π ( s , a ) = Q π ( s , a ) − V π ( s , a ) A_\pi(s, a) = Q_\pi(s,a) - V_\pi(s,a) Aπ(s,a)=Qπ(s,a)−Vπ(s,a)
表示的是在状态 s s s处,动作 a a a相对于平均水平的高低。
强化学习的目标就是最大化长期期望折扣奖励
η ( π ) = E s 0 , a 0 , … [ ∑ t = 0 ∞ γ t r ( s t ) ] \eta(\pi) = \mathbb{E}_{s_0, a_0,\ldots}[\sum\limits_{t=0}^{\infty}\gamma^t r(s_t)] η(π)=Es0,a0,…[t=0∑∞γtr(st)]
其中策略函数 π \pi π可以看作是带有参数 θ \theta θ的随机策略 π ( s , a ) = π θ ( s , a ) \pi(s,a) = \pi_\theta(s,a) π(s,a)=πθ(s,a)。在策略梯度算法(Policy Gradient)中,参数 θ \theta θ的更新公式为
θ n e w = θ o l d + α ∇ θ η ( θ ) \theta_{new} = \theta_{old} + \alpha\nabla_{\theta}\eta(\theta) θnew=θold+α∇θη(θ)
这样的更新公式容易导致以下问题:如果步长 α \alpha α选取不合适,那么会导致 θ n e w \theta_{new} θnew比 θ o l d \theta_{old} θold差,当使用 θ n e w \theta_{new} θnew进行采样学习的时候,采取到的样本就是比较差的样本,再继续使用不好的样本对参数进行更新,得到的是更加不好的策略,从而导致恶性循环。TRPO算法解决的问题就是:如何选择一个合适的更新策略,或是如何选择一个合适的步长,使得更新过后的策略 π θ n e w \pi_{\theta_{new}} πθnew一定比更新前的策略 π θ o l d \pi_{\theta_{old}} πθold好呢?
1.TRPO的理论分析
1.1 不同策略的长期期望折扣奖励之间的关系
先来看一下基于策略 π \pi π的长期折扣奖励
η ( π ) = E s 0 , a 0 , … [ ∑ t = 0 ∞ γ t r ( s t ) ] \eta({\pi}) = \mathbb{E}_{s_0,a_0,\ldots}[\sum\limits_{t=0}^{\infty}\gamma^t r(s_t)] η(π)=Es0,a0,…[t=0∑∞γtr(st)]
对于另一个策略 π ~ \tilde{\pi} π~,两个策略之间的长期折扣奖励函数 η ( π ~ ) \eta(\tilde{\pi}) η(π~)与 η ( π ) \eta(\pi) η(π)之间的关系为:
η ( π ~ ) = η ( π ) + E s 0 , a 0 , … ∼ π ~ [ ∑ t = 0 ∞ γ t A π ( s t , a t ) ] ( 3.1 ) \eta(\tilde{\pi}) = \eta(\pi) + \mathbb{E}_{s_0,a_0,\ldots\sim\tilde{\pi}}[\sum\limits_{t=0}^\infty \gamma^t A_{\pi}(s_t,a_t)]\ \ \ \ \ \ \ (3.1) η(π~)=η(π)+Es0,a0,…∼π~[t=0∑∞γtAπ(st,at)] (3.1)
其中 A π ( s t , a t ) A_\pi(s_t,a_t) Aπ(st,at)为优势函数, A π ( s t , a t ) = Q π ( s t , a t ) − V π ( s t ) A_\pi(s_t,a_t) = Q_\pi(s_t,a_t) - V_\pi(s_t) Aπ(st,at)=Qπ(st,at)−Vπ(st)。(证明过程见文章后面附录证明4.1)。
上述公式要注意的点是 s 0 , a 0 , … ∼ π ~ s_0,a_0,\ldots\sim\tilde{\pi} s0,a0,…∼π~表示轨迹中的状态和动作都是基于策略 π ~ \tilde{\pi} π~采样得到的,而 A π ( s t , a t ) A_{\pi}(s_t,a_t) Aπ(st,at)表示的是策略 π \pi π的优势函数。
为了方便公式的书写和后续求导的计算,定义
ρ π ( s ) = P ( s 0 = s ) + γ P ( s 1 = s ) + γ 2 P ( s 2 = s ) + … \rho_\pi(s) = P(s_0=s) + \gamma P(s_1=s) + \gamma^2 P(s_2=s) + \ldots ρπ(s)=P(s0=s)+γP(s1=s)+γ2P(s2=s)+…
则公式 ( 3.1 ) (3.1) (3.1)可以改写为:
η ( π ~ ) = η ( π ) + ∑ s ρ π ~ ( s ) ∑ s π ~ ( a ∣ s ) A π ( s , a ) ( 3.2 ) \eta({\tilde{\pi}}) = \eta({\pi}) + \sum\limits_s\rho_{\tilde{\pi}}(s)\sum\limits_s\tilde{\pi}(a|s)A_\pi(s,a) \ \ \ \ \ \ \ \ (3.2) η(π~)=η(π)+s∑ρπ~(s)s∑π~(a∣s)Aπ(s,a) (3.2)
证明过程见文章后面附录证明4.2。
1.2 替代函数的建立
再来回顾一下我们在背景中提出的目标:找到一个合适的步长,使得每一个更新得到的新的策略 π n e w \pi_{new} πnew要比更新前的策略 π o l d \pi_{old} πold好,体现在公式上就是要求 η ( π n e w ) ≥ η ( π o l d ) \eta(\pi_{new}) \ge \eta(\pi_{old}) η(πnew)≥η(πold)。
由于公式 ( 3.2 ) (3.2) (3.2)中的 ρ π ~ \rho_{\tilde{\pi}} ρπ~对 π ~ \tilde{\pi} π~有强烈的依赖性,但是在更新之前我们还不知道策略 π ~ \tilde{\pi} π~的具体形式,所以我们考虑找到一个 η ( π ~ ) \eta(\tilde{\pi}) η(π~)的替代函数:
L π ( π ~ ) = η ( π ) + ∑ s ρ π ( s ) ∑ a π ~ ( a ∣ s ) A π ( s , a ) ( 3.3 ) L_\pi(\tilde{\pi}) = \eta({\pi}) + \sum\limits_s\rho_\pi(s)\sum\limits_a\tilde{\pi}(a|s)A_\pi(s,a) \ \ \ \ \ \ \ (3.3) Lπ(π~)=η(π)+s∑ρπ(s)a∑π~(a∣s)Aπ(s,a) (3.3)
这个替代函数的作用是什么呢,可以帮助我们得到 η \eta η函数的哪些性质呢?把策略 π \pi π表示为带有参数 θ \theta θ的随机策略 π = π θ \pi=\pi_\theta π=πθ,给出下面定理: L π θ 0 ( π θ ) L_{\pi_{\theta_0}}(\pi_\theta) Lπθ0(πθ)与 η ( π θ ) \eta(\pi_\theta) η(πθ)在 θ 0 \theta_0 θ0处一阶近似,用公式表示为:
