当前位置:网站首页>12 Recurrent Neural Network RNN2 of Deep Learning
12 Recurrent Neural Network RNN2 of Deep Learning
2022-08-10 22:01:00 【water w】
本文是接着上一篇深度学习之 12 循环神经网络RNN_水w的博客-CSDN博客
目录
Why in the practical application,RNN很难处理长距离的依赖?
Gradient disappear, for example
Three methods to deal with gradient disappear question
更加推荐:ReLUFunction of the image and the derivative figure
逐步理解 LSTMUpdate the unit state of
堆叠循环神经网络 (Stacked Recurrent Neural Network, SRNN)
双向循环神经网络(Bidirectional Recurrent Neural Network)
回顾
需要寻优的参数有三个,分别是U、V、W.权重矩阵W和UThe optimization of process need to backThe historical data before(BPTT算法的重点).

1 长程依赖问题
RNN One advantage is that it can use the previous information on the current task,Especially when the relevant information and forecast the gap between the words is small effect.

However, in the interval when increasing,RNN 会丧失学习到连接如此远的信息的能力.

Why in the practical application,RNN很难处理长距离的依赖?
According to the following inequality,To obtain the upper bound of the die(模可以看做对 Every value in a largeThe measurement of small):

其中,𝛽𝑓、𝛽𝑊Respectively is a diagonal matrix and matrixW模的上界.
Gradient disappeared or gradient explosion causes gradient as0或NaN,Unable to continue training update parameters,也就是RNN的长程依赖问题.
Gradient disappear, for example

假设某轮训练中,各时刻的梯度以及最终的梯度之和如下图:

从t-3时刻开始,梯度已经几乎减少到0了.Before the beginning of a moment and then go,得到的梯度(几乎为零)Don't for theEnd of the gradient value any contribution.这就是原始RNNCan't handle long distanceAway from the dependence on the reason.
Three methods to deal with gradient disappear question
梯度消失更难检测,Also more difficult to deal with some.总的来说,There are three ways to deal with gradient disappear question:1. 合理的初始化权重值.初始化权重,Make each neuron as far as possible not to take maximum or minimum值,以躲开梯度消失的区域.2. 使用relu代替sigmoid和tanh作为激活函数.3. 使用其他结构的RNNs,比如长短时记忆网络(LTSM)和门控循环神经网络Gated Recurrent Unit(GRU).
sigmoid函数与tanh函数比较:
• sigmoidFunction derivative value in the range of(0,0.25],Back propagation will cause gradient disappear• tanhFunction derivative value in the range of (0,1],Relatively wide,But still can cause gradient disappear• sigmoidFunction is not the origin center symmetry,Output were greater than0• tanhFunction is the origin center symmetry,可以使网络收敛的更好
sigmoid函数的函数图和导数图:
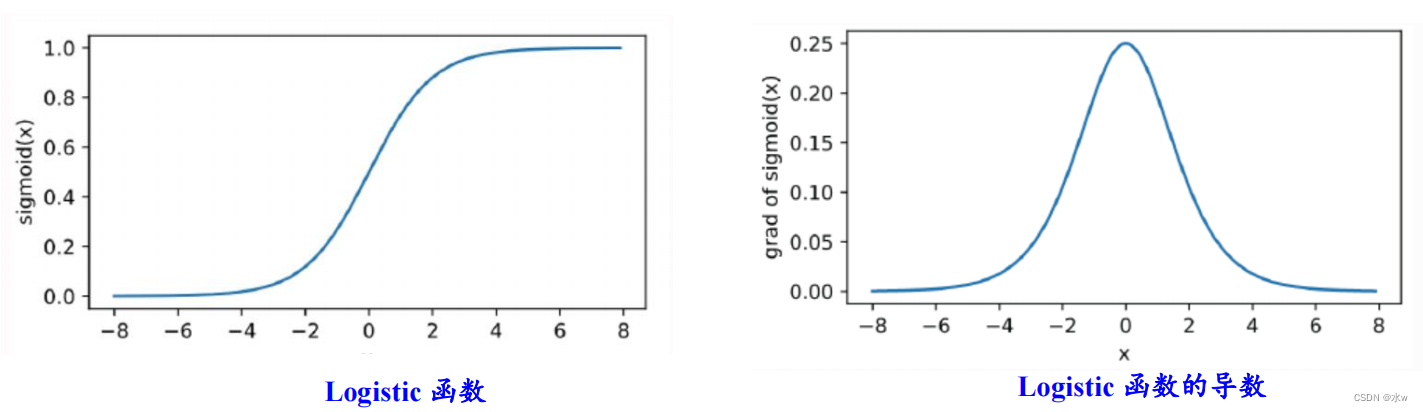
虽然tanh函数相较于sigmoidFunction is similar to,但是tanh函数的导函数(0~1)比sigmoid函数的导函数(0~1/4)大,tanh函数的函数图和导数图:

