当前位置:网站首页>学习总结week4_2正则
学习总结week4_2正则
2022-08-10 02:57:00 【非鱼丶丶】
python正则
正则表达式可以是一种让一些复杂的字符串问题变的简单的工具。
# 实例:判断指定字符串是否是一个合法的手机号
# 11位,都是数字,第一位必须是1,第二位必须是3~9
# 普通做法
tel = input()
def is_tel(num:str):
if len(tel) != 11:
return False
for x in num:
if not x.isdigit():
return False
if num[0] != 1:
return False
if '3' <= num[1] <= '9':
return True
return False
def is_tel2(num:str):
from re import fullmatch
return bool(fullmatch(r'1[3-9]\d{9}', num))
一、什么是正则表达式
正则表达式是一种可以让赋值的 字符串 问题变的简单的一种工具
正则并不是python特有的语法(不属于python),所有的高级编程语言都支持正则,正则的语法通用
不管通过正则表达式解决的是什么问题,写正则的时候都是在使用正则表达式描述字符串规则
1.python的re模块
from re import fullmatch
re模块时python用来支持正则表达式的一个模块,模块中包含了所有和正则相关的函数
fullmatch(正则表达式, 字符串) - 判断指定的正则表达式和指定的字符串是否完全匹配(判断整个字符串是否复合正则表达式所描述的规则)
如果匹配成功返回匹配对象,匹配失败返回None
2.正则语法 - 匹配类符号
普通符号 - 在正则表达式中表示符号本身的符号
res = fullmatch(r'abc', 'abc')
print(res)
# . - 匹配任意一个字符
res = fullmatch(r'a.c', 'abc')
print(res)
# \d - 匹配任意一个数字字符
res = fullmatch(r'a\dc', 'a8c')
print(res)
# \s - 匹配任意一个空白字符:空格、换行、水平制表符
res = fullmatch(r'a\s\sc', 'a c')
print(res)
# \D - 匹配任意一个非数字字符(\D\d,大小写对应的意义相反)
res = fullmatch(r'a\Dc', 'aDc')
print(res)
# \S - 匹配任意一个非空白字符
res = fullmatch(r'a\S\Sc', 'assc')
print(res)
# [^字符集] - 匹配不在字符集中的任意一个字符
res = fullmatch(r'ass[^mn]', 'assc')
print(res)
[字符集] - 匹配字符集中的任意一个字符
1.[mn12]多个符号写一起
2.[3-9] 3到9
3.[abc\d]abc或者任意数字
4.[a-z]任意小写字母
5.[a-zA-Z] - 匹配任意字母
6.[a-zA-Z\d_] - 字母数字下划线
7.[\u4e00-\u9fa5] - 匹配任意中文字符
8.[\d{n}] - 匹配n个前面表达式
注意:中括号中减号放在两个字符直接表示谁到谁(确定字符的方式是根据字符编码值大小确定的)
如果-不在两个字符之间,表示一个普通-
res = fullmatch(r'a[a-z]', 'am')
print(res)
3.匹配次数
*0次或者多次(任意次数)
注意:*在谁的后面控制的就是谁的次数
res = fullmatch(r'a*123', '123')
print(res)
res = fullmatch(r'\d*123', '575646545645123')
print(res)
# 2. + - 1次或者多次(至少1次)
res = fullmatch(r'a+123', 'a123')
print(res)
# 3. ? - 1次或者0次
res = fullmatch(r'a?123', 'a123')
print(res)
- {}
{M,N} - M到N次
{M,} - 至少M次
{,N} - 至多N次
{N} - N次
res = fullmatch(r'[a-z]{2,4}', 'ada')
print(res)
# 练习:写一个正则,判断输入的内容是否是一个合法的qq(长度5-12,第一不是0)
num = input()
res = fullmatch(r'[1-9]\d{4,11}', num)
# 练习:判断输入的内容是否是一个合法的标识符
# (由字母、数字下划线组成,数字不能开头)
num1 = input()
res1 = fullmatch(r'[a-zA-Z
4.贪婪和非贪婪
当匹配次数不确定的时候(*、+、?、{m,n}、{m,}、{,n}),分为贪婪和非贪婪,默认是贪婪的
贪婪和非贪婪:在匹配成功时有多种匹配结果, 贪婪取最多次数对应的匹配结果
匹配次数不确定的地方,有多种匹配方式都可以匹配成功,贪婪取最多次数,非贪婪取最少次数
贪婪模式:、+、?、{m,n}、{m,}、{,n}
非贪婪模式:?、+?、??、{m,n}?、{m,}?、{,n}?
注意:如果匹配结果只有一种可能,则两者一样
# match(正则表达式, 字符串)只匹配开头是否符合,后面不管
res = match(r'\d{3}', '2165165asd')
print(res)
res = match(r'a.+?b', 'a1231b151b5144b')
print(res)
5.分组 - ()
1)整体 - 将正则表达式中的一部分作为一个整体进行相关操作
2)重复 - 可以在正则表达式中通过\M来重复它前面的第M个分组的匹配结果
\M只能重复它前面出现的分组内容,无法重复在它之后出现的内容
3)捕获 - (分为手动捕获,自动捕获)只获取正则表达式中的一部分匹配到的结果
单独获取一个分组对象的结果
findall(获取字符串中所有满足正则表达式的子串)
res = fullmatch(r'(\d\d[A-Z]{2})+', '23DA23DA54GD56BF')
print(res)
