当前位置:网站首页>数据仓库建模实践
数据仓库建模实践
2022-08-10 03:12:00 【Thoughtworks思特沃克中国】
前面的文章中我们讲到了数据仓库。我们都知道,仓库的一般意义是指一个特别大的是用于存放各种物品的库房,所以,数据仓库常常可以给人一个很直观的理解,就是一个可以存放各种数据的大的存储。
在建设数据仓库时,我们常常要对数据进行分层,比如常见分层方式:ODS层->DWD层->DWB层->DM层->ADS层。
数据仓库建模通常是指DWD层的建模,因为DWD是数据仓库中使用最广泛的数据分层,我们需要尽可能保证这一层的易用性。DWD层的模型很大程度上影响了一个数据仓库项目甚至数据平台项目的成败。本文将针对DWD层数据建模分享一下我们在项目上的实践经验。
数据仓库基本特征
开始之前,我们先来了解一下数据仓库的特征。
数据仓库的相关概念最早是由 W. H. Inmon 于90年代提出来的,Inmon也因此被大家认为是数据仓库之父。在Inmon的数据仓库理念里,数据仓库是一个面向主题的(Subject Oriented)、集成的(Integrate)、非易失(Non-Volatile)且时变(Time Variant)的数据集,用于支持管理决策。
面向主题、集成、非易失且时变是数据仓库的四个基本特征。其中,面向主题可以认为是一种面向分析的数据分类和映射;集成的是指将不同的数据源的数据集合到一起以便于分析;非易失可以理解为稳定,是指进入数据仓库的数据不会发生修改;时变是指数据仓库的数据需要保留历史,以便于任何时候回头对数据进行分析。
数据仓库主键
时变这个特征对数据仓库建模提出了最基本的技术上的要求,我们的数据模型要如何建立才可以保留所有历史数据呢?Inmon在《数据仓库》这本书里面提出了一些新的概念,可以帮助我们实现时变这个特点。
首先,每一张数据库表都应当有一个主键,它可以唯一标识一条数据,以便支持数据的查找、更新、关联。这是当前业务系统数据库模型设计的一个基本指导原则。很多数据库设计指导甚至会建议为所有表设计一个自增且无业务含义的字段作为主键。唯一字段主键为数据查询及关联提供了很大的方便。
实际操作中,我们可以认为业务系统的所有数据库表中均存在一个主键,如果没有单一字段主键,也应该有多个字段可以组合成为一个主键。多个字段形成的主键在数据库设计中被称为复合主键。
我们可以向业务系统数据库设计人员了解主键字段是哪些,也可以通过基本的数据分析找出主键(比如,观察表中的非空字段可以辅助发现主键字段)。其实,就算业务系统数据库设计人员告知了我们哪些字段是主键,本着怀疑的态度,我们也应该要从数据层面进行主键验证。通常我们可以通过执行SQL来验证主键,对比多字段唯一计数(count(distinct concat(col1, col2)))和数据库数据总行数(count(*))的值,如果两者相等,则这些字段可以作为主键字段。
保存数据历史其实就是根据数据主键进行保存,历史数据将包含每一个主键(每一条条数据)对应的所有的变更。
如果我们直接将所有历史数据存储到一张表里面(保持与业务系统表字段一致),那么数据库仓库中的表的主键就将变得模糊不清,不便于使用,(这是ods层的数据情况,所以一般不建议直接从ods取数使用)。一般而言,我们会为数据仓库的表额外设计一个唯一字段主键。为了区分原表的主键和数据仓库新引入的主键,我们可以给它们换个名字。通常,原表的主键被称为业务键、业务主键或自然键,数据仓库新引入的主键被称为代理键或数据仓库主键(下文称业务键和代理键)。
数据仓库外键
有了数据仓库代理键,单表的历史数据保存问题就解决了。除了单表历史数据问题,我们常常还需要解决表间关联的历史数据问题。
比如,在电商的场景下,昨天某店铺以100元卖出了一款产品,由于市场变化,今天需要调整产品价格为120,此时,当我们查询昨天的那笔订单时,应该需要能找到昨天对应的价格。由于产品价格和订单常常存储于不同的表中,这就形成了典型的表间关联的历史数据查询问题。