更加推荐:ReLUFunction of the image and the derivative figure
ReLU函数的左侧导数为0,右侧导数恒为1,To avoid the decimal LianCheng,但反向传播中仍有权值的累乘.ReLU函数改善了“梯度消失”现象.
Very borrowed from human neurons unilateral unilateral inhibition activated,ReLUFunction of the image and the derivative figure:

缺陷:On the left side of the base for0,Easy to make neurons die directly to learn,So basically will useReLU函数的变体.
2 长短期记忆网络(LSTM)
Long Short Term Memory networks(以下简称LSTMs),一种特殊的RNN网络,The network is designed in order to solve the problem of long-range dependence.增加状态c,称为单元状态(cell state),让它来保存长期的状态
LSTMs首先继承了RNN模型的特性,So it is aShort-term memory function. 其次,The memory of its special unit Settings,Also make it have the function that the long-term memory.

LSTM使用三个控制开关
LSTMThrough the so-called switch Settings,Such a state to achieve our unitCAnd the output of the hidden layer,Then we take a look at the three very important below what is the status of the unit.
LSTM的关键,就是怎样控制长期状态c.LSTM使用三个控制开关 :① 第一个开关,Responsible for controlling how to continue to save state for a long timec② 第二个开关,负责控制把即时状态输入到长期状态c;③ 第三个开关,负责控制是否把长期状态c作为当前的LSTM的输出;
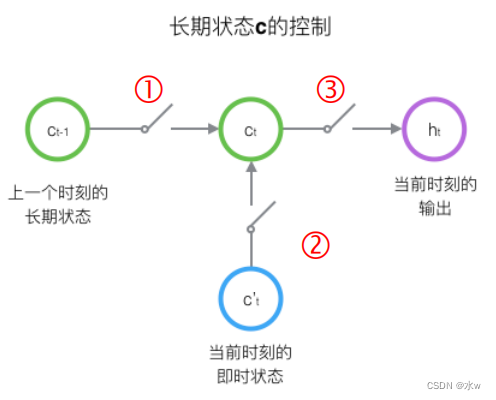
LSTM Repeat module
Each module represents different moment.

而LSTM Repeat modules as follows,除了h在随时间流动,单元状态c也在随时间流动,单元状态c就代表着长期记忆.
- 黄框:Said we learned neural network layer;
- Pink circle:Represents some arithmetic operations;
- 单箭头:Direction of flow arrow said vector transmission;
- Two arrows to merge:According to vector a splicing process;
- Arrow y:According to vector replication process;

LSTM 的核心思想
与RNNA big difference between:LSTM 的关键是状态单元C,Such as horizontal line in the figure above throughout the run.Unit of the state of the relay is similar to the conveyor belt,Its direct run on the entire chain,Only some small amount of linear interaction,Easy to save information.

“门”(gate)
LSTM 通过精心设计的称作为“门”(gate)The structure of the unit to remove or add the information in the state.门是一种让信息选择式通过的方法.

The door includes a sigmoid 神经网络层和一个 pointwise 乘法操作.
补充:LSTM用两个门来控制单元状态c的内容 :* 遗忘门(forget gate),它决定了上一时刻的单元状态ct-1How many reserves to当前时刻ct(How much will be to remember);* 输入门(input gate),它决定了当前时刻网络的输入xtHow many saved to a single元状态ct .• LSTM用输出门来控制单元状态ct有多少输出到 LSTM的当前输出值ht
逐步理解 LSTM之遗忘门