res = fullmatch(r'(\d{2})[a-z]\1{2}', '12a1212')
print(res)
message = '达瓦大23挖到,芬恩5555555元,生啊180,提交70元,8元,'
res = findall(r'(\d+)元', message)
print(res)
6.分支 - |
正则1|正则2|正则3… - 匹配可以和多个正则中任意一个正则匹配的字符串
# 注意,如果想要正则表达式中一部分实现多选一的效果,变化的部分用分组表示
res = fullmatch(r'a(\d{3}|[a-z]{2})', 'all')
print(res)
7.转义符号
正则中的转义符号,就是在本身具备特殊功能或者特殊意义的符号前加’'让其表示一个普通字符
res = fullmatch(r'\d+\.\d+', '1325154')
print(res)
res = fullmatch(r'\([a-z]+\)', '(aad)')
print(res)
[ ]里面的转义符号
单独存在有特殊意义的符号(+、*、-、?、),在[]中的特殊意义会自动消失
res = fullmatch(r'[a\-z]', '-') # [az-]
print(res)
检测类符号 - 是在匹配成功的情况下检测检测类符号所在的位置是否符合相关要求(并不影响匹配)
# 1.\b - 检测是否是单词边界
# 单词边界:可以将两个单词区分开的符号都是(比如空白符号、标点符号、英文标点符号、字符串开头和结尾)
res = fullmatch(r'abc\b 123', 'abc 123')
print(res)
res = findall(r'\d+\b', '15 aw1dda5d153,aw1d5a1d5a1=wd')
print(res)
# 2.\B - 检测是否不是单词边界
message = '203mn45,89 司机34kn;23;99mll==910,230 90='
result = findall(r'\B\d+\B', message)
print(result)
# 3.^ - 检测是否是字符串开头
message = '203mn45,89 司机34kn;23;99mll==910,230 90='
result = findall(r'^\d+', message)
print(result)
# 4.$ - 检测是否是字符串结尾
# 提取字符串最后5个字符
message = '203mn45,89 司机34kn;23;99mll==910,230 90='
result = findall(r'.{5}$', message)
print(result)
8.re模块常用函数
1.fullmatch(正则表达式, 字符串) - 完全匹配,判断整个字符串是否符合正则表达式描述的规则,匹配成功返回匹配对象,匹配失败返回None
2.match(正则表达式, 字符串) - 匹配字符串开头,判断字符串开头是否符合正则表达式描述的规则,匹配成功返回匹配对象,匹配失败返回None
3.search(正则表达式, 字符串) - 获取字符串中第一个能够和正则匹配成功的子串,能找到返回匹配对象,找不到返回None
4.findall(正则表达式, 字符串) - 获取字符串中所有满足正则的子串,返回一个列表,列表中的元素是字符串。没有则空列表
注意:如果正则表达式中有分组,会对分组做自动捕获(只获取分组匹配到的结果)
5.finditer(正则表达式, 字符串) - 获取字符串中所有满足正则的子串,返回一个迭代器,迭代器中的元素是每个子串对应的匹配结果
6.split(正则表达式, 字符串) - 将字符串中所有满足正则的子串作为切割点,对字符串进行切割
7.sub(正则表达式, 字符串1, 字符串2) - 将字符串2中所有满足正则的子串都替换成字符串1
1)匹配对象
result = search(r'(\d{3})([A-Z]{2})', '-=2设计师234KM222哈哈宿舍239KH')
print(result) # <re.Match object; span=(6, 11), match='234KM'>
# 1)直接获取整个正则表达式对应的匹配结果:匹配对象.group()
print(result.group()) # '234KM'
# 2)手动捕获某个分组对应的匹配结果:匹配对象.group(分组数)
print(result.group(1)) # '234'
print(result.group(2)) # 'KM'
# 3)获取匹配结果在原字符串中的位置匹配对象.span()[0]
print(result.span()) # (6, 11)
print(result.span(2)) # (9, 11)
2)参数
# 1)匹配忽略大小写
res = fullmatch(r'(?i)abc', 'ABC')
print(res)
# 2)单行匹配(?s)
""" 多行匹配(默认):匹配的时候'.'不能和换行(\n)进行匹配 单行匹配:匹配的时候'.'可以和换行(\n)进行匹配 """
res = fullmatch(r'(?s)abc.123', 'abc\n123')
print(res)
边栏推荐
- 一个刚入行的测试员怎么样做好功能测试?测试思维真的很重要
- Software life cycle (the work of each phase of software engineering)
- 论文理解:“PIAT: Physics Informed Adversarial Training for Solving Partial Differential Equations“
- [Red Team] ATT&CK - Auto Start - Registry Run Key, Startup Folder
- goland控制台显示重叠问题解决方案
- excel高级绘图技巧100讲(二十三)-Excel中实现倒计时计数
- 单体架构应用和分布式架构应用的区别
- Instance 042: Variable scope
- Recommend several easy-to-use MySQL open source clients, it is recommended to collect
- 软件测试这些基本类型你知道吗?
猜你喜欢