也有的文章将这种历史数据称作数据快照。比如,典型的情况是对每天的数据生成一个快照。
如何解决表间关联的历史数据问题呢?还是可以基于代理键来实现。只需要实现一个转换逻辑,将原来的每张数据库表的外键转换为代理键即可。
代理键设计
如何来设计数据仓库代理键呢?传统的数据库设计理论会建议我们使用一个与业务无关的自增值作为代理主键。但是,在当下流行的基于分布式计算的数据仓库技术下,如果使用自增键,我们将遇到很多技术挑战。比如:
- 需要预先查询当前最大主键值
- 分布式环境下生成主键,需要在各个计算节点进行任务协调,导致速度变慢
- 除非预先指定非常严格的数据排序,否则重复计算将生成不同的主键,计算任务也就无法实现幂等(数据任务的幂等性是指,对同样的输入,任务每次运行都产生一个同样的输出。数据项目中的任务幂等性非常重要,试想,如果每次生成的主键不一样,那么当主键重新生成时,上层所有依赖任务需要重新计算。这将带来大量的额外计算,大大降低效率。)
对于传统关系型数据库而言,自增主键带来的优势主要是占用存储空间低和计算速度快,但在分布式数据存储和计算的前提下,这个优势其实并不明显。
基于Hive的数据仓库支持多种类型的存储格式,我们常见的如ORC或Parquet格式都是列式存储并支持压缩的。 对于文本类重复率较高的数据常常可以有很高的压缩率,从而缓解存储空间占用大的问题。同时,由于分布式计算的存在,字符串比较产生的性能损失也显得不那么明显。
我们曾经做过一个测试,先随机生成一个长整型数据,然后计算其md5值,接着比较两者的存储空间和表连接效率,发现结果相差无几。(见文末测试报告)
所以,结合我们的实践经验,我们建议数据仓库代理键使用以下方式生成。
- 找出业务键对应的字段(可能是多个);
- 找出数据更新时间字段,如果是全量表,可使用接入数据的日期;
- 将业务键字段及数据变更时间字段计算哈希值生成代理键;
对应的sql表达式示例:
sha1(concat(sha1(business_pk1), sha1(business_pk2), sha1(update_time)))。
使用这种方式生成的代理键可以很好的解决任务幂等性问题,并且不会有太大的性能损失。
有了任务幂等性,我们就可以更从容的应对DWD层的修改。这样的修改可能比想象的更频繁,比如:
- 业务系统数据库引入了一个新的字段,需要在DWD层模型中新增这个字段进行分析
- 由于对业务数据理解出现问题,或者业务系统提供的数据编码值不对,或者业务系统数据库编码值改变等情况,原来的DWD层中的数据清洗或转换规则需要更新
对于上述更新,我们就无需重新运行所有上层计算任务了,只运行依赖这个变更字段的任务即可。
重新建模
很多时候,我们一讲数据仓库或数据平台,几乎马上就可以让人想到维度建模。维度建模在数据仓库建设中的重要性可想而知(这里的维度建模通常就是指dwd层的建模)。
但是,如果我们看下维度建模的发展就知道,维度建模是早在1996时由Ralph Kimball首次提出来的。在当下的技术环境下来看,维度建模的理论还是有效的吗?有哪些到现在还是好的实践,哪些应该摒弃呢?
维度建模的目的是为了更好的进行数据分析。维度建模的理论将数据表分为事实表和维度表。大部分的数据分析将从事实表出发,关联到维度表,再进行统计。这一理论揭示了数据分析的规律性,不仅使得数据分析实施起来更有章法,还给相关的技术工具的设计提供了理论支持。
但是,一旦我们将维度建模的理论应用于实际项目,我们常常很快就会陷入困境。因为维度和事实其实不那么容易区分,它们常常是相对的概念。比如,订单看起来是一个事实,而其关联的产品应该属于维度。但是,一般情况下,一笔订单下会存在多个商品,如果我们对订单下的某一个商品进行分析,此时是不是该商品变成了事实,而订单则是该事实的关联维度?
