当前位置:网站首页>《Show and Tell: A Neural Image Caption Generator》论文解读
《Show and Tell: A Neural Image Caption Generator》论文解读
2022-08-11 05:35:00 【KPer_Yang】
目录
参考论文:
Show and tell: A neural image caption generator | IEEE Conference Publication | IEEE Xplore
[1411.4555] Show and Tell: A Neural Image Caption Generator (arxiv.org)
MobileNetV2: Inverted Residuals and Linear Bottlenecks | IEEE Conference Publication | IEEE Xplore
图像-字幕生成模型
模型总览:
从图1中可以明显的看到image首先经过CNN结构的特征提取器,再将提取的特征传入LSTM网络,由LSTM网络生成句子。注意图中右边的LSTM是LSTM的展开(unrolled)形式,也就是按照词的序列顺序展开。

图1 总网络架构
展开的模型使用公式表示如下:

公式中的I表示图像;表示第t个词,使用长度是字典大小的one-hot编码表示 ,注意
表示起始词;
表示停止词,当遇到停止词时,LSTM生成一个句子;
表示词嵌入。这样,图像使用视觉 CNN,单词使用单词嵌入,图像和单词都映射到同一个空间。图像I只再t-1时候使用一次,后面的N个时间步都不使用I,因为实验发现会带来过拟合的问题。
LSTM部分:
LSTM网络由输入门、输出门、遗忘门组成。
LSTM的具体公式如下所示:

图像特征提取部分:
图像特征提取可以使用Resnet、GoogleNet、MobileNet、EfficientNet等网络。例如MobileNetV2的网络结构如下:但是需要注意将网络的最后softmax层去掉,连接上需的长度的MLP,将其作为LSTM的输入。

损失函数定义
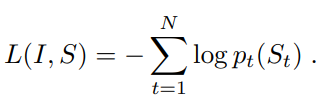
损失函数的定义其实如图1中所示,在每个时间步将LSTM的输出经过softmax(),然后求log()取负数得到。
边栏推荐
猜你喜欢


随机推荐
AUTOMATION DAY06( Ansible进阶 、 Ansible Role)
AUTOMATION DAY07 (Ansible Vault, ordinary users use ansible)
The ramdisk practice 1: the root file system integrated into the kernel
Sturges规则
CLUSTER DAY03( Ceph概述 、 部署Ceph集群 、 Ceph块存储)
torch.cat()用法
Arcgis小工具_实现重叠分析
Open Set Domain Adaptation 开集领域适应
vnc远程桌面安装(2021-10-20日亲测可用)
配置dns服务
ETCD cluster fault emergency recovery - to recover from the snapshot
arcgis填坑_4
八股文之jvm
华为防火墙-5-NAT
HCIP MGRE\OSPF Comprehensive Experiment
HPC平台搭建
HCIP OSPF/MGRE Comprehensive Experiment
本地yum源搭建
SECURITY DAY03 (one-click deployment of zabbix)
MySQL01