{ L π θ 0 ( π θ 0 ) = η ( π θ 0 ) ∇ θ L π θ 0 ( π θ ) ∣ θ = θ 0 = ∇ θ η ( π θ ) ∣ θ = θ 0 \left\{ \begin{aligned} L_{\pi_{\theta_0}}(\pi_{\theta_0})& = \eta(\pi_{\theta_0})\\ \nabla_{\theta}L_{\pi_{\theta_0}}(\pi_\theta)|_{\theta=\theta_0}& = \nabla_\theta\eta(\pi_\theta)|_{\theta=\theta_0}\\ \end{aligned} \right. { Lπθ0(πθ0)∇θLπθ0(πθ)∣θ=θ0=η(πθ0)=∇θη(πθ)∣θ=θ0
证明过程见文章后面附录证明4.3。
上述公式的第二个等式可以告诉我们:在 θ = θ 0 \theta = \theta_0 θ=θ0附近, η ( π θ ) = L π θ 0 ( π θ ) \eta(\pi_\theta) = L_{\pi_{\theta_0}}(\pi_\theta) η(πθ)=Lπθ0(πθ)的曲线的变化趋势相同,因为一阶导数的意义就是曲线的变化趋势。又因为这两个函数在 θ = θ 0 \theta = \theta_0 θ=θ0处的值相等(公式的第一个等式),所以在 θ = θ 0 \theta = \theta_0 θ=θ0的附近,可以通过优化 L π θ 0 ( π θ ) L_{\pi_{\theta_0}}(\pi_\theta) Lπθ0(πθ)来达到优化 η ( π θ ) \eta(\pi_\theta) η(πθ)的目的,注意是: θ = θ 0 \theta = \theta_0 θ=θ0的附近!!!附近!!!下面给出一个一阶近似的例子:
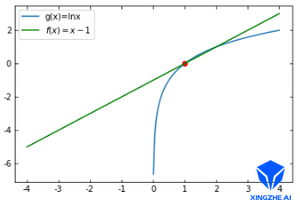
如图所示:函数 f ( x ) = x − 1 f(x) = x-1 f(x)=x−1 与 函数 g ( x ) = l n x g(x) = lnx g(x)=lnx在 x = 1 x=1 x=1处是一阶近似的,即 f ( 1 ) = g ( 1 ) f(1) = g(1) f(1)=g(1), f ′ ( 1 ) = g ′ ( 1 ) f'(1) = g'(1) f′(1)=g′(1),所以这两个函数的曲线的变化趋势在 x = 1 x=1 x=1处是近乎相同的。
用 π o l d \pi_{old} πold来表示更新前的策略,定义 π ′ = a r g m a x π ′ L π o l d ( π ′ ) \pi' = argmax_{\pi'}L_{\pi_{old}}(\pi') π′=argmaxπ′Lπold(π′)
我们采用一种软更新的方式对策略进行更新,更新公式为
π n e w = ( 1 − α ) π o l d + α π ′ ( 3.4 ) \pi_{new} = (1-\alpha)\pi_{old} + \alpha\pi' \ \ \ \ \ \ \ \ (3.4) πnew=(1−α)πold+απ′ (3.4)
其中 π n e w \pi_{new} πnew就表示更新之后的策略, α \alpha α为更新步长。
部分读者在阅读到这里的时候可能会产生以下疑问:为什么不直接把 π ′ \pi' π′直接当作更新之后的策略呢? L π o l d ( π ′ ) ≥ L π o l d ( π o l d ) L_{\pi_{old}}(\pi')\ge L_{\pi_{old}}(\pi_{old}) Lπold(π′)≥Lπold(πold)不是可以推导出 η ( π ′ ) ≥ η ( π o l d ) \eta(\pi')\ge\eta(\pi_{old}) η(π′)≥η(πold)吗?
解答:因为这是一种迭代更新方式, π ′ \pi' π′只是给出了一个可以优化 π o l d \pi_{old} πold的方向,我们要做的是将 π o l d \pi_{old} πold向 π ′ \pi' π′的那个方向迭代,而不是直接将 π ′ \pi' π′当作更新之后的策略;另外 L π o l d ( π ′ ) ≥ L π o l d ( π o l d ) L_{\pi_{old}}(\pi')\ge L_{\pi_{old}}(\pi_{old}) Lπold(π′)≥Lπold(πold)并不可以直接推导出 η ( π ′ ) ≥ η ( π o l d ) \eta(\pi')\ge\eta(\pi_{old}) η(π′)≥η(πold),因为 π ′ \pi' π′并不一定在 π o l d \pi_{old} πold的附近!
1.3 TRPO算法的推出
再来回顾一下我们最初的目的:找到一个合适的步长,使得每一个更新得到的新的策略 π n e w \pi_{new} πnew要比更新前的策略 π o l d \pi_{old} πold好。那么使用软更新方式得到的策略 π n e w \pi_{new} πnew是否比更新前的策略 π o l d \pi_{old} πold好呢,换句话说,是否成立 η ( π n e w ) ≥ η ( π o l d ) \eta(\pi_{new})\ge \eta(\pi_{old}) η(πnew)≥η(πold)呢?其实 π ′ = a r g m a x π ′ L π o l d ( π ′ ) \pi' = argmax_{\pi'}L_{\pi_{old}}(\pi') π′=argmaxπ′Lπold(π′)给我们的优化提供了方向,我们的关键就在于如何选择合适的步长使得更新之后的策略一定是比更新之前的策略好。再思考一下,其实一定有 L π o l d ( π n e w ) ≥ L π o l d ( π o l d ) L_{\pi_{old}}(\pi_{new}) \ge L_{\pi_{old}}(\pi_{old}) Lπold(πnew)≥Lπold(πold), 因为 π n e w \pi_{new} πnew是从 π o l d \pi_{old} πold朝着 π ′ \pi' π′的方向迭代的,并且 L π o l d ( π ′ ) ≥ L π o l d ( π o l d ) L_{\pi_{old}}(\pi')\ge L_{\pi_{old}}(\pi_{old}) Lπold(π′)≥Lπold(πold)。再回想一下前面我们说:在 π = π o l d \pi = \pi_{old} π=πold附近, L π o l d ( π ) ≥ L π o l d ( π o l d ) L_{\pi_{old}}(\pi)\ge L_{\pi_{old}}(\pi_{old}) Lπold(π)≥Lπold(πold)等价于 η ( π ) ≥ η ( π o l d ) \eta(\pi)\ge \eta(\pi_{old}) η(π)≥η(πold), 所以我们只需要把 π n e w \pi_{new} πnew限制在 π o l d \pi_{old} πold附近即可,可以通过放在惩罚项或者约束上进行限制。如何限制两个策略的差异性呢,可以使用两个策略的KL散度: D K L m a x ( θ o l d , θ n e w ) D_{KL}^max(\theta_{old}, \theta_{new}) DKLmax(θold,θnew),因为KL散度是用来度量两个概率分布相似度的指标。其实从这个分析我们就可以得到最终的TRPO算法了,原论文中给出了严格的数学推导,我们大概介绍一下思路(可以不看):
设 π n e w \pi_{new} πnew是按照更新公式 ( 3.4 ) (3.4) (3.4)得到的新策略,从论文[1]中可以得到下面不等式成立:
η ( π n e w ) ≥ L π o l d ( π n e w ) − 2 ϵ γ ( 1 − γ ) 2 α 2 ( 3.5 ) \eta(\pi_{new})\ge L_{\pi_{old}}(\pi_{new}) - \frac{2\epsilon \gamma}{(1-\gamma)^2}\alpha^2 \ \ \ \ \ \ \ (3.5) η(πnew)≥Lπold(πnew)−(1−γ)22ϵγα2 (3.5)
