当前位置:网站首页>Map Reduce
Map Reduce
2022-08-11 05:33:00 【weixin_45512368】
文章目录
Map Reduce 简介
Map Reduce 是Hadoop的核心出组成框架,使用该框架编写的应用程序能够在一种可靠、容错的方式并行处理大型集群(数千个节点)上的大量数据(TP级别以上),也可以对大数据进行加工、挖掘、和优化等处理。
一个 Map Reduce 任务主要包括两个部分:Map任务和Reduce的任务,Map任务负责对数据的获取和分割以及处理,其核心执行方法为Map()方法;Reduce任务负责对Map任务的结果进行汇总,其核心执行的方法为reduce()方法。Map Reduce将并行计算过程高度抽象到了map()方法和reduce()方法中,所以只需要对这两个方法将进行程序的编写工作,而并行程序中的其它复杂问题(比如 分布式存储、工作调度、负载均衡、容错处理等)均可由Map Reduce框架代为处理
1、设计思想
Map Reduce的设计思想是,从HDFS中获得输入数据,将输入的一个大的数据集分割成错个小数据集然后并行每个小数据集的结果进行汇总,得到最终的计算结果
在Map Reduce并行计算中,对大数据集分割后的小数据集进行计算,采用的是map()方法,各个map()方法对输入的数据进行并行处理,对不同的输入数据产生不同的输出结果:而对小数据集最终结果的合并,采用的是reduce()放法,各个reduce()方法也各自进行并行计算,各自负责处理不同的数据集合,但是在reduce()方法处理之前,必须等到map()方法处理完毕,因此在数据进入到reduce()方法之前需要一个中间阶段,负责对map()方法的输出结果进行整理,将整理后的结果输入到reduce()方法,这个中间阶段叫做Shuffle阶段
此外,进行Map Reduce计算时,有时候需要把最终的数据输出到不同的文件中,比如,按照省份划分的话,需要把同一个省份的数据输出到一个文件中,按照性别划分的话,需要把同一性别的数据输出到一个文件中,因为我们都知道,最终的输出数据来自reduce任务,如果要得到多个文件,意味着有同样数量的Reduce任务在运行,而Reduce任务的数据来自于Map任务,也就是说,Map任务要进行数据划分,对于不同的数据分配给不同的Reduce任务执行,Map任务划分数据的过程就称作分区(Partition)
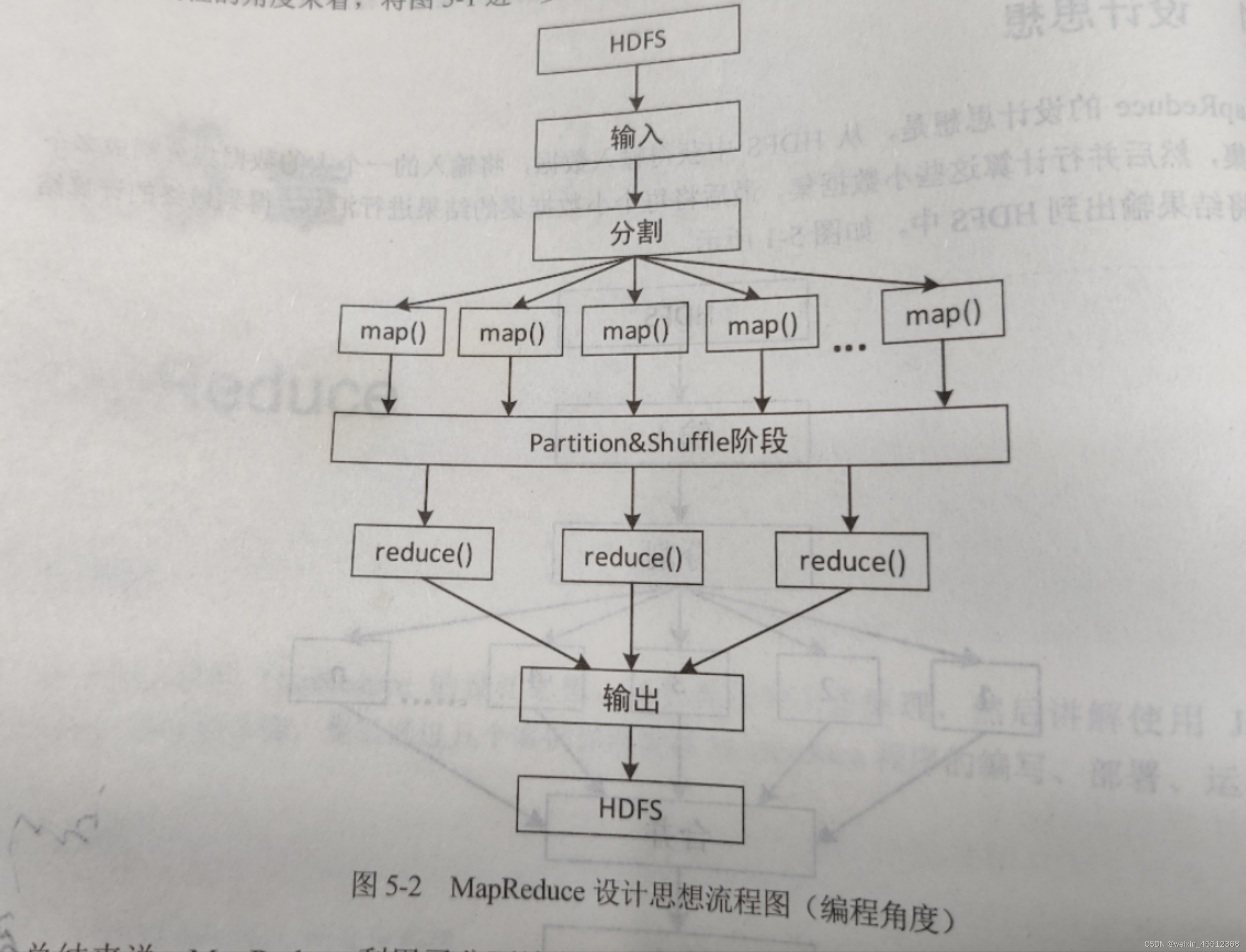
总的来说,Map Reduce利用了分而治之的思想,将数据分布式并行处理,然后进行结果汇总
2、 任务流程
Map Reduce程序运行在于YARN上,使用YARN进行集群资源管理和调度,每个Map Reduce应用程序会在YARN中产生一个名为"MRAppMaster"的进程,该进程是Map Reduce的Application实现,它具有YARN中的ApplicationMaster角色的所有功能,包括管理整个Map Reduce应用程序的生命周期,任务资源申请,Cintainer启动和释放等
客户端将Map Reduce应用程序(jar、可执行文件等)和配置信息提交给YARN集群的Resource Manager,Resource Manager 负责将应用程序和配置信息分配给Node Manager、调度和监控任务、向客户端提供状态和诊断信息等
执行流程图
1.客户端提交Map Reduce应用程序到Resource Manager
2.Resource Manager分配用于运行MRAppMaster的Container,然后与Node Manager通信,要求他在该Container中启动MARApp Master,MARApp Master启动后,他负责此应用程序的整个生命周期