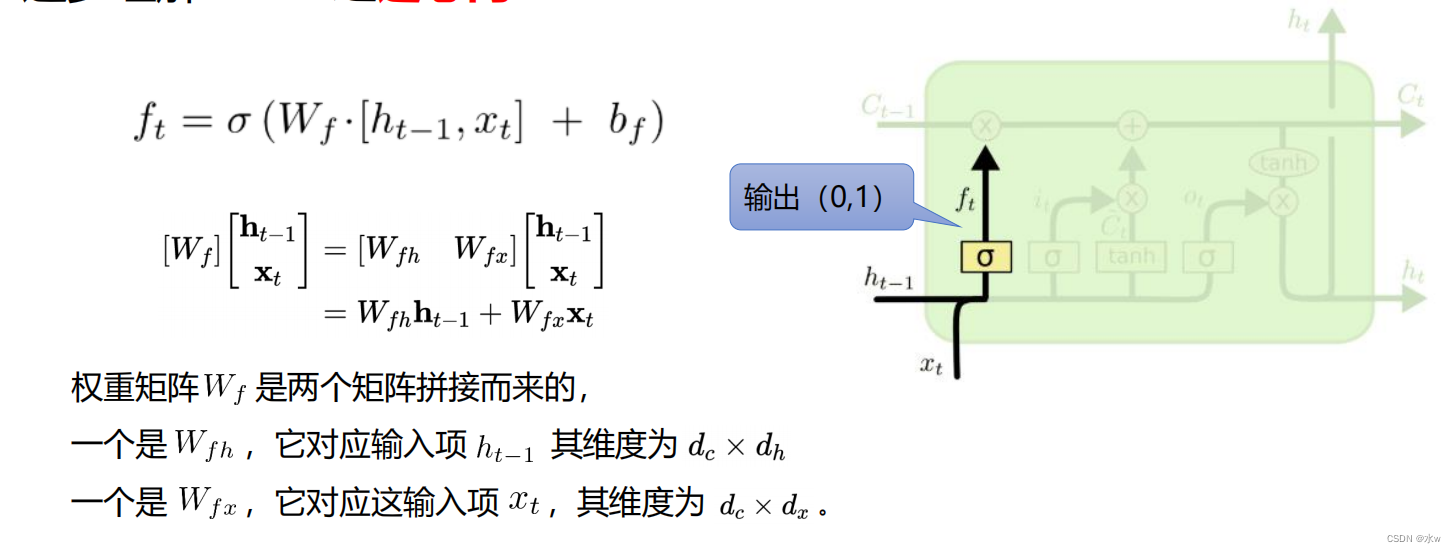
这个门怎么做到“遗忘“的呢?怎么理解?既然是遗忘旧的内容,为什么这个门还要接收新的𝒙𝒕?
The example of choose and employ persons,Our mind to remember a lot of knowledge,But knowledge when not,We are can't think of it.
Suppose now out of the question to test you,You will be on its related knowledge to recall,This process of memories will consciously forgotten something,Remember some of the content,That in the,Why some are remembered,Some have been forgotten?
Is this new stimulusXtMade a choice,Or do a whip,To decide which is the need of forgotten,What is the need to remember.Of course the remember and forget what is the proportion of,So we use byS得到一个0~1Value of a weigh the choice.
逐步理解 LSTM之输入门
sigmoid The function called 为输入门,Decide what to update values ;tanh 层创建一个新的候选值向量, 会被加入到状态中;

逐步理解 LSTM之更新单元状态

由于遗忘门的控制,它可以保存很久很久之前的信息,由于输入门的控制,它又可以避免当前无关紧要的内容进入记忆.
逐步理解 LSTM之输出门
Output door control the effects of long-term memory for the current output,The status of output by the door and unit jointly set.

(1) LSTM训练算法框架
- 遗忘门:公式1
- 输入门:公式2和公式3,公式4(The current state unitCtAn update to the process)
- 输出门:公式5和公式6

LSTM的训练算法仍然是反向传播算法.主要有下面三个步骤:
① 前向计算每个神经元的输出值,对于LSTM来说,即五个 向量的值.Calculation method has been described in the previous page.② 反向计算每个神经元的误差项值.与循环神经网络一样,LSTM误差项的反向传播也是包括两个方向:一个是沿时间的反向传播,即从当前t时刻开始,计算每个时刻的误差项;一个是将误差项向上一层传播.③ 根据相应的误差项,计算每个权重的梯度.
(2)关于公式和符号的说明

sigmoid和tanh函数的导数都是原函数的函数.这样,When calculating the value of the function,就可以用它来计算出导数的值.
LSTM需要学习的参数共有8组,分别是:
- 遗忘门的权重矩阵和偏置项 、
- 输入门Weight matrices and bias item 、
- 输出门的权重矩阵 和偏置项 、
- 计算单元状态Weight matrices and bias item .
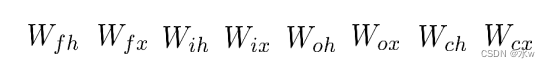