其中 ϵ = m a x s ∣ E a ∼ π ′ ( a ∣ s ) [ A π ( s , a ) ] ∣ \epsilon = max_s|\mathbb{E}_{a\sim \pi'(a|s)}[A_\pi(s,a)]| ϵ=maxs∣Ea∼π′(a∣s)[Aπ(s,a)]∣。
我们可以令 α = D T V m a x ( π o l d , π n e w ) \alpha = D^{max}_{TV}(\pi_{old}, \pi_{new}) α=DTVmax(πold,πnew), 进而成立:
η ( π n e w ) ≥ L π o l d ( π n e w ) − 4 ϵ γ ( 1 − γ ) 2 α 2 \eta(\pi_{new})\ge L_{\pi_{old}}(\pi_{new}) - \frac{4\epsilon\gamma}{(1-\gamma)^2}\alpha^2 η(πnew)≥Lπold(πnew)−(1−γ)24ϵγα2
其中 ϵ = m a x s , a ∣ A π ( s , a ) ∣ \epsilon = max_{s,a}|A_\pi(s,a)| ϵ=maxs,a∣Aπ(s,a)∣。
再根据不等式: D T V ( p ∣ ∣ q ) 2 ≤ D K L ( p ∣ ∣ q ) D_{TV}(p||q)^2\le D_{KL}(p||q) DTV(p∣∣q)2≤DKL(p∣∣q),令 D K L m a x ( π , π ~ ) = m a x s D K L ( π ( ⋅ ∣ s ) ∣ ∣ π ~ ( ⋅ ∣ s ) ) D_{KL}^{max}(\pi, \tilde{\pi}) = max_s D_{KL}(\pi(·|s)||\tilde{\pi}(·|s)) DKLmax(π,π~)=maxsDKL(π(⋅∣s)∣∣π~(⋅∣s)) 成立:
η ( π ~ ) ≥ L π ( π ~ ) − C D K L m a x ( π , π ~ ) \eta(\tilde{\pi}) \ge L_\pi(\tilde{\pi}) - CD_{KL}^{max}(\pi, \tilde{\pi}) η(π~)≥Lπ(π~)−CDKLmax(π,π~)
其中 C = 4 ϵ γ ( 1 − γ ) 2 C = \frac{4\epsilon\gamma}{(1-\gamma)^2} C=(1−γ)24ϵγ。
给出下面策略更新算法:

假设我们根据上面这个算法得出一个策略序列 π 0 , π 1 , … \pi_0, \pi_1, \ldots π0,π1,…,下面证明该策略序列是越来越好的,即 η ( π 0 ) ≤ η ( π 1 ) ≤ … \eta(\pi_0)\le\eta(\pi_1)\le\ldots η(π0)≤η(π1)≤…。
令 M i ( π ) = L π i ( π ) − C D K L m a x ( π i , π ) M_i(\pi) = L_{\pi_i}(\pi) - CD_{KL}^{max}(\pi_i, \pi) Mi(π)=Lπi(π)−CDKLmax(πi,π), 则成立:
η ( π i + 1 ) ≥ M i ( π i + 1 ) \eta(\pi_{i+1})\ge M_i(\pi_{i+1}) η(πi+1)≥Mi(πi+1)
η ( π i ) = M i ( π i ) \eta(\pi_i) = M_i(\pi_i) η(πi)=Mi(πi)
等式成立是因为当 π ~ = π \tilde{\pi} = \pi π~=π时, D K L m a x ( π , π ~ ) = 0 D_{KL}^{max}(\pi, \tilde{\pi}) = 0 DKLmax(π,π~)=0。
所以成立: η ( π i + 1 ) − η ( π i ) ≥ M i ( π i + 1 ) − M ( π i ) \eta(\pi_{i+1}) - \eta(\pi_i) \ge M_i(\pi_{i+1}) - M(\pi_i) η(πi+1)−η(πi)≥Mi(πi+1)−M(πi)
所以在第i次迭代时, M i ( π ) M_i(\pi) Mi(π)可以作为 η ( π ) \eta(\pi) η(π)的替代函数,从而得到的策略序列是越来越好的。进而每一个更新过后的策略 π n e w \pi_{new} πnew都好于更新前的策略 π o l d \pi_{old} πold。目的达到。
如果这个数学证明没看懂没有关系,可以直接通过之前的语言分析理解TRPO算法。
为了方便将 π θ o l d \pi_{\theta_{old}} πθold写作 θ o l d \theta_{old} θold, 在接下来的分析中,我们都考虑带有参数 θ \theta θ的策略 π θ ( a ∣ s ) \pi_\theta(a|s) πθ(a∣s)。通过之前的分析,从而我们可以通过优化下面的式子来达到优化 η ( π ) \eta(\pi) η(π)的目的:
m a x i m i z e θ [ L θ o l d ( θ ) − C D K L m a x ( θ o l d , θ ) ] maximize_\theta\ \ [L_{\theta_{old}}(\theta) - CD_{KL}^max(\theta_{old}, \theta)] maximizeθ [Lθold(θ)−CDKLmax(θold,θ)]
但是有C作为惩罚系数,会导致每次的 D K L m a x ( θ o l d , θ ) D_{KL}^max(\theta_{old},\theta) DKLmax(θold,θ)的值特别小,从而导致更新的步子很小,降低更新速度,所以我们考虑将惩罚项变为约束项:
m a x i m i z e θ L θ o l d ( θ ) s u b j e c t t o D K L m a x ( θ o l d , θ ) ≤ δ \begin{aligned} maximize_\theta&\ \ L_{\theta_{old}}(\theta)\\ subject\ \ to&\ \ D_{KL}^{max}(\theta_{old}, \theta)\le \delta \end{aligned} maximizeθsubject to Lθold(θ) DKLmax(θold,θ)≤δ
用语言理解就是在以 θ 0 \theta_0 θ0为球(圆)心,以 δ \delta δ为半径的区域中搜索可以提高 L π o l d ( π ) L_{\pi_{old}}(\pi) Lπold(π)(等价于提高 η ( π ) \eta(\pi) η(π))的策略 π \pi π。这就是TRPO算法。
注意到 L θ o l d ( θ ) = η ( θ o l d ) + ∑ s ρ θ o l d ( s ) ∑ a π θ ( a ∣ s ) A θ o l d ( s , a ) L_{\theta_{old}}(\theta) = \eta(\theta_{old}) + \sum\limits_s\rho_{\theta_{old}}(s)\sum\limits_a\pi_\theta(a|s)A_{\theta_{old}}(s,a) Lθold(θ)=η(θold)+s∑ρθold(s)a∑πθ(a∣s)Aθold(s,a), 其中 η ( θ o l d ) \eta(\theta_{old}) η(θold)相对于 θ \theta θ来说是常数,可以去掉,因此上述公式变为
