当前位置:网站首页>redis缓存如何保证数据一致性
redis缓存如何保证数据一致性
2022-08-09 11:12:00 【Java技术债务】
问题的引入
同时有请求A和请求B进行更新操作,那么会出现 (1)线程A更新了数据库 (2)线程B更新了数据库 (3)线程B更新了缓存 (4)线程A更新了缓存
如果访问数据库后,不更新缓存,直接删除缓存,由下一个请求去缓存 那么会出现如下情况: (1)如果你是一个写数据库场景比较多,而读数据场景比较少的业务需求,采用这种方案就会导致,数据压根还没读到,缓存就被频繁的更新,浪费性能。 (2)如果你写入数据库的值,并不是直接写入缓存的,而是要经过一系列复杂的计算再写入缓存。那么,每次写入数据库后,都再次计算写入缓存的值,无疑是浪费性能的。显然,删除缓存更为适合。
那么先操作缓存,还是先操作数据库?
解决方案
- 第一种:先删缓存,再更新数据库 该方案会导致请求数据不一致 同时有一个请求A进行更新操作,另一个请求B进行查询操作。那么会出现如下情形: (1)请求A进行写操作,删除缓存 (2)请求B查询发现缓存不存在 (3)请求B去数据库查询得到旧值 (4)请求B将旧值写入缓存 (5)请求A将新值写入数据库 上述情况就会导致不一致的情形出现。而且,如果不采用给缓存设置过期时间策略,该数据永远都是脏数据。
- 第二种:先更新数据库,再删缓存疑问:这种情况不存在并发问题么? 假设这会有两个请求,一个请求A做查询操作,一个请求B做更新操作,那么会有如下情形产生 (1)缓存刚好失效 (2)请求A查询数据库,得一个旧值 (3)请求B将新值写入数据库 (4)请求B删除缓存 (5)请求A将查到的旧值写入缓存 ok,如果发生上述情况,确实是会发生脏数据。 然而,发生这种情况的概率又有多少呢? 发生上述情况有一个先天性条件,就是步骤(3)的写数据库操作比步骤(2)的读数据库操作耗时更短,才有可能使得步骤(4)先于步骤(5)。可是,大家想想,数据库的读操作的速度远快于写操作的(不然做读写分离干嘛,做读写分离的意义就是因为读操作比较快,耗资源少),因此步骤(3)耗时比步骤(2)更短,这一情形很难出现。
先更新数据库,再删缓存依然会有问题,不过,问题出现的可能性会因为上面说的原因,变得比较低!
所以,如果你想实现基础的缓存数据库双写一致的逻辑,那么在大多数情况下,在不想做过多设计,增加太大工作量的情况下,请先更新数据库,再删缓存!
- 第三种:缓存延时双删 使用缓存延时双删。 (1)先淘汰缓存 (2)再写数据库(这两步和原来一样) (3)休眠1秒,再次淘汰缓存 这么做,可以将1秒内所造成的缓存脏数据,再次删除。
问题:如果你用了mysql的读写分离架构怎么办?
