自Transformer提出以来,其在NLP和CV领域都取得了很好的性能,以及展现了其模型大一统的潜力。面向工业上的强烈应用需求,我们组最近一直在探索和研究Transformer如何在工业上部署和落地,也欢迎更多的人能够加入进来一起讨论和探究。近期我们组关于transformer归一化算子(LayerNorm)改进的工作《Unified Normalization for Accelerating and Stabilizing Transformers》被ACM MM 2022接受,和大家一起分享讨论下。

论文地址:https://arxiv.org/pdf/2208.01313.pdf
目前代码正在整理和审核,后续会进行开源,代码地址:
https://github.com/hikvision-research/Unified-Normalization
研究动机
Transformer这两年在CV任务上取得了广泛的应用和验证,其在工业界有着很强的部署和落地需求。对比CNN中的采用的BN归一化方式(BN是非常高效的,在部署中可以吸收到卷积中),Transformer中采用LayerNorm的归一化方式,对部署是非常不友好的。主要原因有两点:
1)LN需要在线计算过程,具体地,在线计算均值和方差;
2)LN的方差计算需要开方操作,这在某些部署平台上是非常低效的,甚至是不支持的。那么直接在Transformer中将LN替换成BN怎么样呢?实验性的答案是性能会变差甚至训练会直接崩溃。
其实这个问题很多同学都发现了,也都进行了讨论,transformer 为什么使用 layer normalization,而不是其他的归一化方法?。深究其中的原因,我们是将其归结为transformer在训练过程中的激活值及其梯度的统计值异常问题(后面会详细讨论)。对此的话,我们是提出了一种统一的归一化方法Unified Normalization(UN),首先,它可以像BN一样是非常高效,能够被合并到相邻的线性操作中。其次,利用数据的先验统计信息,相较于LN,它可以做到性能几乎相同或者很小的掉点。我们在机器翻译、图像分类、目标检测和图像分割等任务上都验证了其有效性,并且在GeForce RTX 3090上推理,可以带来31%的加速和18%内存节省。

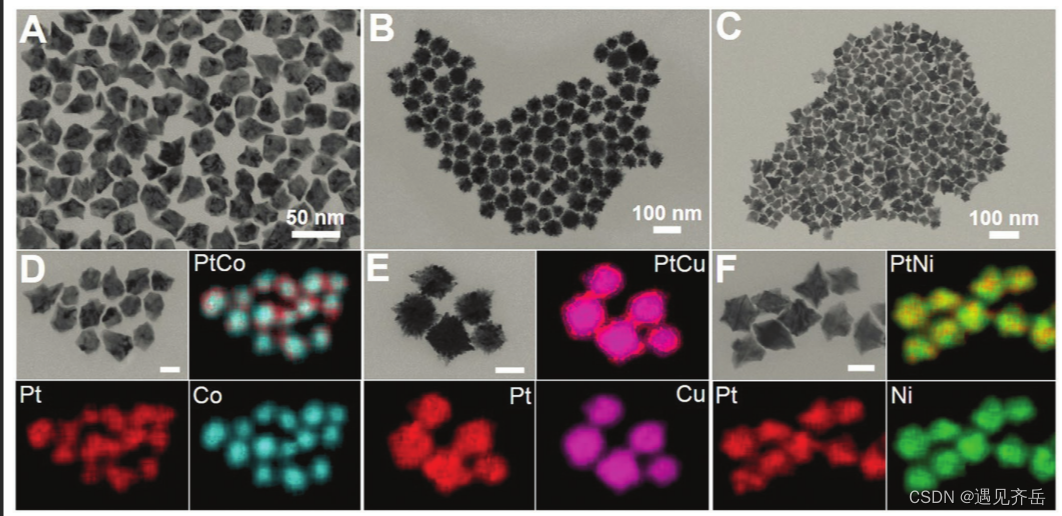 [email protected])纳米酶"/>
[email protected])纳米酶"/>
 [email protected]纳米模拟酶|PtCo合金纳米粒子"/>
[email protected]纳米模拟酶|PtCo合金纳米粒子"/>