m a x i m i z e θ ∑ s ρ θ o l d ∑ a π θ ( a ∣ s ) A θ o l d ( s , a ) s u b j e c t t o D K L m a x ( θ o l d , θ ) ≤ δ \begin{aligned} maximize_\theta&\ \ \sum\limits_s\rho_{\theta_{old}}\sum\limits_a\pi_\theta(a|s)A_{\theta_{old}}(s,a)\\ subject\ \ to&\ \ D_{KL}^{max}(\theta_{old}, \theta)\le \delta \end{aligned} maximizeθsubject to s∑ρθolda∑πθ(a∣s)Aθold(s,a) DKLmax(θold,θ)≤δ
1.4 重要度采样
在最开始推导公式 ( 3.1 ) (3.1) (3.1)的时候,我们当时说了等号右边的 s , a s,a s,a是基于策略 π ~ \tilde{\pi} π~采样的,但是在真实世界中,因为在更新前 π ~ \tilde{\pi} π~是未知的,所以我们没法基于 π ~ \tilde{\pi} π~采样,所以我们考虑使用重要度采样,假设我们使用策略 q ( a ∣ s ) q(a|s) q(a∣s)进行采样,那么我们的优化函数要有所变化:
∑ s ρ θ o l d ( s ) ∑ a π ( a ∣ s ) A π ( s , a ) = ∑ s ρ θ o l d ( s ) ∑ a q ( a ∣ s ) π θ ( a ∣ s ) q ( a ∣ s ) A θ o l d ( s , a ) = ∑ s ρ θ o l d ( s ) E a ∼ q [ π θ ( a ∣ s ) q ( a ∣ s ) A θ o l d ( s , a ) ] = E s ∼ ρ θ o l d , a ∼ q [ A θ o l d ( s , a ) ] \begin{aligned} \sum\limits_s\rho_{\theta_{old}}(s)\sum\limits_a\pi(a|s)A_\pi(s,a)&=\sum\limits_s\rho_{\theta_{old}}(s)\sum\limits_aq(a|s)\frac{\pi_\theta(a|s)}{q(a|s)}A_{\theta_{old}}(s,a)\\ &=\sum\limits_s\rho_{\theta_{old}}(s)\mathbb{E}_{a\sim q}[\frac{\pi_\theta(a|s)}{q(a|s)}A_{\theta_{old}}(s,a)]\\ &=\mathbb{E}_{s\sim \rho_{\theta_{old}},a\sim q}[A_{\theta_{old}}(s,a)] \end{aligned} s∑ρθold(s)a∑π(a∣s)Aπ(s,a)=s∑ρθold(s)a∑q(a∣s)q(a∣s)πθ(a∣s)Aθold(s,a)=s∑ρθold(s)Ea∼q[q(a∣s)πθ(a∣s)Aθold(s,a)]=Es∼ρθold,a∼q[Aθold(s,a)]
所以最终TRPO的更新算法变为:
m a x i m i z e θ E s ∼ ρ θ o l d , a ∼ q [ A θ o l d ( s , a ) ] s u b j e c t t o D K L ( θ o l d , θ ) ≤ δ \begin{aligned} maximize_\theta&\ \ \mathbb{E}_{s\sim \rho_{\theta_{old}},a\sim q}[A_{\theta_{old}}(s,a)]\\ subject\ \ to&\ \ D_{KL}(\theta_{old}, \theta)\le \delta \end{aligned} maximizeθsubject to Es∼ρθold,a∼q[Aθold(s,a)] DKL(θold,θ)≤δ
注意:这里的 s s s还是服从 ρ θ o l d \rho_{\theta_{old}} ρθold的概率,即 ρ θ o l d ( s ) \rho_{\theta_{old}}(s) ρθold(s)中的动作 a a a的概率还是基于策略 θ o l d \theta_{old} θold!!这里是大家比较容易理解错误的地方,误以为 s s s公式中的 a a a是基于采样策略 q q q的。并且这里的采样概率 q ( a ∣ s ) q(a|s) q(a∣s)可以是任意的,只用来采样而已!!后来TRPO算法在做的时候直接将 π θ o l d ( a ∣ s ) \pi_{\theta_{old}}(a|s) πθold(a∣s)当作采样策略 q ( a ∣ S ) q(a|S) q(a∣S)。
2. PPO算法的理论分析
2.1 TRPO算法的局限性
但是采样策略 q q q真的可以任意吗?太任意会出现什么问题呢?我们来看下面这个例子:
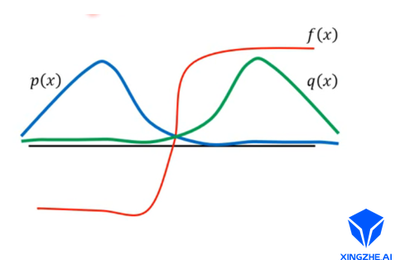
如图所示, p ( x ) p(x) p(x)是真实的分布概率, q ( x ) q(x) q(x)是采样时候使用的概率,显然二者的差异很大。设曲线 p ( x ) , q ( x ) , f ( x ) p(x),q(x),f(x) p(x),q(x),f(x)交点的横坐标为 x = 0 x=0 x=0,所以在采样的时候,我们大多采到的是 x > 0 x>0 x>0的点,因为 q ( x ) q(x) q(x)在正半轴的概率值更大,所以我们最终得到的 E x [ f ( x ) ] \mathbb{E}_x[f(x)] Ex[f(x)]的值为正值,但是真实的状况是, x x x大多分布在负半轴,真实的 E x [ f ( x ) ] \mathbb{E}_x[f(x)] Ex[f(x)]应该为负值,这就是由于采样概率和真实概率差距过大导致的误差。
所以我们还得限制采样策略 q ( a ∣ s ) q(a|s) q(a∣s)和更新策略 π ( a ∣ s ) \pi(a|s) π(a∣s)的相似度,使得他们尽可能的相像,这就是PPO算法要做的事情了。
2.2 PPO算法
第一种思路:记得我们在分析TRPO算法中,使用了KL散度限制了策略 π θ ( a ∣ s ) \pi_{\theta}(a|s) πθ(a∣s)和策略 π θ o l d ( a ∣ s ) \pi_{\theta_{old}}(a|s) πθold(a∣s)的相似度,使得他们两个的差距不能太大,所以我们考虑直接用 π θ o l d ( a ∣ s ) \pi_{\theta_{old}}(a|s) πθold(a∣s)当作采样策略 q ( a ∣ s ) q(a|s) q(a∣s),所以这就同时限制了采样策略和策略 π θ ( a ∣ s ) \pi_\theta(a|s) πθ(a∣s)的差距,一举两得,这就得到了PPO算法:
m a x i m i z e θ E s , a ∼ θ o l d [ A θ o l d ( s , a ) − β D K L ( θ o l d , θ ) ] \begin{aligned} maximize_\theta&\ \ \mathbb{E}_{s,a\sim \theta_{old}}[A_{\theta_{old}}(s,a) - \beta D_{KL}(\theta_{old}, \theta)] \end{aligned} maximizeθ Es,a∼θold[Aθold(s,a)−βDKL(θold,θ)]
注意到这里的 ρ ( s ) \rho(s) ρ(s)公式中的 a a a的概率也是基于策略 θ o l d \theta_{old} θold的。
2.3 PPO2算法
