当前位置:网站首页>ETCD Single-Node Fault Emergency Recovery
ETCD Single-Node Fault Emergency Recovery
2022-08-11 07:04:00 【!Nine thought & & gentleman!】
系列文章目录
ETCDContainerized to build clusters
文章目录
前言
生产环境中,经常遇到etcd集群出现单节点故障或者集群故障.针对这两种情况,进行故障修复.本文介绍etcd的单节点故障时,Emergency recovery manual
一、总体恢复流程
由于etcd的raft协议,The number of failed nodes that the entire cluster can tolerate is (n-1)/ 2,So in the event of a single node failure,A single cluster is still available,It will not affect the reading and writing of the business.
整体的恢复流程如下
二、Detailed recovery instructions
2.1 环境信息
使用本地的vmstation创建3个虚拟机,信息如下
| 节点名称 | 节点IP | 节点配置 | 操作系统 | Etcd版本 | Docker版本 |
|---|---|---|---|---|---|
| etcd1 | 192.168.82.128 | 1c1g 20g | CentOS7.4 | v3.5 | 13.1 |
| etcd2 | 192.168.82.129 | 1c1g 20g | CentOS7.4 | v3.5 | 13.1 |
| etcd3 | 192.168.82.130 | 1c1g 20g | CentOS7.4 | v3.5 | 13.1 |
假设etcd2节点异常,And the local data has been corrupted.
2.2 The cluster deletes the abnormal node
通过member removeCommand to delete abnormal nodes,At this point the entire cluster has only 2个节点,不会触发master重新选主,集群正常运行.
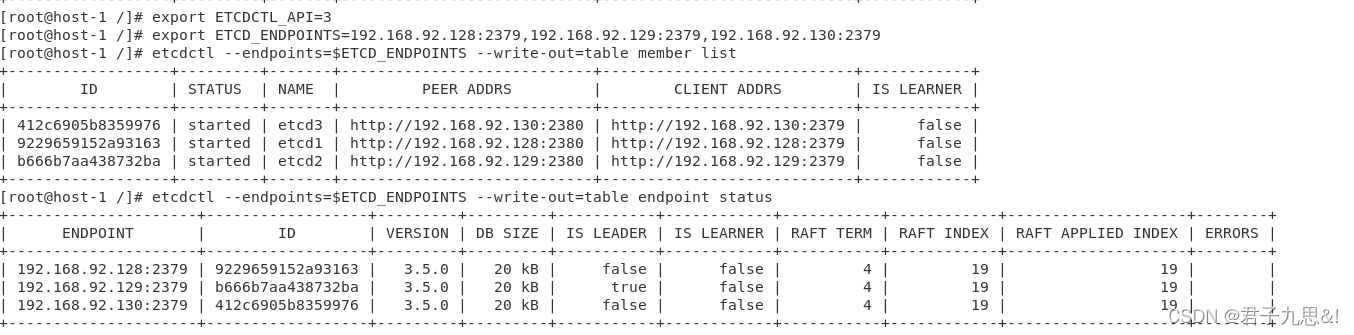
查看当前集群状态
export ETCDCTL_API=3
export ETCD_ENDPOINTS=192.168.92.128:2379,192.168.92.129:2379,192.168.92.130:2379
etcdctl --endpoints=$ETCD_ENDPOINTS --write-out=table member list
etcdctl --endpoints=$ETCD_ENDPOINTS --write-out=table endpoint status
2.2 Delete abnormal node data
2.2.1 删除异常member
docker stop etcd2
2.2.2 删除数据
由于数据通过-v /data/etcd:/data/etcd的方式挂载,Therefore delete the corresponding data,会清理etcd数据.
rm -rf /data/etcd/*
2.3 Re-add nodes to the cluster
通过如下命令,Add the abnormal node to the cluster,Wait for the corresponding node to start,Cluster data synchronization and master selection are automatically completed
export ETCDCTL_API=3
export ETCD_ENDPOINTS=192.168.92.128:2379,192.168.92.129:2379,192.168.92.130:2379
etcdctl --endpoints=$ETCD_ENDPOINTS member add etcd2 --peer-urls=http://192.168.92.129:2380