在这种情况下,造成数据不一致的原因如下,还是两个请求,一个请求A进行更新操作,另一个请求B进行查询操作。 (1)请求A进行写操作,删除缓存 (2)请求A将数据写入数据库了 (3)请求B查询缓存发现,缓存没有值 (4)请求B去从库查询,这时,还没有完成主从同步,因此查询到的是旧值 (5)请求B将旧值写入缓存 (6)数据库完成主从同步,从库变为新值 上述情形,就是数据不一致的原因。还是使用双删延时策略。只是,睡眠时间修改为在主从同步的延时时间基础上,加几百ms。
问题:采用这种同步淘汰策略,吞吐量降低怎么办? 那就将第二次删除作为异步的。自己起一个线程,异步删除。这样,写的请求就不用沉睡一段时间后了,再返回。这么做,加大吞吐量。
问题:删缓存失败了怎么办 重试机制。 一、流程如下: (1)更新数据库数据; (2)缓存因为种种问题删除失败 (3)将需要删除的key发送至消息队列 (4)自己消费消息,获得需要删除的key (5)继续重试删除操作,直到成功 然而,该方案有一个缺点,对业务线代码造成大量的侵入。
于是有了方案二,在方案二中,启动一个订阅程序去订阅数据库的binlog,获得需要操作的数据。在应用程序中,另起一段程序,获得这个订阅程序传来的信息,进行删除缓存操作。