所以,维度模型为了完善其对于数据分析的抽象,还引入了很多相关的较为复杂的概念。比如桥接表等。这些相关概念的引入给数据分析带来了更多的学习成本,对于维度模型理论的推广带来了阻力。
另一方面,越来越多业务人员正在成为数据分析师(大部分数据分析只需要sql就可以实现,所以,简单的数据分析是可以由业务人员自己完成的,这是更高效的做法,同时也是业界正在推进的实践)。这样一来,维度建模的复杂性就更难接受了,因为我们不应该要求业务人员先去学习复杂的维度建模再来进行数据分析。
从技术上看,由于都是基于关系型数据库,其实,维度建模得到的模型与三范式模型并无太大区别,几乎可以一一对应起来。在上一篇文章中,我们建议在对数据理解不深的时候,不要进行重新建模和模型映射。在这里,我们有相同的结论,即,不建议进行复杂的维度模型建模,而是简单的将业务系统数据库中的三范式模型数据表进行事实维度标记。这样得到的数据表与三范式数据表相比,可能只是表名不一样,称为维度模型似乎不太相称,我们可以称其为简单维度模型。
建立简单维度模型只需要花费很少的时间,这避免了前期进行过重的复杂的设计,是一种更为精益的做法。
码值映射
为了更好的进行数据分析,我们希望数据分析时可以更容易的获取和理解数据。这对于数据字段提出了一些要求,一个典型的问题就是码值问题。
什么是码值呢?举个例子,从业务系统数据库设计的视角来看,为了提升性能常常会选用占用存储空间更少的字段类型进行数据存储,于是一些通常只有几个取值的状态值字段,如订单状态,就会使用tinyint这样的单字节字段类型进行存储。此时,状态值会被映射为数字进行存储,如1代表已创建,2代表交易成功等。我们常常把这里的数字称为码,而其对应的值称为值。
这里的码值问题就是说,在数据分析时,我们无法直接从数据中知道某一个码对应的是什么值,常常需要进行一层码值转换才能知道。这对于数据分析显然是不友好的,要么取数据逻辑更复杂,要么数据分析师需要在头脑里面记住这个码值映射关系。
一些二值字段同样可以从这样的实践中获益,一般而言,我们可以将二值字段映射为严格的true false值,从而避免潜在的null值,使得DWD层的数据更为规范好用。
所以,在DWD层解决这个问题将带来很高的价值。
出于性能考虑,传统的数据仓库建模理论可能会建议我们将这些码值映射保存到一张单独的码表中,但此时查询的便利性还是较差。
由于列式压缩存储可以很好的缓解性能问题,我们建议在DWD层对于所有码值进行解码操作,通过添加一些列,将原有的数字映射为真实的值进行保存。
原值保存
在进行数据清洗时,我们会将一些字段处理为更规范的字段。为了进一步提高DWD层的灵活性,一个实用的建议是将原来的字段值保留下来。这样一来,即便我们数据清洗规则有问题,或者要新增数据清洗规则,在数据分析师进行数据分析时都有数据可用,不用等待DWD层重新构建。
对于上文提到的码值映射,我们就可以保留字段原值。在实践时,我们会将原来的字段重命名,添加一个original的前缀。其意义在于,我们不推荐使用原值字段(加一个前缀使字段名更长而不便于使用),但是我们保留使用字段原值的能力。