第二种思路:在优化公式中对 q ( a ∣ s ) q(a|s) q(a∣s)和 π θ ( a ∣ s ) \pi_{\theta}(a|s) πθ(a∣s)进行限制,采用了截断函数,当两个函数的比值过大时,用 1 + ϵ 1+\epsilon 1+ϵ截断,当两个函数的比值过小时,采用 1 − ϵ 1-\epsilon 1−ϵ截断。PPO2算法如下:
m a x i m i z e θ E s ∼ ρ θ o l d , a ∼ q ( a ∣ s ) m i n ( π θ ( a ∣ s ) q ( a ∣ s ) A θ o l d ( s , a ) , c l i p ( π θ ( a ∣ s ) q ( a ∣ s ) , 1 − ϵ , 1 + ϵ ) A θ o l d ( a ∣ s ) ) \begin{aligned} maximize_\theta&\ \ \mathbb{E}_{s\sim \rho_{\theta_{old}},a\sim q(a|s)}min(\frac{\pi_\theta(a|s)}{q(a|s)}A_{\theta_{old}}(s,a), clip(\frac{\pi_\theta(a|s)}{q(a|s)}, 1-\epsilon, 1+\epsilon)A_{\theta_{old}}(a|s)) \end{aligned} maximizeθ Es∼ρθold,a∼q(a∣s)min(q(a∣s)πθ(a∣s)Aθold(s,a),clip(q(a∣s)πθ(a∣s),1−ϵ,1+ϵ)Aθold(a∣s))
其实这里的采样策略 q ( a ∣ s ) q(a|s) q(a∣s)是可以使用任意采样策略的,可能是为了效果更好,在PPO的论文中,依然按照TRPO算法的方式,将 π θ o l d ( a ∣ s ) \pi_{\theta_{old}}(a|s) πθold(a∣s)作为采样策略 q ( a ∣ s ) q(a|s) q(a∣s):
m a x i m i z e θ E s , a ∼ θ o l d m i n ( π θ ( a ∣ s ) π θ o l d ( a ∣ s ) A θ o l d ( s , a ) , c l i p ( π θ ( a ∣ s ) π θ o l d ( a ∣ s ) , 1 − ϵ , 1 + ϵ ) A θ o l d ( a ∣ s ) ) \begin{aligned} maximize_\theta&\ \ \mathbb{E}_{s,a\sim \theta_{old}}min(\frac{\pi_\theta(a|s)}{\pi_{\theta_{old}}(a|s)}A_{\theta_{old}}(s,a), clip(\frac{\pi_\theta(a|s)}{\pi_{\theta_{old}}(a|s)}, 1-\epsilon, 1+\epsilon)A_{\theta_{old}}(a|s)) \end{aligned} maximizeθ Es,a∼θoldmin(πθold(a∣s)πθ(a∣s)Aθold(s,a),clip(πθold(a∣s)πθ(a∣s),1−ϵ,1+ϵ)Aθold(a∣s))
3.参考文献
[1] Kakade,Sham and Langford,John. Approximately optimal approximate reinfocement learning(https://citeseerx.ist.psu.edu/viewdoc/download;jsessionid=EAB75A180B3AE59A7A516BF93A00863C?doi=10.1.1.7.7601&rep=rep1&type=pdf). In ICML, volume2,pp.267-247,2002.
[2] R.Sutton, D.McAllester, S.Singh, and Y.Mansour. Policy gradient methods for reinforcement learning with function approximation(https://homes.cs.washington.edu/~todorov/courses/amath579/reading/PolicyGradient.pdf). Neural Information Processing Systemsm,13,2000.
[3] J.Schulman, S.Levine, P.Moritz, M.I.Jordan, and P.Abbeel.“Trust region policy optimization”(https://arxiv.org/abs/1502.05477). In: CoRR, ans/1502.05477(2015).
[4] Proximal Policy Optimization Algorithms](https://arxiv.org/abs/1707.06347), Schulman et al. 2017
4.附录证明
4.1 证明: η ( π ~ ) = η ( π ) + E s 0 , a 0 , … ∼ π ~ [ ∑ t = 0 ∞ γ t A π ( s t , a t ) ] \eta(\tilde{\pi}) = \eta(\pi) + \mathbb{E}_{s_0,a_0,\ldots\sim\tilde{\pi}}[\sum\limits_{t=0}^\infty\gamma^t A_\pi(s_t,a_t)] η(π~)=η(π)+Es0,a0,…∼π~[t=0∑∞γtAπ(st,at)]
η ( π ) = E s 0 , a 0 , … [ ∑ t = 0 ∞ γ t r ( s t ) ] = E [ V π ( s 0 ) ] \eta(\pi) = \mathbb{E}_{s_0, a_0,\ldots}[\sum\limits_{t=0}^{\infty}\gamma^t r(s_t)] = \mathbb{E}[V_\pi(s_0)] η(π)=Es0,a0,…[t=0∑∞γtr(st)]=E[Vπ(s0)]
E s 0 , a 0 , … ∼ π ~ [ ∑ t = 0 ∞ γ t A π ( s t , a t ) ] = E s 0 , a 0 , … ∼ π ~ [ ∑ t = 0 ∞ γ t ( Q π ( s t , a t ) − V π ( s t ) ) ] = E s 0 , a 0 , … ∼ π ~ [ ∑ t = 0 ∞ γ t ( r ( s t ) + γ V π ( s t + 1 ) − V π ( s t ) ) ] = E s 0 , a 0 , … ∼ π ~ [ − V π ( s 0 ) + ∑ t = 0 ∞ γ t r ( s t ) ] = − E s 0 [ V π ( s 0 ) ] + E s 0 , a 0 , … ∼ π ~ [ ∑ t = 0 ∞ γ t r ( s t ) ] = − η ( π ) + η ( π ~ ) \begin{aligned} \mathbb{E}_{s_0,a_0,\ldots\sim\tilde{\pi}}[\sum\limits_{t=0}^\infty\gamma^t A_\pi(s_t,a_t)] &=\mathbb{E}_{s_0,a_0,\ldots\sim\tilde{\pi}}[\sum\limits_{t=0}^\infty\gamma^t(Q_\pi(s_t,a_t)-V_\pi (s_t))]\\ &=\mathbb{E}_{s_0,a_0,\ldots\sim\tilde{\pi}}[\sum\limits_{t=0}^\infty\gamma^t(r(s_t)+\gamma V_\pi (s_{t+1})-V_\pi (s_t))]\\ &=\mathbb{E}_{s_0,a_0,\ldots\sim\tilde{\pi}}[-V_\pi(s_0) + \sum\limits_{t=0}^\infty\gamma^t r(s_t)]\\ &=-\mathbb{E}_{s_0}[V_\pi(s_0)] + \mathbb{E}_{s_0,a_0,\ldots\sim\tilde{\pi}}[\sum\limits_{t=0}^\infty\gamma^t r(s_t)]\\ &=-\eta(\pi) + \eta(\tilde{\pi}) \end{aligned} Es0,a0,…∼π~[t=0∑∞γtAπ(st,at)]=Es0,a0,…∼π~[t=0∑∞γt(Qπ(st,at)−Vπ(st))]=Es0,a0,…∼π~[t=0∑∞γt(r(st)+γVπ(st+1)−Vπ(st))]=Es0,a0,…∼π~[−Vπ(s0)+t=0∑∞γtr(st)]=−Es0[Vπ(s0)]+Es0,a0,…∼π~[t=0∑∞γtr(st)]=−η(π)+η(π~)
