当前位置:网站首页>Re regular expression
Re regular expression
2022-04-23 17:59:00 【name_ QGY】
re Regular expressions
A regular expression is a special sequence of characters , It can help users check whether a string matches a pattern , So as to quickly retrieve or replace a certain mode 、 The text of the rule . Equate to Word Find and replace functions in .
import re
text='178,168,123456,9537,123456'
print(re.findall('123456',text))
#Out:
['123456', '123456']
1 Recognize regular expressions
| Regular characters | Sketch Statement |
|---|---|
| . | Matching elimination "\n" Any single character other than . The most extensive . To match includes ’\n’ Any character in , You can use ’[.\n]' Pattern |
| \d | Matches a numeric character , Equivalent to [0-9] |
| \D | Matches a non-numeric character , Equivalent to [^0-9] |
| \s | Match any white space character , Including Spaces 、 tabs 、 Form-feed character, etc , Equivalent to [\f\n\r\t\v] |
| \S | Match non white space characters , Equivalent to [^\f\n\r\t\v] |
| \w | Matches any word numeric character that includes an underscore , Equivalent to [A-Za-z0-9_] |
| \W | Match any non word 、 Numbers 、 Underscore character , Equivalent to [^A-Za-z0-9_] |
| Regular characters | Sketch Statement |
|---|---|
| [Pp]ython | matching Python or python |
| rub[ye] | matching ruby or rube |
| [aeiou] | Match any letter in bracket |
| [0-9] | Match any number , Equivalent to [0123456789] |
| [a-z] | Match any lowercase letter |
| [A-Z] | Match any capital letter |
| [a-zA-Z0-9] | Match any letters and numbers |
| [^aeiou] | Matching elimination aeiou All characters except letters |
| [^0-9] | Match all characters except numbers |
import re
text=' height :180, weight :130, Student number :123456, password :9537'
print(re.findall(r'\d',text))
print(re.findall(r'\S',text))
print(re.findall(r'\w',text))
print(re.findall(r'[1-5]',text))
print(re.findall(r'[ High weight ]',text))
#Out:
['1', '7', '8', '1', '6', '8', '1', '2', '3', '4', '5', '6', '9', '5', '3', '7']
[' body ', ' high ', ':', '1', '7', '8', ',', ' body ', ' heavy ', ':', '1', '6', '8', ',', ' learn ', ' Number ', ':', '1', '2', '3', '4', '5', '6', ',', ' The secret ', ' code ', ':', '9', '5', '3', '7']
[' body ', ' high ', '1', '7', '8', ' body ', ' heavy ', '1', '6', '8', ' learn ', ' Number ', '1', '2', '3', '4', '5', '6', ' The secret ', ' code ', '9', '5', '3', '7']
['1', '1', '1', '2', '3', '4', '5', '5', '3']
[' high ', ' heavy ']
| Regular characters | Sketch Statement |
|---|---|
| * | 0 Or more |
| + | 1 Or more |
| ? | 0 or 1 individual |
| {2} | 2 individual |
| {2,5} | 2-5 individual |
| {2,} | At least 2 individual |
| {,5} | at most 5 individual |
text = "my telephone number is 15951817010,and my hometown's telephone \
number is 13863417300,my landline number is 0634-5608603."
print(re.findall(r'\d{4}-\d{7}(?# Find the landline number )', text))
#Out:
['0634-5608603']
| Regular examples of combinations | Sketch Statement |
|---|---|
| \d{6}[a-z]{6} | The two sub modes are put together to form a large mode , matching 6 A number plus 6 Lowercase letters |
| \d{6}|[a-z]{6} | Use a vertical bar to indicate that there is a match between the front and rear patterns , matching 6 A number or 6 Lowercase letters |
| (abc){3} | Use parentheses to indicate grouping , After grouping, quantifiers can be applied in groups , matching abcabcabc |
| \X | Matching first X A matching group |
| (?#…) | notes |
###\X
text="aabbcc ddfgkk oaddww aaaaaa ababcc"
print(re.findall(r'(\w{2})(\1)',text))
print(re.findall(r'(\w{2})(\1)(\2)',text))
#Out:
[('aa', 'aa'), ('ab', 'ab')]
[('aa', 'aa', 'aa')]
###(?#...)