对于主键而言,如果业务系统表的主键由多个字段组成,我们建议通过对这些字段进行哈希生成一个单一字段主键,这将在表关联及数据访问时提供额外的灵活性。此时原来的主键也应保留下来供分析使用。
时间处理
时间是一个特殊的类型,很多数据分析都是基于时间来开展的。比如每天的销量,每月的销量,节假日客流量等。所以,我们常常把日期作为一个单独的维度表进行构建,该维表内会存储节假日、星期几时段等常用的分析维度信息。如果有对于时间的分析需求,也可以建立时间的维表,以便保存常见的早中晚等时段信息。
其他的表如何关联日期和时间呢?可以通过外键实现。所以,在数据表里面出现日期或时间字段时,可以根据该字段建立对应日期和时间维表外键。
由于日期和时间的取值非常固定,可以用一个整数来表示。比如,日期可以是8位整数,如20210101,类似的,时间可以表示为6位整数,如120101。所以,日期和时间维表常常用这样的整数来作为主键(此时也是代理键,因为日期和时间维表无需保留历史)。使用整数作为主键,可移植性和易用性可以得到一定程度的增强。
数据仓库建模总结
经过上面的讨论,我们可以得到这样一些数据仓库建模的经验:
- 代理键生成使用sha1和concat, 并注意处理null
- 外键列保留对应的业务键字段
- 做了码值转换的字段保留原字段,命名为original_{原字段}
- 处理date/time的字段,除了生成外键列,需要保留一个timestamp字段,方便后续使用
在实践过程中,我们把上述几条规则当做dwd层建模原则来对待。
有了这样的建模原则,dwd层的构建几乎可以完全自动化的完成。只需要我们开发一些数据工具进行辅助就可以了。在后面的文章中,我们将一起来看一下,这样的建模工具应该如何设计实现。
附录
文本字段和数值型字段对比测试
运行以下sql可以测试文本类型字段和整数型字段的存储空间占用及关联查询性能。
-- 生成1000,000条数据,其中有1000个不同的值,进行md5编码后存储起来
create table test.test_join stored as Parquet TBLPROPERTIES ("transactional" = "false") as
with rand_list_ as (
select t.f1,t.start_r - pe.i as seq_no from (
select 'ABC' as f1, 1000000 as start_r, 0 as end_r
) t lateral view posexplode(split(space(start_r - end_r - 1),'')) pe as i,s
),
rand_list as (
SELECT
cast(rand() * 10 as INTEGER) * 100 + cast(rand() * 10 as INTEGER) * 10 + cast(rand() * 10 as INTEGER) as n,
seq_no as id
from rand_list_
)
select id, n, md5(cast(n as string)) sn from rand_list;
