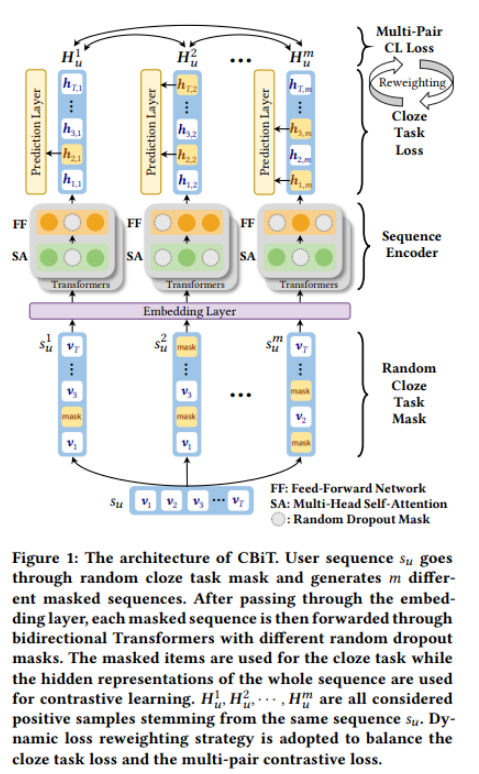
利用基于Transformer的序列编码器进行对比学习,在序列推荐方面取得了优势。它最大化了共享相似语义的成对序列扩充之间的一致性。然而,现有的序列推荐对比学习方法主要以左右单向Transformer为基础编码器,由于用户行为可能不是严格的从左到右的顺序,因此对于序列推荐来说,这种方法不是最优的。为了解决这个问题,我们提出了一种新的框架,名为对比学习与双向Transformer序列推荐(CBiT)。具体来说,我们首先在双向Transformer中对长用户序列应用滑动窗口技术,它允许对用户序列进行更细粒度的划分。然后我们结合完形填空任务掩码和dropout掩码生成高质量的正样本,进行多对对比学习,与普通的一对对比学习相比,表现出更好的性能和适应性。此外,我们还引入了一种新的动态损失加权策略来平衡完形任务损失和对比任务损失。在三个公共基准数据集上的实验结果表明,我们的模型在序列推荐方面优于最先进的模型。
论文链接:https://arxiv.org/pdf/2208.03895.pdf

![[Maui official version] Create a cross-platform Maui program, as well as the implementation and demonstration of dependency injection and MVVM two-way binding](/img/07/2baa3bd1d8da0f868fd49b5bdd0527.png)