How to quickly become a software test engineer?What skills do testers need for a monthly salary of 15k?

中国人保为德科康材承保产品责任险,为消费者权益保驾护航!
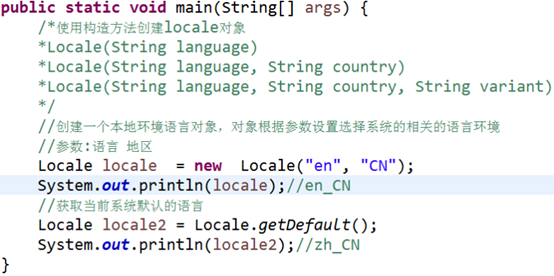
program internationalization

如何让导电滑环信号更好

How does a new tester do functional testing?Test thinking is really important
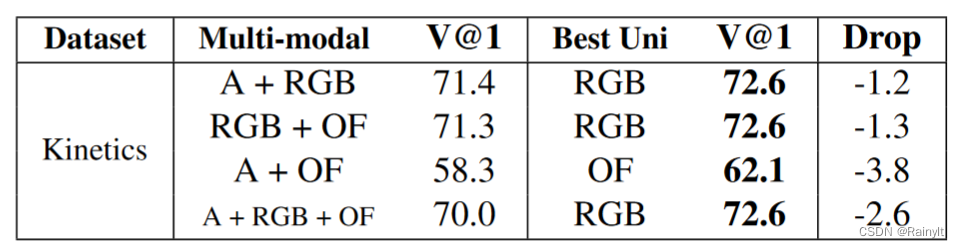
是什么让训练综合分类网络艰苦?
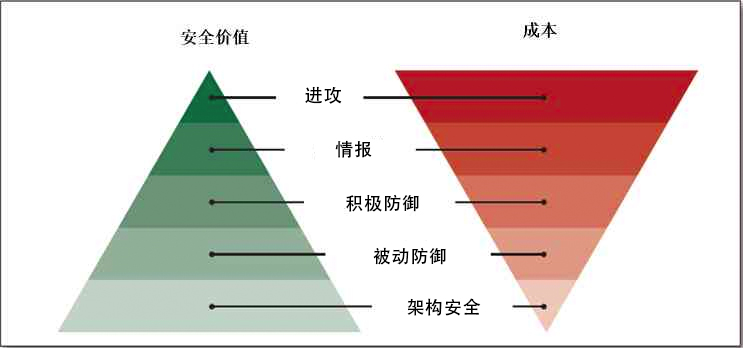
Evaluation and Construction of Enterprise Network Security Capability from the Sliding Ruler Model

Little rookie Hebei Unicom induction training essay
Example 044: Matrix Addition
驱动程序开发:无设备树和有设备树的platform驱动
随机推荐
维度表设计
Example 045: Summation
新零售社交电商APP系统平台如何打造公域+私域流量?
实例042:变量作用域
如何快速成为一名软件测试工程师?测试员月薪15k需要什么技术?
NFG电商系统在元宇宙趋势下做什么?
小程序分包及分包预下载
program internationalization
plsql 查询数据库操作历史记录(Ctrl + e)
想要避免After Effects渲染失败的问题,5个小技巧必看
高精度加法
一个刚入行的测试员怎么样做好功能测试?测试思维真的很重要
一文教会你快速上手 Vim
It's almost 35, still "did a little"?What happened to the test workers who had been in the industry for a few years?
Example 046: Breaking the Cycle
netstat和ss命令区别
cuda——nms
成功执行数字化转型的9个因素
清洁环保的小型风电滑环基本介绍
【CC3200AI 实验教程5】疯壳·AI语音人脸识别(会议记录仪/人脸打卡机)-定时器