-- 将数值型字段和文本型字段分别写入到不同的表中,比较存储空间占用,可以发现均占用约1.2MB的空间
create table test.test_join_n stored as Parquet TBLPROPERTIES ("transactional" = "false") as select n from test.test_join;
create table test.test_join_s stored as Parquet TBLPROPERTIES ("transactional" = "false") as select sn from test.test_join;
-- 测试使用数值型字段进行关联和使用文本型字段进行关联,两者都在10秒左右完成
select count(1) from test.test_join j join test.test_join_n n on j.n=n.n;
select count(1) from test.test_join j join test.test_join_s s on j.sn=s.sn;
运行上述测试之后可以得到的结论是:
- 数值型字段和文本型字段的存储空间占用差异不大
- 数值型字段和文本型字段在表连接时性能差异不大
–
基于在多家企业多个项目的经验总结,我们沉淀出一套企业数据开发工作台,可以帮助团队高效交付数据需求,帮助企业快速构建数据能力,工作台地址:https://data-workbench.com/
我们开源了其中的核心模块–ETL开发语言,开源项目地址:https://github.com/easysql/easy_sql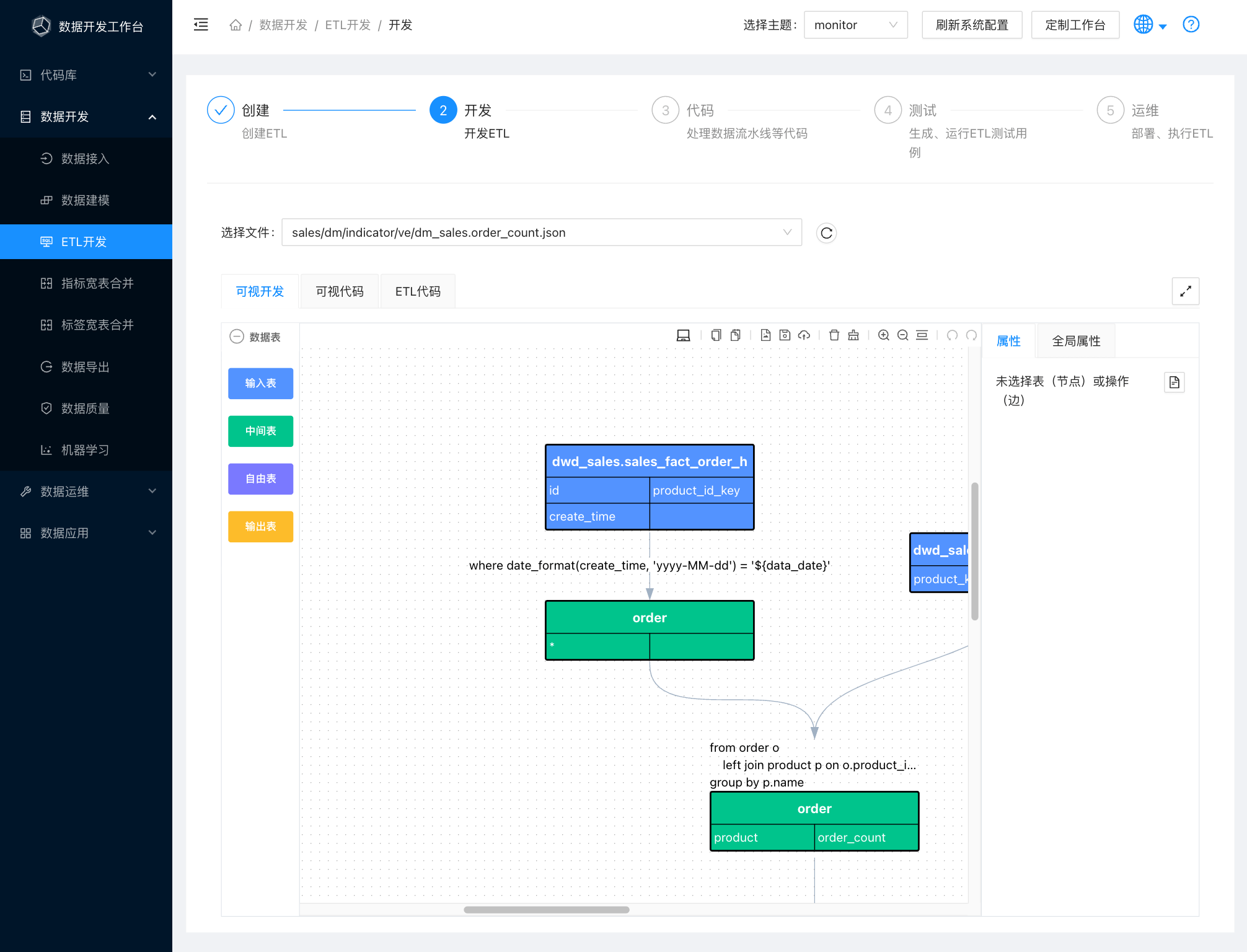
边栏推荐
猜你喜欢


随机推荐
Example 046: Breaking the Cycle
兴业数金一面
使用flink-sql写入mysql的时候,只指定插入的字段,但是会报错id字段错误,没有默认值,创
cuda——nms
嵌入式分享合集32
【CC3200AI 实验教程5】疯壳·AI语音人脸识别(会议记录仪/人脸打卡机)-定时器
Excel Advanced Drawing Skills 100 Lectures (23) - Countdown Counting in Excel
program internationalization
学习总结week4_2正则
WPF 实现更换主题色
三极管开关电路参数设计与参数介绍
proxy代理服务
如何快速成为一名软件测试工程师?测试员月薪15k需要什么技术?
黑马jvm课程笔记d2
Did not detect default resource location for test class xxxx
软件的生命周期(软件工程各阶段的工作)
nodejs 时钟案例(fs模块),重复使用fs.writeFile方法,旧内容会被覆盖
成功执行数字化转型的9个因素
关于redis在业务中的应用问题,如何解决?
Do you know these basic types of software testing?