3.MARApp Master向Resource Manager注册(注册客户端可以通过Resource Manager查看用用程序的运行状态)并请求运行应用程序各个Task所需的Container(资源请求是对一些Container的请求),如果符合条件,Resource Manager会分配给MARApp Master所需的Container
4.MARApp Master请求Node Manager使用这些Container来运行应用程序的相应Task(即将Task发布到指定的Container中运行)
此外,各个运行中的Task会通过RPC协议向MRAppMaster汇报自己的状态和进度,这样一旦某个Task运行失败时,MRAppMaster可以对其进行重启,当应用程序运行完毕时,MRAppMaster会向Resource Manager申请注销自己
3、工作原理
Map Reduce计算模型主要有三个阶段组成:Map阶段、Shuffle阶段、Reduce阶段,
通过Map任务读取HDFS上的数据,这些数据块由Map任务已完全并行的方式处理,然后将Map任务的输出进行排序后输入到Reduce任务中;最后Reduce任务将计算的结果输出到HDFS文件系统中
此时,Map任务的nap()方法和Reduce任务的reduce()方法需要用户自己定义实现
如图
1、Map阶段的工作原理如下:
将数据的多分片(Split)有Map任务已完成并行的方式处理,每个分片由一个Map任务来处理,默认情况下数据分片的大小与HDFS中数据块(Block)的大小是相同的,即文件有多少个数据块就有多少个输入分片,也就会有多少个Map任务,从而可以通过调整HDFS数据块的大小来间接改变Map任务的数量
每个Map任务对输入分片中的纪录按照一定的规则解析成多个<key,value>对,默认将文件中的每一行文本内容解析成一个<key,value>对,key为每一行得起始位置,value为本行的文本内容,然后将解析出的所有<key,value>对分别输入到Map方法中处理(Map()方法一次只处理一个<key,value>对),map()方法将处理结果仍然是<key,value>对的形式进行输出
由于频繁的磁盘I/O会降低效率,因此Map任务输出的 <key,value>对会首先存储在Map任务所在的节点上(不同的Map任务可能运行在不同的节点)的内存缓存区中,缓存区默认的大小为100MB(可修改mapreduce.task.io.sort.mb 属性调整),当缓冲区的数据量达到预先设置阈值后(mapreduce.map.sort.spill.percent 属性的值,默认是0.8 即80%),便会将缓冲区的数据溢写(spill)到磁盘(mapreduce.cluster.local.dir 属性指定的目录,默认是${hadoop.tmp.dir}/maperd/local)的临时文件中
在数据溢写到磁盘之前,会对数据进行分区(Partition),分区的数量与设置的Reduce任务的数量相同(默认Reduce任务的数量是1,可以在编写Map Reduce程序时对其进行修改),这样每个Reduce任务会处理一个分区的数据,可以防止有的Reduce任务分配的数据量太大,而有的Reduce任务分配的数据量太小,从而可以负载均衡,避免数据倾斜,数据分区划分的规则为:取<key,value>对中key的hashCode值,然后除以Reduce任务数据量后取余数,余数则是分区编号,分区编号一致的<key,value>对则属于同一个分区,因此key值相同的<key,value>对一定属于同一个分区,但是同一个分区中可能有多个key值不同的<key,value>对,由于默认Reduce任务的数量为1,而任何数字除以1的余数总是0,因此分区编号是从0开始
Map Reduce提供默认分区类为Hash Partition,该类的核心代码如下:
public class HashPartitioner<k2,v2> implements Parttitioner<k2,v2>{
/** 获取分区编号*/
public int getPartition(K2 kwy,V2 value, int numReduceTasks){
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
2、Reduce 阶段
reduce阶段首先会对Map阶段的输出结果按照分区进行一次合并,将同一分区的<key,value>对合并到一起,然后按照key对分区中的<key,value>对进行排序
每个分区会将排序后的<key,value>对按照key进行分组,key相同的<key,value>对将合并为<key,value-list>对,最终每个分区形成多个<key,value-list>对
排序分组后的分区数据会输到reduce()方法中进行处理,reduce()方法一次只能处理一个<key,value-list>对
最后,reduce()方法将处理结果仍然以<key,value>对的形式通过context.write(key,value)进行输出
3、shuffle 阶段
shuffle阶段所处的位置是在Map任务输出后,Reduce任务接受前,shuffle阶段主要是将Map任务无规则输出形成一定的有规则数据,以便Reduce任务进行处理
边栏推荐
- slurm集群搭建
- 记录一个刚写的Makefile
- Threatless Technology-TVD Daily Vulnerability Intelligence-2022-7-29
- visio文件批量转pdf
- Es common operations and classical case
- FusionCompute8.0.0实验(1)CNA及VRM安装
- 局域网文件传输
- 项目笔记——随记
- No threat of science and technology - TVD vulnerability information daily - 2022-7-21
- CLUSTER DAY03( Ceph概述 、 部署Ceph集群 、 Ceph块存储)
猜你喜欢

随机推荐
Threatless Technology-TVD Daily Vulnerability Intelligence-2022-7-22
CLUSTER DAY04(块存储应用案例 、 分布式文件系统 、 对象存储)
mongo-express 远程代码执行漏洞复现
Memory debugging tools Electric Fence
MoreFileRename批量文件改名工具
lvm multi-disk mount, combined use
C语言两百题(0基础持续更新)(1~5)
HPC platform building
文本三剑客——sed 修改、替换
VMware workstation 16 安装与配置
ETCD集群故障应急恢复-本地数据可用
SECURITY DAY05(Kali系统 、 扫描与抓包 、 SSH基本防护、服务安全 )
无胁科技-TVD每日漏洞情报-2022-7-19
Threatless Technology-TVD Daily Vulnerability Intelligence-2022-7-30
uboot sets the default bootdelay
Threatless Technology-TVD Daily Vulnerability Intelligence-2022-7-19
无胁科技-TVD每日漏洞情报-2022-8-5
无胁科技-TVD每日漏洞情报-2022-7-20
vulnhub靶机--6Day_Lab-v1.0.1
cloudreve使用体验