4.2 证明: η ( π ~ ) = η ( π ) + ∑ s ρ π ~ ( s ) ∑ a π ~ ( a ∣ s ) A π ( s , a ) \eta(\tilde{\pi}) =\eta(\pi) + \sum\limits_s\rho_{\tilde{\pi}}(s)\sum\limits_a\tilde{\pi}(a|s)A_{\pi}(s,a) η(π~)=η(π)+s∑ρπ~(s)a∑π~(a∣s)Aπ(s,a)
η ( π ~ ) = η ( π ) + E s 0 , a 0 , … ∼ π ~ [ ∑ t = 0 ∞ γ t A π ( s t , a t ) ] = η ( π ) + ∑ t = 0 ∞ ∑ s P ( s t = s ∣ π ~ ) ∑ a π ~ ( a ∣ s ) γ t A π ( s , a ) = η ( π ) + ∑ s ∑ t = 0 ∞ γ t P ( s t = s ∣ π ~ ) ∑ a π ~ ( a ∣ s ) A π ( s , a ) = η ( π ) + ∑ s ρ π ~ ( s ) ∑ a π ~ ( a ∣ s ) A π ( s , a ) \begin{aligned} \eta(\tilde{\pi}) &= \eta(\pi) + \mathbb{E}_{s_0,a_0,\ldots\sim\tilde{\pi}}[\sum\limits_{t=0}^\infty \gamma^t A_{\pi}(s_t,a_t)]\\ &=\eta(\pi) + \sum\limits_{t=0}^\infty\sum\limits_sP(s_t=s|\tilde{\pi})\sum\limits_a\tilde{\pi}(a|s)\gamma^tA_\pi(s,a)\\ &=\eta(\pi) + \sum\limits_s\sum\limits_{t=0}^\infty\gamma^tP(s_t=s|\tilde{\pi})\sum\limits_a\tilde{\pi}(a|s)A_\pi(s,a)\\ &=\eta(\pi) + \sum\limits_s\rho_{\tilde{\pi}}(s)\sum\limits_a\tilde{\pi}(a|s)A_{\pi}(s,a) \end{aligned} η(π~)=η(π)+Es0,a0,…∼π~[t=0∑∞γtAπ(st,at)]=η(π)+t=0∑∞s∑P(st=s∣π~)a∑π~(a∣s)γtAπ(s,a)=η(π)+s∑t=0∑∞γtP(st=s∣π~)a∑π~(a∣s)Aπ(s,a)=η(π)+s∑ρπ~(s)a∑π~(a∣s)Aπ(s,a)
4.3 证明:
{ L π θ 0 ( π θ 0 ) = η ( π θ 0 ) ∇ θ L π θ 0 ( π θ ) ∣ θ = θ 0 = ∇ θ η ( π θ ) ∣ θ = θ 0 \left\{ \begin{aligned} L_{\pi_{\theta_0}}(\pi_{\theta_0})& = \eta(\pi_{\theta_0})\\ \nabla_{\theta}L_{\pi_{\theta_0}}(\pi_\theta)|_{\theta=\theta_0}& = \nabla_\theta\eta(\pi_\theta)|_{\theta=\theta_0}\\ \end{aligned} \right. { Lπθ0(πθ0)∇θLπθ0(πθ)∣θ=θ0=η(πθ0)=∇θη(πθ)∣θ=θ0
L π ( π ~ ) = η ( π ) + ∑ s ρ π ( s ) ∑ a π ~ ( a ∣ s ) A π ( s , a ) L_\pi(\tilde{\pi}) = \eta(\pi) + \sum\limits_s\rho_\pi(s)\sum\limits_a\tilde{\pi}(a|s)A_\pi(s,a) Lπ(π~)=η(π)+s∑ρπ(s)a∑π~(a∣s)Aπ(s,a)
当 π ~ = π \tilde{\pi} = \pi π~=π时:
L π ( π ) = η ( π ) + ∑ s ρ π ( s ) ∑ a π ~ ( a ∣ s ) A π ( s , a ) L_\pi(\pi) = \eta(\pi) + \sum\limits_s\rho_\pi(s)\sum\limits_a\tilde{\pi}(a|s)A_\pi(s,a) Lπ(π)=η(π)+s∑ρπ(s)a∑π~(a∣s)Aπ(s,a)
对于每一个 s s s有
∑ a π ( a ∣ s ) A π ( s , a ) = E a [ A π ( s , a ) ] = E a [ Q π ( s , a ) − V π ( s ) ] = E a [ Q π ( s , a ) − E a [ Q π ( s , a ) ] ] = E [ Q π ( s , a ) ] − E a [ E a [ Q π ( s , a ) ] ] = E [ Q π ( s , a ) ] − E [ Q π ( s , a ) ] = 0 \begin{aligned} &\sum\limits_a\pi(a|s)A_\pi(s,a)\\ =&\mathbb{E}_a[A_\pi(s,a)]\\ =&\mathbb{E}_a[Q_\pi(s,a) - V_\pi(s)]\\ =&\mathbb{E}_a[Q_\pi(s,a) - \mathbb{E}_a[Q_\pi(s,a)]]\\ =&\mathbb{E}[Q_\pi(s,a)] - \mathbb{E}_a[\mathbb{E}_a[Q_\pi(s,a)]]\\ =&\mathbb{E}[Q_\pi(s,a)] - \mathbb{E}[Q_\pi(s,a)]\\ =& 0 \end{aligned} ======a∑π(a∣s)Aπ(s,a)Ea[Aπ(s,a)]Ea[Qπ(s,a)−Vπ(s)]Ea[Qπ(s,a)−Ea[Qπ(s,a)]]E[Qπ(s,a)]−Ea[Ea[Qπ(s,a)]]E[Qπ(s,a)]−E[Qπ(s,a)]0
上述推导过程中第五行到第六行的推导过程中的 E a [ E a [ Q π ( s , a ) ] ] \mathbb{E}_a[\mathbb{E}_a[Q_\pi(s,a)]] Ea[Ea[Qπ(s,a)]] = E a [ Q π ( s , a ) ] \mathbb{E}_a[Q_\pi(s,a)] Ea[Qπ(s,a)] 是因为期望的期望等于期望,从另一个角度来看这个等式, E a [ Q π ( s , a ) ] \mathbb{E}_a[Q_\pi(s,a)] Ea[Qπ(s,a)]的结果与a无关,相当于一个常数,所以再对a求期望的话,相当于对常数求期望,等于常数本身。