二、流程如下图所示: (1)更新数据库数据 (2)数据库会将操作信息写入binlog日志当中 (3)订阅程序提取出所需要的数据以及key (4)另起一段非业务代码,获得该信息 (5)尝试删除缓存操作,发现删除失败 (6)将这些信息发送至消息队列 (7)重新从消息队列中获得该数据,重试操作。 而读取binlog的中间件,可以采用阿里开源的canal
边栏推荐
猜你喜欢
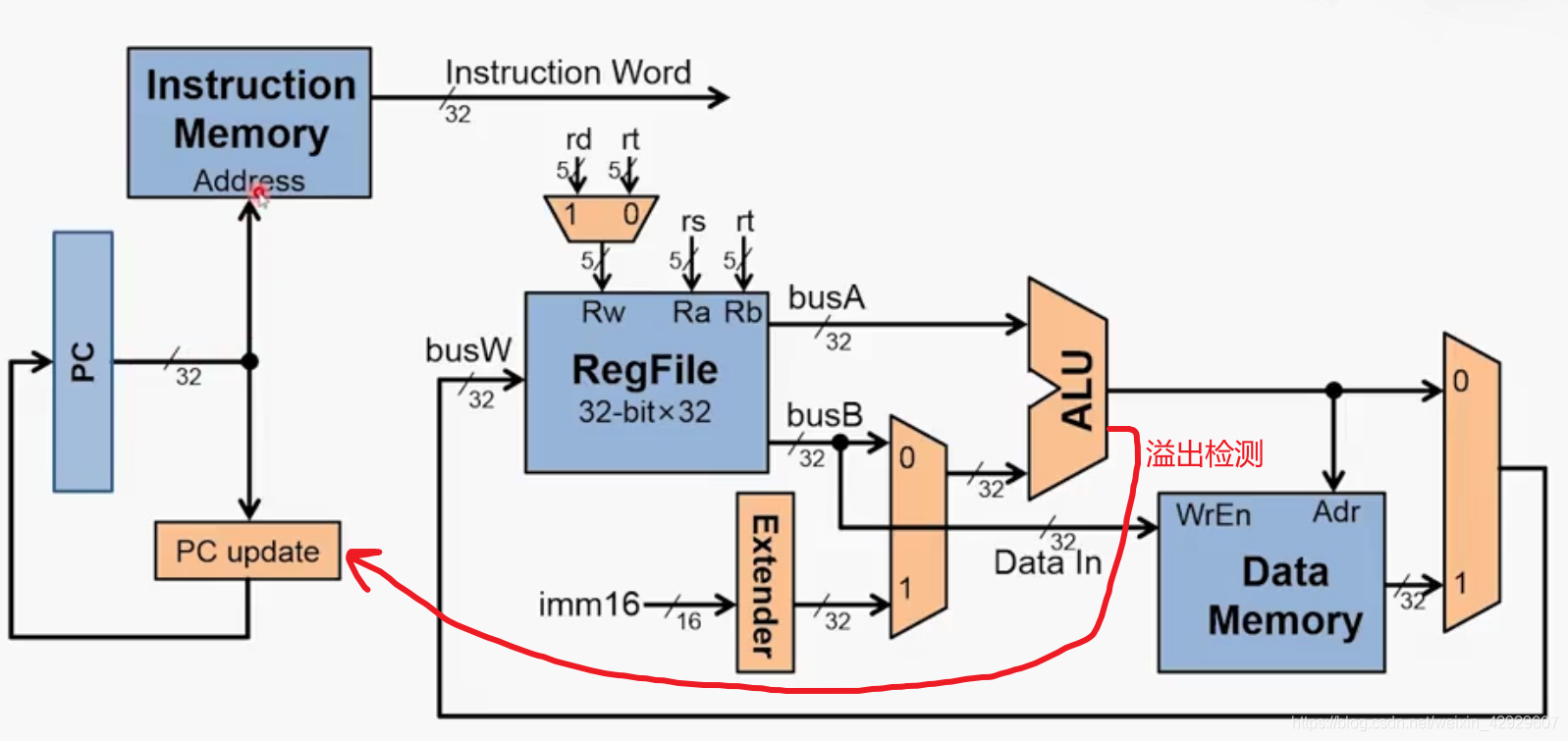
x86 Exception Handling and Interrupt Mechanism (1) Overview of the source and handling of interrupts
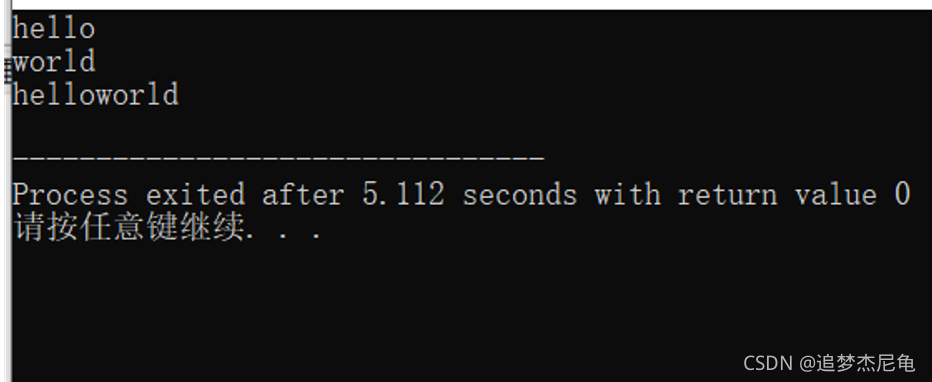
实现strcat函数
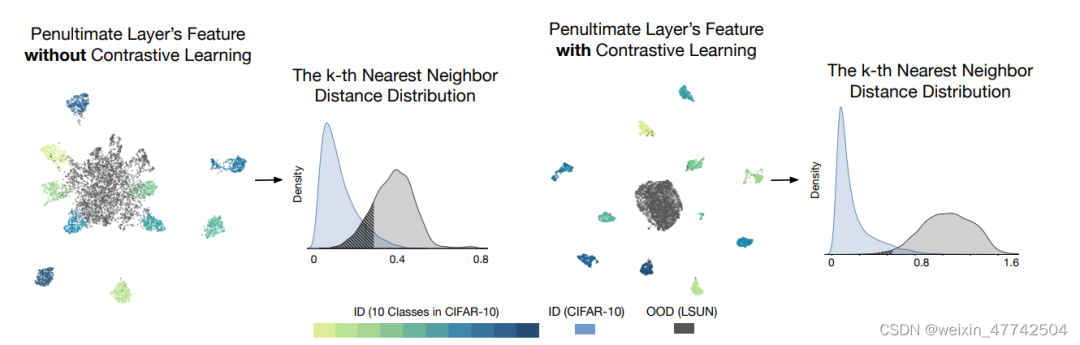
ICML 2022 | Out-of-Distribution Detection with Deep Nearest Neighbors
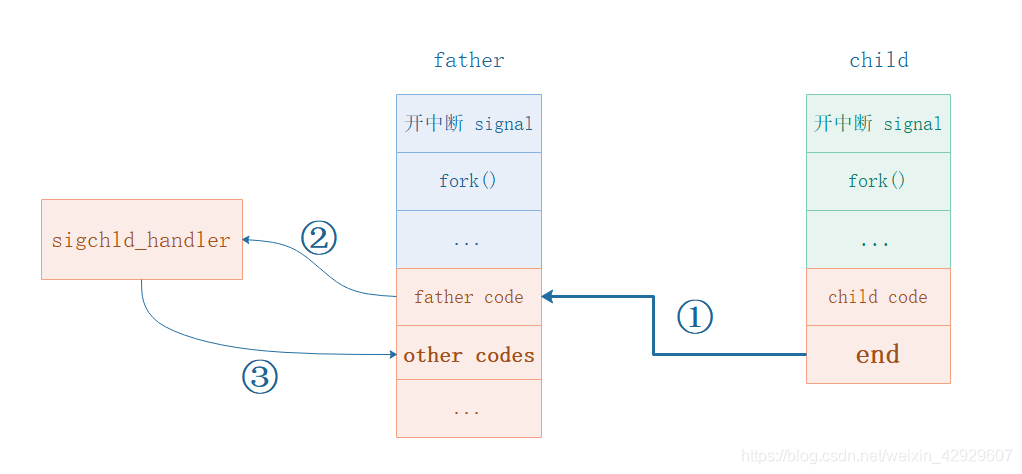
信号量SIGCHLD的使用,如何让父进程得知子进程执行结束,如何让父进程区分多个子进程的结束
1009 Product of Polynomials C语言多项式乘积(25分)
wpf path xaml写法和c#写法对比
[工程数学]1_特征值与特征向量
fork创建多个子进程
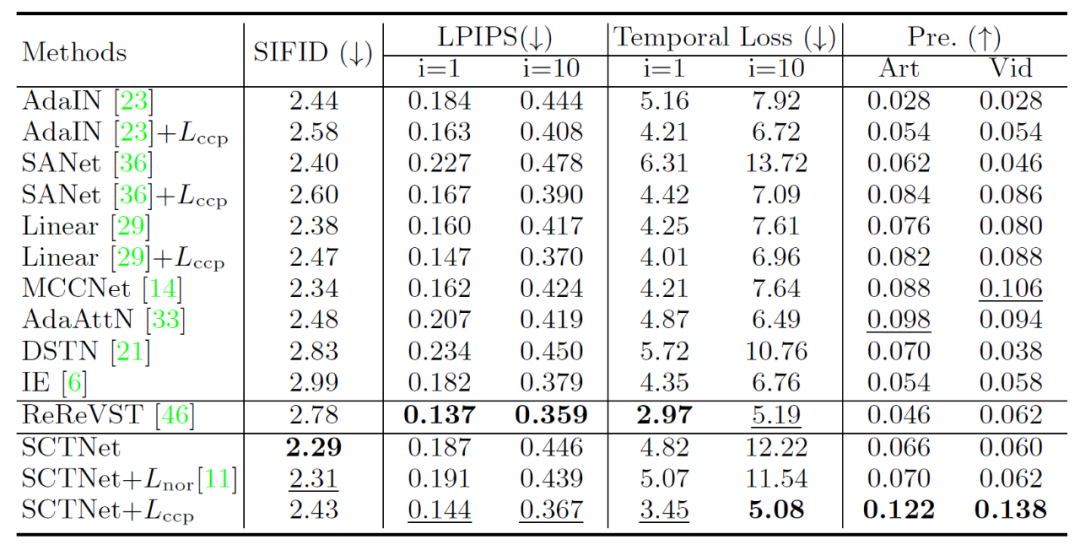
ECCV 2022 Oral | CCPL: 一种通用的关联性保留损失函数实现通用风格迁移
【VIBE: Video Inference for Human Body Pose and Shape Estimation】论文阅读
![[工程数学]1_特征值与特征向量](/img/9a/7ed63b86697d6f605d7fc9927496d9)
随机推荐
PAT1008
1007 Maximum Subsequence Sum (25分)
排序--快排(图解)
CentOS6.5 32bit安装Oracle、ArcSde、Apache等配置说明
ZOJ 1729 & ZOJ 2006(最小表示法模板题)
PAT1003
uni-app 自带的picker封装一个日期-时间选择器
Oracle数据库的两种进入方式
百钱买鸡(一)
matlab fcnchk 函数用法
enum in c language
People | How did I grow quickly from programmer to architect?
激光条纹中心提取——Steger
富媒体在客服IM消息通信中的秒发实践
bit、byte、KB、M、G、T相互关系
gdb tui的使用
Beauty Values
PAT1005
grpc系列-初探grpc 路由注册和转发实现
去除蜂窝状的噪声(matlab实现)