text = "my telephone number is 15951817010,and my hometown's telephone \
number is 13863417300,my landline number is 0634-5608603."
print(re.findall(r'\d{4}-\d{7}(?# Find the landline number )', text))
#Out:
['0634-5608603']
| Regular characters | Sketch Statement |
|---|---|
| ^ | Match the beginning of the string |
| $ | Match the end of the string |
| \A | Match string start |
| \Z | End of match string , If there is a newline , Just match the end string before the line break |
| \b | Match word boundaries , This is the position between the word and the space . for example :er\b Can match never Medium er, But can't match verb Medium er |
| \B | Match non word boundaries . for example :er\B Can match verb Medium er, But can't match never Medium er |
| (?=…) | The matching content is … Before |
| (?!..) | The matching content is not in … Before |
| (?<=…) | The matching content is … after |
| (?<!..) | The matching content is not in … after |
###(?=...)
text="height:180,weight:63,student_num:2020802178,key:hello_world"
print(re.findall(r'\w+(?=:2020802178)',text))
#Out:
['student_num']
###(?<=...)
print(re.findall(r'(?<=key:)\w+',text))
#Out:
['hello_world']
The content of regular expressions is broad and profound , You can master the basic framework first , Know what things , Explore further if necessary , I think this is learning new knowledge 、 A more efficient way to learn new things . It's like learning a new subject , There is no need to recite the classic bibliography of the subject word by word , Just master the core content , Form a network in your mind , When you need to use a certain part of this net, study it carefully .
2 re modular
python Of re modular , Include 8 A way :
- re.search(): Find characters that match the pattern , Just return the first one , return Match object
- re.match(): and search equally , But it must match from the beginning of the string , return Match object
- re.findall(): Returns a list of all matching strings
- re.finditer(): Returns an iterator , It contains all matches , That is to say Match object
- re.sub(): Replace matching string , Returns the text after the replacement
- re.subn(): Replace matching string , Returns the text that has been replaced and the number of times it has been replaced
- re.split(): Use the string matching the expression as a separator to split the original string
- re.compile(): Compile regular expressions into an object , Easy to use at the back
above 8 According to different functions, the two methods can be divided into 4 Column , They are to find , Replace , Split and compile .
2.1 lookup , Yes 4 A way :search、match、findall、finditer
2.1.1 search - Only return 1 individual
import re
text = "abc,Abc,aBC,abc"
print(re.search(r'abc',text))
#Out:
<re.Match object; span=(0, 3), match='abc'>
search The method is to return a Match object , And only one value was returned ,span=(0,3) It means to match to the... Th 1-3 Characters , How to go from Match Get the matching value from the object , Need to use group Method .
import re
text = "abc,Abc,aBC,abc"
m = re.search(r'abc', text)
print(m.group())
#Out:
abc
group The return value of the method without parameters is the result of matching .
If you group matching values , You can go through group Method to pass in the parameters of the group , The output result is the result of the matching group .
text = "name:qgy,score:99;name:myt,score:98"
m = re.search(r'(name):(\w{3})',text)
print(m.group())
print(m.group(1))
print(m.group(2))
print(m.groups())
#Out:
name:qgy
name
qgy
('name', 'qgy')
Here I would like to add a knowledge point , The four methods found have three parameters , The previous part only uses the first two , So re.search() Methods as an example ,
re.search(pattern,string,flags=0)
The first parameter pattern It refers to the matching pattern , The second parameter string Is the string to match ,flags It's the sign bit , Used to control how regular expressions are matched , Such as : Is it case sensitive 、 Multiline matching, etc .
text = "aBc,Abc,aBC,abc"
m = re.search(r'abc', text, flags=re.I)
print(m.group())
#Out:
aBc
In the upper regular , What I want to match is abc,text Does not exist in the abc, The result of the match is aBc.
in other words ,re.I Is case insensitive .
Want to find flags What are they? , You can hold down the ctrl Click... In your script re Position of appearance , It will pop up re.py file , Press and hold... Under the file ctrl+F, Pop up search box , Input flags You can see flags What are the parameters .