再证明公式 ( 3.4 ) (3.4) (3.4)的第二个等式: ∇ θ L π θ 0 ( π θ ) ∣ θ = θ 0 = ∇ θ η ( π θ ) ∣ θ = θ 0 \nabla_{\theta}L_{\pi_{\theta_0}}(\pi_\theta)|_{\theta=\theta_0} = \nabla_\theta\eta(\pi_\theta)|_{\theta=\theta_0} ∇θLπθ0(πθ)∣θ=θ0=∇θη(πθ)∣θ=θ0
我们有: L π θ 0 ( π θ ) = η ( π θ 0 ) + ∑ s ρ π θ 0 ( s ) ∑ a π θ ( a ∣ s ) A π θ 0 ( s , a ) L_{\pi_{\theta_0}}(\pi_\theta) = \eta(\pi_{\theta_0}) + \sum\limits_s\rho_{\pi_{\theta_0}}(s)\sum\limits_a\pi_\theta(a|s)A_{\pi_{\theta_0}}(s,a) Lπθ0(πθ)=η(πθ0)+s∑ρπθ0(s)a∑πθ(a∣s)Aπθ0(s,a)
两边对 θ \theta θ求导(注意任何和 θ 0 \theta_0 θ0有关的式子在对 θ \theta θ求导的时候都视为常数)得:
∇ θ L π θ 0 ( π θ ) = ∑ s ρ π θ 0 ( s ) ∑ a ∇ θ π θ ( a ∣ s ) A π θ 0 ( s , a ) \nabla_\theta L_{\pi_{\theta_0}}(\pi_\theta) = \sum\limits_s\rho_{\pi_{\theta_0}}(s)\sum\limits_a\nabla_\theta\pi_\theta(a|s)A_{\pi_{\theta_0}}(s,a) ∇θLπθ0(πθ)=s∑ρπθ0(s)a∑∇θπθ(a∣s)Aπθ0(s,a)
进而成立:
∇ θ L π θ 0 ( π θ ) ∣ θ = θ 0 = ∑ s ρ π θ 0 ( s ) ∑ a ∇ θ π θ ( a ∣ s ) ∣ θ = θ 0 A π θ 0 ( s , a ) \nabla_\theta L_{\pi_{\theta_0}}(\pi_\theta)|\theta = \theta_0 = \sum\limits_s\rho_{\pi_{\theta_0}}(s)\sum\limits_a\nabla_\theta\pi_\theta(a|s)|_{\theta = \theta_0}A_{\pi_{\theta_0}}(s,a) ∇θLπθ0(πθ)∣θ=θ0=s∑ρπθ0(s)a∑∇θπθ(a∣s)∣θ=θ0Aπθ0(s,a)
由论文[2]可知:
∇ θ η ( π θ ) = ∑ s ρ π θ ( s ) ∑ a ∇ θ π θ ( a ∣ s ) Q π θ ( s , a ) \nabla_\theta\eta(\pi_\theta) = \sum\limits_s\rho_{\pi_\theta}(s)\sum\limits_a\nabla_\theta\pi_\theta(a|s)Q_{\pi_\theta}(s,a) ∇θη(πθ)=s∑ρπθ(s)a∑∇θπθ(a∣s)Qπθ(s,a)
又因为
∑ s ρ π θ ( s ) ∑ a ∇ θ π θ ( a ∣ s ) V π θ ( s ) = ∑ s ρ π θ ( s ) V π θ ( s ) ∑ a ∇ θ π θ ( a ∣ s ) = ∑ s ρ π θ ( s ) V π θ ( s ) ∇ θ ∑ a π θ ( a ∣ s ) = 0 \begin{aligned} &\sum\limits_s\rho_{\pi_\theta}(s)\sum\limits_a\nabla_\theta\pi_\theta(a|s)V_{\pi_\theta}(s)\\ =&\sum\limits_s\rho_{\pi_\theta}(s)V_{\pi_\theta}(s)\sum\limits_a\nabla_\theta\pi_\theta(a|s)\\ =&\sum\limits_s\rho_{\pi_\theta}(s)V_{\pi_\theta}(s)\nabla_\theta\sum\limits_a\pi_\theta(a|s)\\ =&0 \end{aligned} ===s∑ρπθ(s)a∑∇θπθ(a∣s)Vπθ(s)s∑ρπθ(s)Vπθ(s)a∑∇θπθ(a∣s)s∑ρπθ(s)Vπθ(s)∇θa∑πθ(a∣s)0
上述推导过程中第一行到第二行是因为 V π θ ( s ) V_{\pi_\theta}(s) Vπθ(s)与 a a a无关,所以可以提到 ∑ a \sum\limits_a a∑的前面。第二个式子到第三个式子是因为求和的导数等于导数的求和。第三个式子到第四个式子是因为对于每个 s s s来说都成立: ∑ a π θ ( a ∣ s ) = 1 \sum\limits_a\pi_\theta(a|s)=1 a∑πθ(a∣s)=1,然后1对 θ \theta θ求导等于0,即 ∇ θ ∑ a π θ ( a ∣ s ) = ∇ θ 1 = 0 \nabla_\theta\sum\limits_a\pi_\theta(a|s) = \nabla_\theta1 = 0 ∇θa∑πθ(a∣s)=∇θ1=0。
所以可得:
∇ θ η ( π θ ) = ∑ s ρ π θ ( s ) ∇ θ π ( a ∣ s ) Q π ( s , a ) = ∑ s ρ π θ ( s ) ∇ θ π θ ( a ∣ s ) [ Q π ( s , a ) − V π ( s ) ] = ∑ s ρ π θ ( s ) ∇ θ π θ ( a ∣ s ) A π θ ( s , a ) \begin{aligned} \nabla_\theta\eta(\pi_\theta)&=\sum\limits_s\rho_{\pi_\theta}(s)\nabla_\theta\pi(a|s)Q_\pi(s,a)\\ &=\sum\limits_s\rho_{\pi_\theta}(s)\nabla_\theta\pi_\theta(a|s)[Q_\pi(s,a) - V_\pi(s)]\\ &=\sum\limits_s\rho_{\pi_\theta}(s)\nabla_\theta\pi_\theta(a|s)A_{\pi_\theta}(s,a) \end{aligned} ∇θη(πθ)=s∑ρπθ(s)∇θπ(a∣s)Qπ(s,a)=s∑ρπθ(s)∇θπθ(a∣s)[Qπ(s,a)−Vπ(s)]=s∑ρπθ(s)∇θπθ(a∣s)Aπθ(s,a)
进而成立:
∇ θ η ( π θ ) ∣ θ = θ 0 = ∑ s ρ π θ 0 ( s ) ∇ θ π θ ( a ∣ s ) ∣ θ = θ 0 A π θ 0 ( s , a ) = ∇ θ L π θ 0 ( π θ ) ∣ θ = θ 0 \begin{aligned} \nabla_\theta\eta(\pi_\theta)|_{\theta = \theta_0}&=\sum\limits_s\rho_{\pi_{\theta_0}}(s)\nabla_{\theta}\pi_\theta(a|s)|_{\theta = \theta_0}A_{\pi_{\theta_0}}(s,a) = \nabla_\theta L_{\pi_{\theta_0}}(\pi_\theta)|_{\theta=\theta_0} \end{aligned} ∇θη(πθ)∣θ=θ0=s∑ρπθ0(s)∇θπθ(a∣s)∣θ=θ0Aπθ0(s,a)=∇θLπθ0(πθ)∣θ=θ0
命题得证。
我们是行者AI,我们在“AI+游戏”中不断前行。
前往公众号 【行者AI】,和我们一起探讨技术问题吧!