当一个行向量右乘一个对角矩阵时,相当于这个行向量According to the elements by the matrix对角线组成的向量:
上面这两点,In subsequent derivation will often use.
(3)误差项沿时间的反向传递
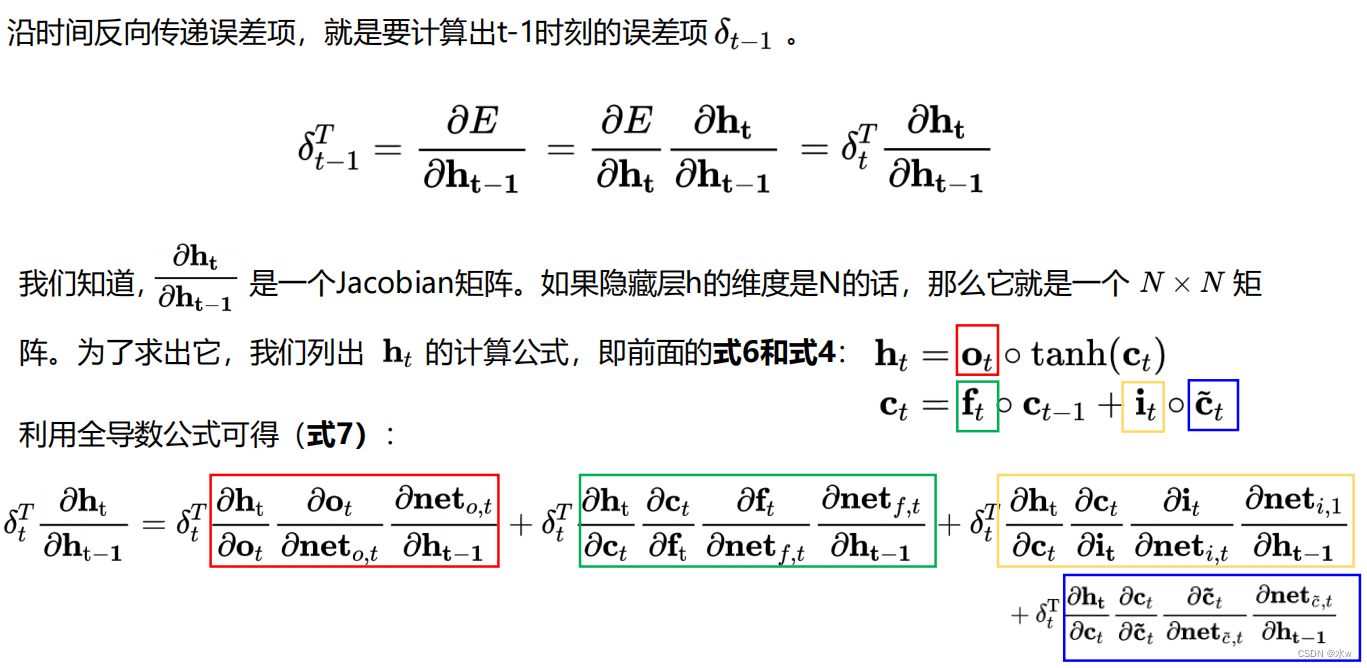



 上述公式就是将误差沿时间反向传播一个时刻的公式.有了它,Can write transfer error term forward to any𝑘时刻的公式:
上述公式就是将误差沿时间反向传播一个时刻的公式.有了它,Can write transfer error term forward to any𝑘时刻的公式:

(4)将误差项传递到上一层


(5)权重梯度的计算
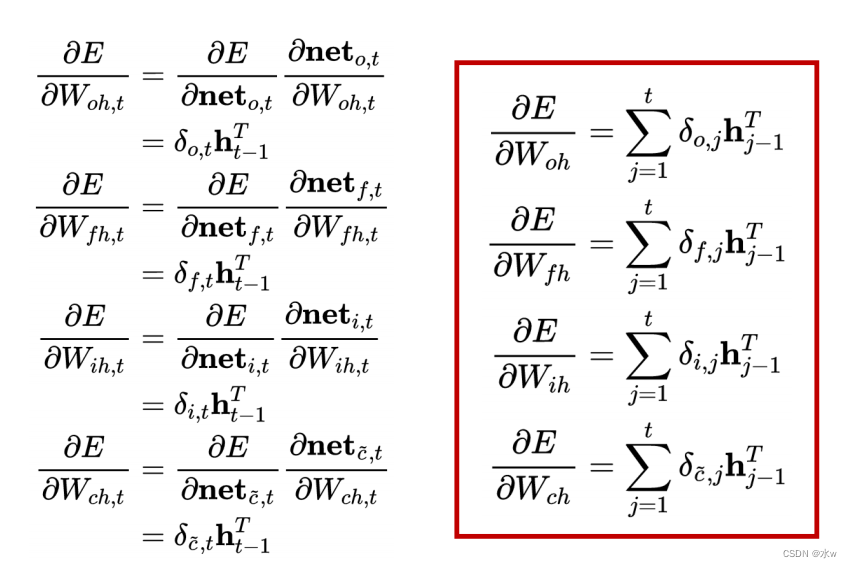
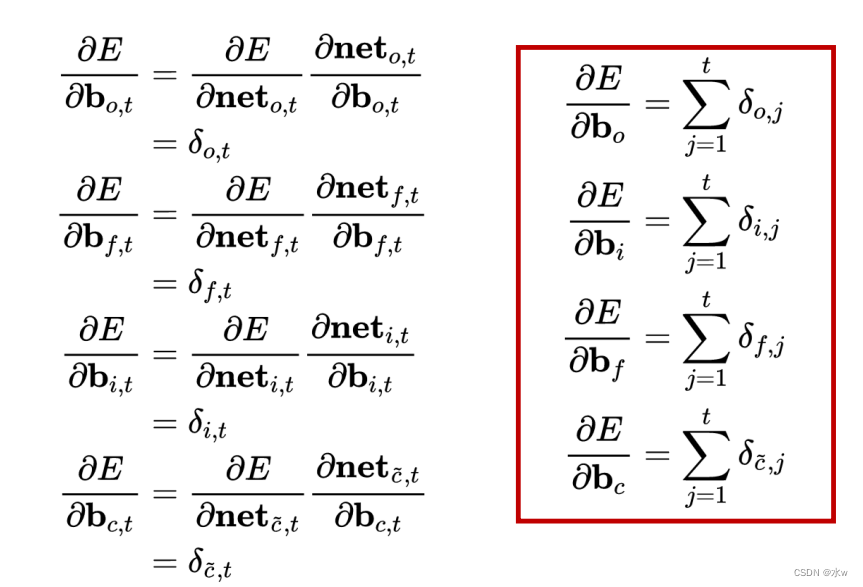

3 门控循环神经网络(GRU)
GRU(Gate Recurrent Unit)是循环神经网络RNN的一种.和LSTM一样,也是为了解决长期记忆和反向传播中的梯度等问题而提出来的.
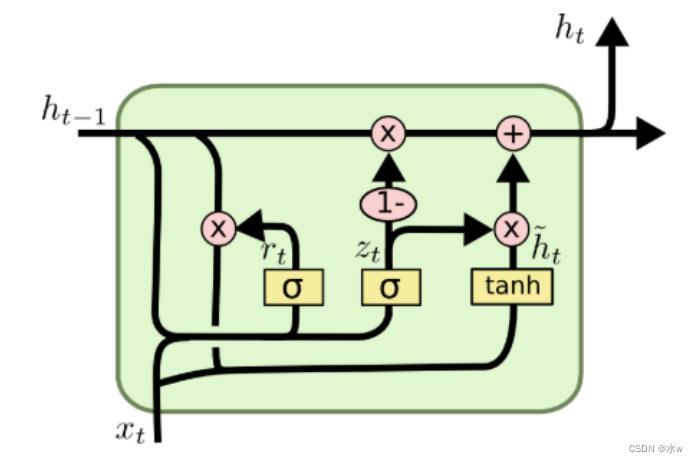
优点
GRU是LSTM的一种变体,它较LSTM网络的结构更加简单,而且效果也很好.LSTMIntroduces three door function:输入门、遗忘门和输出门To control the input values、记忆值和输出值.而在GRU模型中只有两个门,分别是更新门和重置门. 另外,GRU将单元状态与输出合并为一个状态h.