2.4 启动节点
2.4.1 The complete startup script is
[[email protected] ~]#
[[email protected] ~]# cat start_etcd.sh
/bin/sh
name="etcd2"
host="192.168.92.129"
cluster="etcd1=http://192.168.92.128:2380,etcd2=http://192.168.92.129:2380,etcd3=http://192.168.92.130:2380"
docker run -d --privileged=true -p 2379:2379 -p 2380:2380 -v /data/etcd:/data/etcd --name $name --net=host quay.io/coreos/etcd:v3.5.0 /usr/local/bin/etcd --name $name --data-dir /data/etcd --listen-client-urls http://$host:2379 --advertise-client-urls http://$host:2379 --listen-peer-urls http://$host:2380 --initial-advertise-peer-urls http://$host:2380 --initial-cluster $cluster --initial-cluster-token tkn --initial-cluster-state existing --log-level info --logger zap --log-outputs stderr
注意,由于etcd的数据已经被删除,So when the current node restarts,Get data from other nodes,因此需要调整参数–initial-cluster-state,从new改成existing
--initial-cluster-state existing
2.4.2 查看日志
docker logs 8bf31834f8ce
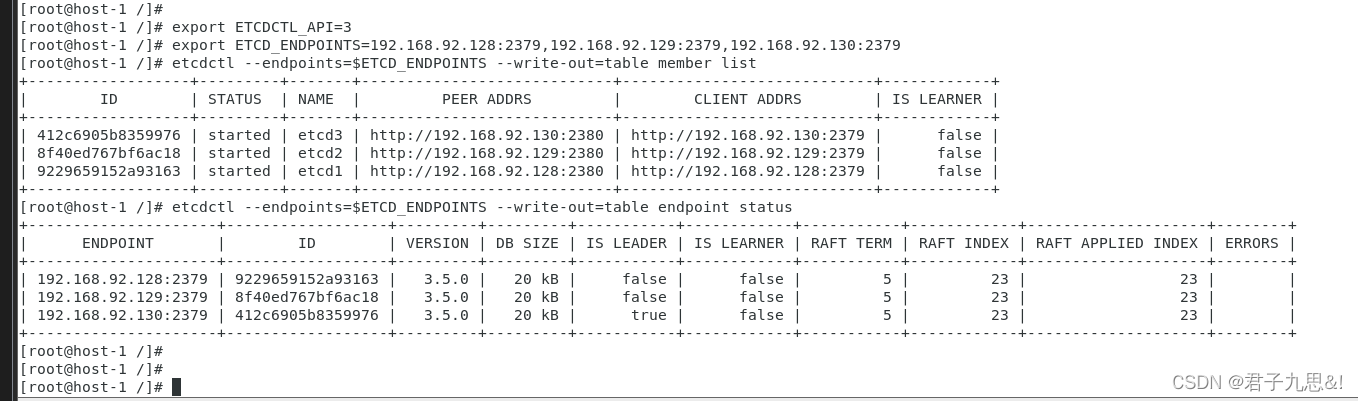
2.4 Wait for the cluster data to finish syncing and recover
查看当前集群的member信息
export ETCDCTL_API=3
export ETCD_ENDPOINTS=192.168.92.128:2379,192.168.92.129:2379,192.168.92.130:2379
etcdctl --endpoints=$ETCD_ENDPOINTS --write-out=table member list
etcdctl --endpoints=$ETCD_ENDPOINTS --write-out=table endpoint status
总结
Because the overall cluster has multiple copies,So when a single node is abnormal,It does not cause the entire cluster to be abnormal,It can be recovered as long as the corresponding node is started normally and the data is synchronized.
边栏推荐
- 文本三剑客——sed 修改、替换
- HCIP MGRE\OSPF综合实验
- Es常用操作和经典case整理
- Windos10专业版开启远程桌面协助
- SECURITY DAY03(一键部署zabbix)
- buildroot setup dhcp
- ansible batch install zabbix-agent
- Solve the problem that port 8080 is occupied
- SECURITY DAY03 (one-click deployment of zabbix)
- SECURITY DAY04 (Prometheus server, Prometheus monitored terminal, Grafana, monitoring database)
猜你喜欢
(3) Software testing theory (understanding the knowledge of software defects)

消息中间件

SECURITY DAY04 (Prometheus server, Prometheus monitored terminal, Grafana, monitoring database)
deepin v20.6+cuda+cudnn+anaconda(miniconda)
(1) Software testing theory (0 basic understanding of basic knowledge)

HCIP--交换基础
arcgis填坑_3
FusionCompute8.0.0实验(1)CNA及VRM安装
MoreFileRename batch file renaming tool

【LeetCode】851.喧闹与富有(思路+题解)
随机推荐
VMware workstation 16 installation and configuration
AUTOMATION DAY06 (Ansible Advanced, Ansible Role)
arcgis填坑_1
照片的35x45,300dpi怎么弄
Threatless Technology-TVD Daily Vulnerability Intelligence-2022-7-27
内存调试工具Electric Fence
CLUSTER DAY04 (Block Storage Use Cases, Distributed File Systems, Object Storage)
What should I do if I forget the user password in MySQL?
lvm 多盘挂载,合并使用
SECURITY DAY03 (one-click deployment of zabbix)
bash的命令退出状态码
Memory debugging tools Electric Fence
文本三剑客——grep过滤
解决8080端口被占用问题
华为防火墙-6
iptables 流量统计
FusionCompute8.0.0 实验(2)虚拟机创建
mysql数据库安装教程(超级超级详细)
iptables入门
Record a Makefile just written