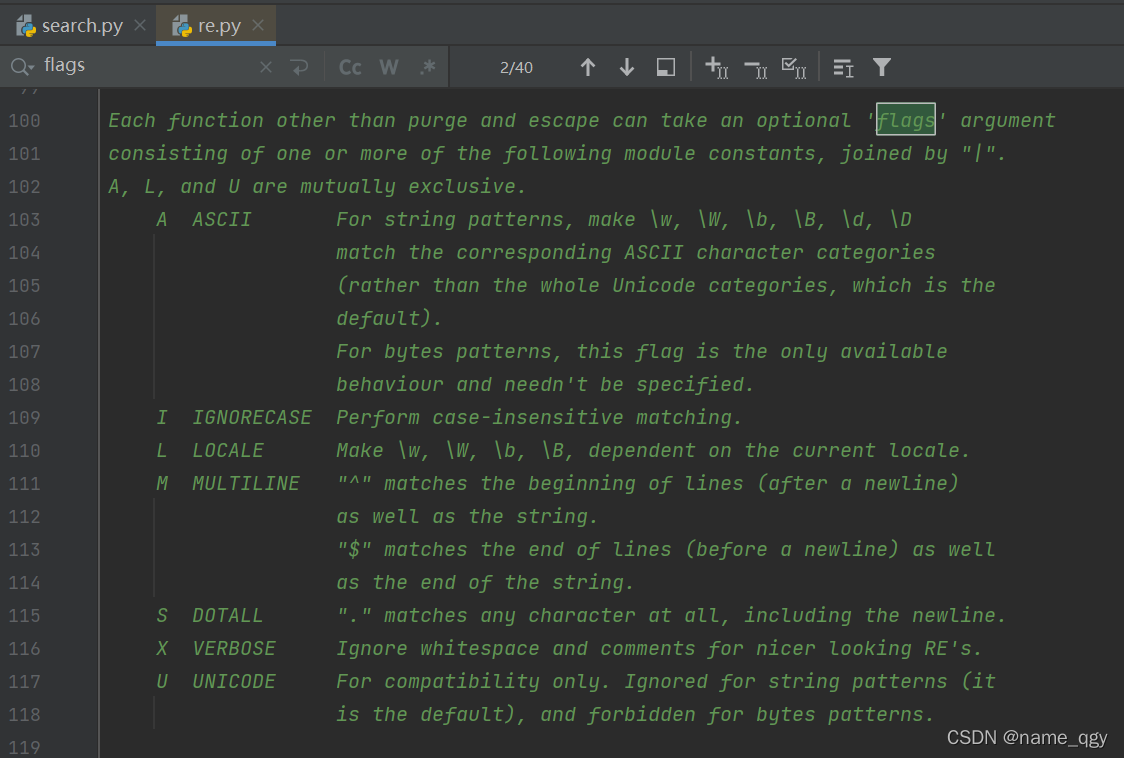
2.1.2 match - Also only return 1 individual , But match from scratch
text = "xaBc,Abc,aBC,abc"
m = re.match(r'abc', text, flags=re.I)
n = re.search(r'^abc',text,flags=re.I)
print(m)
print(n)
#Out:
None
None
In the top code , I will aBc Added before x, Use match Method , matching text The starting character , If the starting character does not conform to the regular expression , The match will fail , The result returned is None.
re.match(r’‘,text) Equivalent to re.search(r’^',text)
Tell the truth ,match No dice , Design this match It gives people the feeling of painting a snake and adding feet , use search That's enough
2.1.3 findall - Returns all matching strings
text = "name:qgy,score:99;name:myt,score:98"
m = re.findall(r'(name):(\w{3})',text)
print(m)
#Out:
[('name', 'qgy'), ('name', 'myt')]
findall Method to return a list , If there are groups when matching , Each value in the list will use () Cover up , Use... Between different groups ‘,’ Division .
2.1.4 finditer - return Match iterator
text = "name:qgy,score:99;name:myt,score:98"
m = re.finditer(r'(name):(\w{3})',text)
print(m)
for i in m:
print(i)
#Out:
<callable_iterator object at 0x00000224C3D5A460>
<re.Match object; span=(0, 8), match='name:qgy'>
<re.Match object; span=(18, 26), match='name:myt'>
finditer Is to return an iterator , I don't know what iterators are , I guess I don't have to , Just don't spend time and energy sorting out for the time being . This piece has been passed by the spring and autumn brushwork .
Find the function of 4 A method of ,search、match and finditer All return to one Match object , Can master the most basic findall and search, Just find it all findall, Find one to use search.