边栏推荐
- 【哲理】事教人
- selenium和驱动安装
- AppUser object extension based on ABP
- 下载markdown软件Obsidian(解决官网下载速度慢)
- YOLOV5 study notes (7) - training your own data set
- 70. Stair Climbing Advanced Edition
- Gold Warehouse Database KingbaseGIS User Manual (6.2. Management Functions)
- Has your phone ever been monitored?
- 分布式数据库难题(二):数据复制
- Gumbel distribution of discrete choice model
猜你喜欢
工程 (七) ——PolarSeg点云语义分割
![[Interface Test] Decoding the request body string of the requests library](/img/99/82ef792dacd398a8a62dd94f235a91.png)
[Interface Test] Decoding the request body string of the requests library

A summary of 6 common tools for cross-border e-commerce
Alibaba Cloud SMS Service Activation
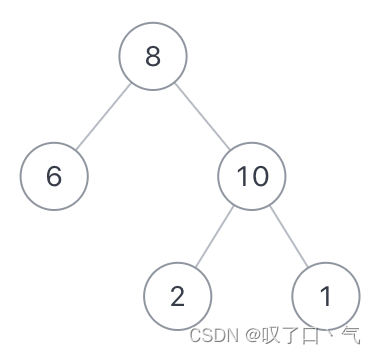
【JZOF】32从上往下打印二叉树
【渗透工具】浏览器数据导出工具
selenium和驱动安装

Service Discovery @EnableDiscoveryClient

【集训DAY3】中位数
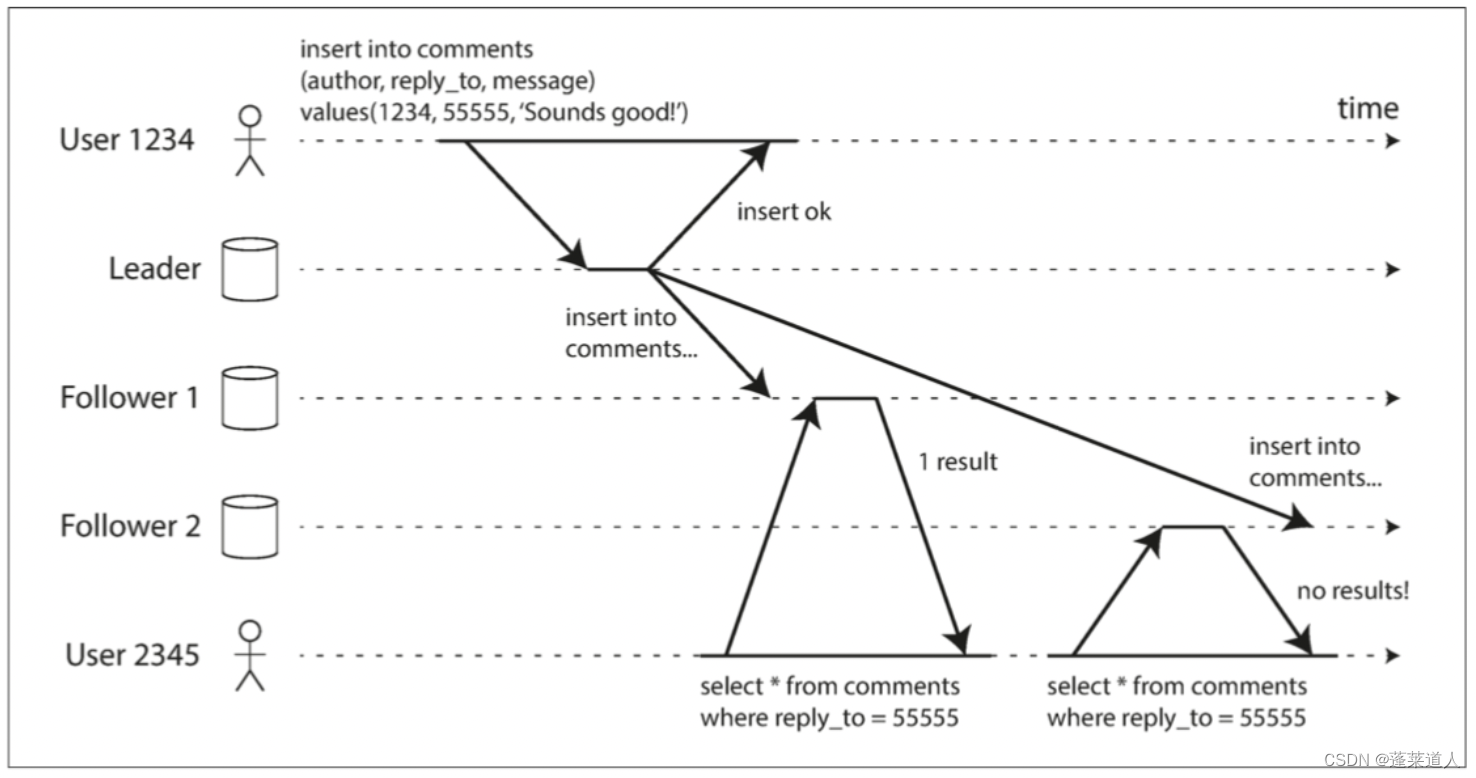
Distributed database problem (3): data consistency
随机推荐
Force buckle: 279. Perfect square
Technology feast!Huayun Data brings six topics to OpenInfra Days China
68. qt quick-qml multi-level folding drop-down navigation menu supports dynamic add/unload, support qml/widget loading, etc.
ES6 Beginner to Mastery #13: Extension Methods for Arrays 2
Click: 377. Combined Sum Ⅳ
[JZOF] 82 binary tree with a path of a certain value (1)
数字钱包红海角逐,小程序生态快速引入可助力占领智慧设备入口
61.【快速排序法详解】
Distributed database problem (2): data replication
分布式数据库难题(二):数据复制
Golden Warehouse Database KingbaseGIS User Manual (6.6. Geometric Object Verification Function, 6.7. Spatial Reference System Function)
【JZOF】32从上往下打印二叉树
了解什么是架构基本概念和架构本质
Gartner全球集成系统市场数据追踪,超融合市场增速第一
软考 --- 软件工程(7)软件项目管理(下)
LiveData : Transformations.map and Transformations.switchMap usage
Pinduoduo store operation must know to leave a little knowledge of operation
Explore the TiDB Lightning source code to solve the found bugs
Distributed database problem (3): data consistency
Digital wallets, red sea ecological rapid introduction of small programs can help capture device entry wisdom