LSTM与GRU
• GRU的参数更少,Thus training faster or require less data to generalize.• 如果你有足够的数据,LSTMThe strong power of expression may produce better results.Greff, et al. (2016)对流行的LSTMContrasted the variant experiment,Found their performance almost unanimously. Jozefowicz, et al. (2015)Test in more than ten thousandRNN结构,Find some tasks case,有Some variants thanLSTM工作得更好.
4 深层循环神经网络
Cycle of neural network can be deep to shallow network* 深网络:Spread out the loop network according to the time,Long time interval between the state of the path is very long ;* 浅网络:At the same time the network between the input to the output path xt→yt 非常浅 ;The significance of increasing cycle the depth of the neural network* The ability to increase circulation neural network ;* Increase at the same time the network between the input to the output path xt→yt , Such as to increase the number of hidden states output ht→yt ,And input to the hidden states xt→htThe path between the depth of the;
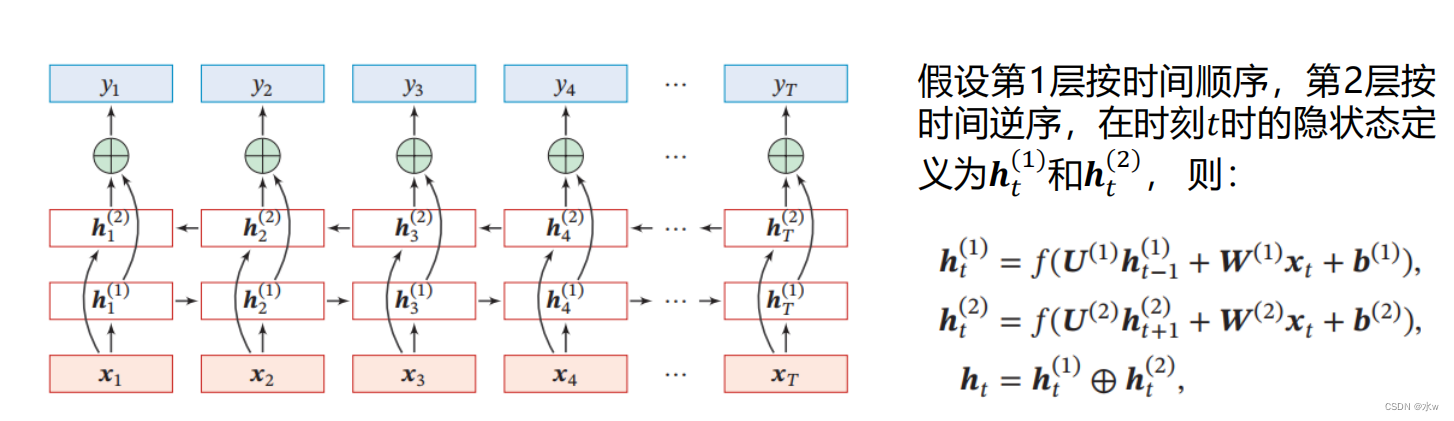
堆叠循环神经网络 (Stacked Recurrent Neural Network, SRNN)

双向循环神经网络(Bidirectional Recurrent Neural Network)
双向循环神经网络(Bidirectional Recurrent Neural Network)Consists of two layers of circulation neural network,它们的输入相同,只是信息传递的方向不同
边栏推荐
- What are the concepts, purposes, processes, and testing methods of interface testing?
- 华为路由器旁挂引流实验(使用流策略)
- SELECT:简单的查询操作语法&使用例——《mysql 从入门到内卷再到入土》
- 突破次元壁垒,让身边的玩偶手办在屏幕上动起来!
- 2022.8.9 Mock Competition
- TCL:事务的特点,语法,测试例——《mysql 从入门到内卷再到入土》
- 石油化工行业商业供应链管理系统:标准化供应商管理,优化企业供应链采购流程
- 国内Gravatar头像的完美替代方案Cravatar
- LeetCode-402 - Remove K digits
- Shell编程规范与变量
猜你喜欢





随机推荐
智能方案设计——智能跳绳方案
[SQL brush questions] Day3----Special exercises for common functions that SQL must know
3D model reconstruction of UAV images based on motion structure restoration method based on Pix4Dmapper
Object.assign用法 以及 与$.extend的区别
化学制品制造业数智化供应链管理系统:建立端到端供应链采购一体化平台
C. Social Distance
C. Rotation Matching
关于 DataFrame: 处理时间
流程控制结构——《mysql 从入门到内卷再到入土》
What are the concepts, purposes, processes, and testing methods of interface testing?
从斐波那契 - 谈及动态规划 - 优化
Redis Performance Impact - Asynchronous Mechanisms and Response Latency
B. Codeforces Subsequences
shell小技巧(一百三十五)打包指定目录下所用文件,每个文件单独打包
web逆向之丁香园
shell脚本循环语句for、while语句
Service - DNS forward and reverse domain name resolution service
ENVI最小距离、最大似然、支持向量机遥感影像分类
About DataFrame: Processing Time
LeetCode-402 - Remove K digits