2.2 Replace , Yes 2 A way :sub、subn
The two methods replaced are only different from the four methods found earlier , Multiple parameters , That is, you need to indicate what character you want to replace .
2.2.1 sub - It's English words substitute English abbreviations
text="abc,aBc,ABc,xyz,opq"
result=re.sub(r'abc','xyz',text,flags=re.I)
print(result)
#Out:
xyz,xyz,xyz,xyz,opq
2.2.2 subn - After the replacement, tell me that several characters have been replaced
text="abc,aBc,ABc,xyz,opq"
result=re.subn(r'abc','xyz',text,flags=re.I)
print(result)
#Out:
('xyz,xyz,xyz,xyz,opq', 3)
2.3 Division
split The method is to split a string into some small strings according to certain rules .
split What's the use ? for instance , I have a sequence , I digested the sequence with restriction enzyme , Cut the original sequence into small fragments , Want to know the sequence information of small fragments after cutting , You can go through split Method to implement .
MobI = "GATC"
text = "ATCGATCGGTTTAAGATCCTTCG"
result = re.split(MobI, text, flags=re.I)
print(result)
#Out:
['ATC', 'GGTTTAA', 'CTTCG']
2.4 compile
compile The method is to take a regular expression as an object that can be conveyed , Pass the object to another method and you can use it , To do search、findall wait .
Why compile , The advantage of using compilation method is to improve efficiency , If a regular expression needs to be repeated thousands of times , It's not very troublesome to manually input each match , With the result of compilation , When it is reused, it directly calls .
re_telephone=re.compile(r'\d{4}-\d{3,8}')
text1="Xiao ming's telephone number is 0634-4854481"
text2="Xiao hone's telephone number is 0531-145488454"
text3="Xiao gang's telephone number is 0452-567188155"
print(re_telephone.search(text1).group())
print(re_telephone.search(text2).group())
print(re_telephone.search(text3).group())
#Out:
0634-4854481
0531-14548845
0452-56718815
版权声明
本文为[name_ QGY]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204231757533626.html
边栏推荐
- 2022年上海市安全员C证操作证考试题库及模拟考试
- Yolov4 pruning [with code]
- Arithmetic expression
- Where is the configuration file of tidb server?
- Generate verification code
- 2022 tea artist (primary) examination simulated 100 questions and simulated examination
- QTableWidget使用讲解
- Element calculation distance and event object
- _ FindText error
- JS forms the items with the same name in the array object into the same array according to the name
猜你喜欢
![Click Cancel to return to the previous page and modify the parameter value of the previous page, let pages = getcurrentpages() let prevpage = pages [pages. Length - 2] / / the data of the previous pag](/img/ed/4d61ce34f830209f5adbddf9165676.png)
Click Cancel to return to the previous page and modify the parameter value of the previous page, let pages = getcurrentpages() let prevpage = pages [pages. Length - 2] / / the data of the previous pag

Halo open source project learning (II): entity classes and data tables

2022年上海市安全员C证操作证考试题库及模拟考试

Welcome to the markdown editor
高德地图搜索、拖拽 查询地址
Laser slam theory and practice of dark blue College Chapter 3 laser radar distortion removal exercise

Romance in C language

云原生虚拟化:基于 Kubevirt 构建边缘计算实例
On the method of outputting the complete name of typeID from GCC
re正则表达式
随机推荐
云原生虚拟化:基于 Kubevirt 构建边缘计算实例
Implementation of image recognition code based on VGg convolutional neural network
极致体验,揭晓抖音背后的音视频技术
2022江西储能技术展会,中国电池展,动力电池展,燃料电池展
Array rotation
2022 judgment questions and answers for operation of refrigeration and air conditioning equipment
Operation of 2022 mobile crane driver national question bank simulation examination platform
Gets the time range of the current week
587. Install fence / Sword finger offer II 014 Anagrams in strings
2022 Jiangxi energy storage technology exhibition, China Battery exhibition, power battery exhibition and fuel cell Exhibition
Oil monkey website address
Uniapp custom search box adaptation applet alignment capsule
Leak detection and vacancy filling (VII)
Remember using Ali Font Icon Library for the first time
Go的Gin框架学习
Go语言JSON包使用
Summary of common server error codes
Special effects case collection: mouse planet small tail
Thirteen documents in software engineering
Write a regular