当前位置:网站首页>什么是Inductive learning和Transductive learning
什么是Inductive learning和Transductive learning
2022-08-11 05:35:00 【Pr4da】
1. Inductive learning
Inductive learning (归纳式学习)。归纳是从已观测到的数据到一般数据的推理,归纳学习即我们平时所说的监督学习,使用带有标签的数据进行模型训练,然后使用训练好的模型预测测试集数据的标签,训练集数据不包含测试集数据。
2. Transductive learning
Transductive learning (直推式学习)。直推是从观测到的特定数据到特定数据的推理。直推学习与归纳学习不同的是,训练数据和测试数据在之前都已经可以观测,我们从已知的训练数据学习特征来预测测试集标签。即使我们不知道测试集的标签,我们也可以从学习过程中利用数据中的特征或其它信息来进行推理。换言之,直推式学习是用训练集数据和测试集数据共同训练模型,然后再用测试集数据进行测试。
3. 两种方法的差异
两种学习方法最明显的差异就是在Transductive learning中,训练数据和测试数据都是可观测的,而在Inductive learning中测试数据是你事先并不知道的。
Transductive learning不能构建预测模型,当测试集来了新数据后我们需要重新运行算法从头开始学习,然后预测测试集标签。而Inductive learning构建了一个预测模型,当测试集来了新数据后可以直接来进行预测。
简单来讲,Inductive learning构建了一个一般模型,可以根据可观测数据(训练数据)来预测任意新的数据。相反,Transductive learning构建了一个只适用于可观测预测数据和测试数据的模型。
我们用一张表来总结这一差异:
| Inductive learning | Transductive learning |
|---|---|
| 可以标记从未出现过的数据 | 仅能标记已出现过的数据 |
| 能够构建预测模型,当出现新的测试数据可以用预测模型直接预测标签 | 不能构建预测模型,当出现新的测试数据需要重新运行整个算法 |
| 可以预测空间中任意未标记数据 | 仅能预测基于训练集学习的数据 |
| 计算量小 | 计算量大 |
4. 示例说明
假设我们有如下数据,其中有是4个数据(A, B, C, D)是有标签的(红色和绿色),剩下14个数据是不带有标签的。我们需要用这4个带标签的数据来预测这剩下14个数据的分类(颜色)。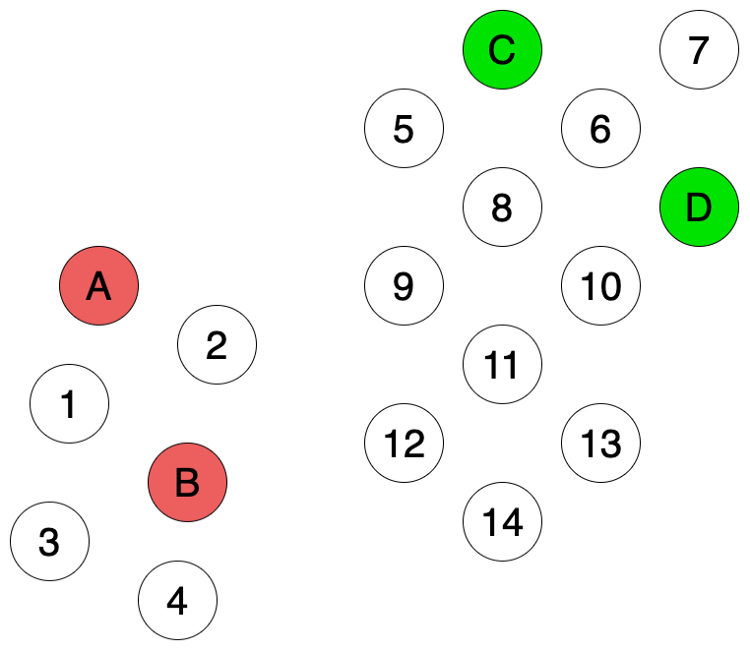
如果采用Inductive learning,我们需要使用这4个标记数据构建监督学习模型。但由于训练数据太少,我们构建的模型不能准确反映数据的结构。我们使用了近邻域算法,从图上来看,相比于C和D,12和14两个数据似乎离A和B要更近一点,所以我们得到的预测结果就会如下图Fig 2所示。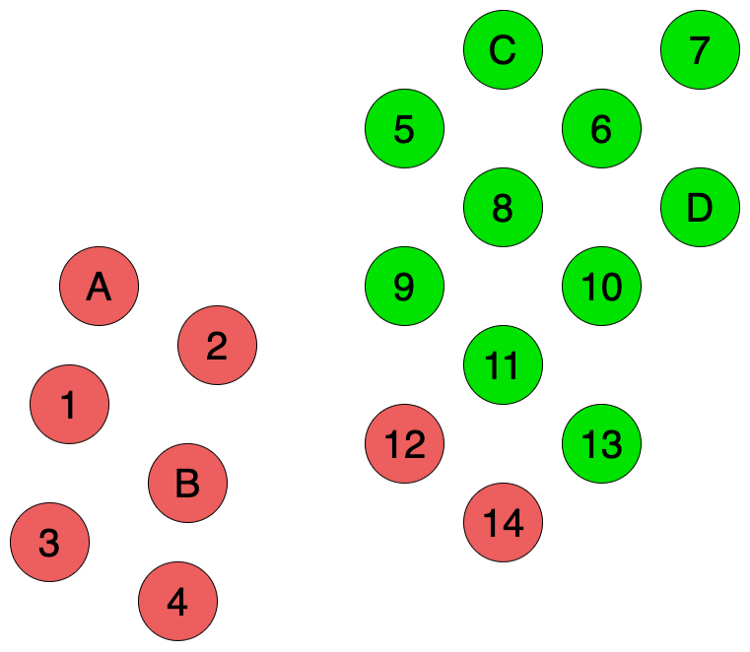
如果我们有一些额外信息,比如两两数据点间的相似性,相似就用线把两个点连接起来(如图 Fig 3所示)。我们可以使用这些额外信息来帮助我们标记未知数据。
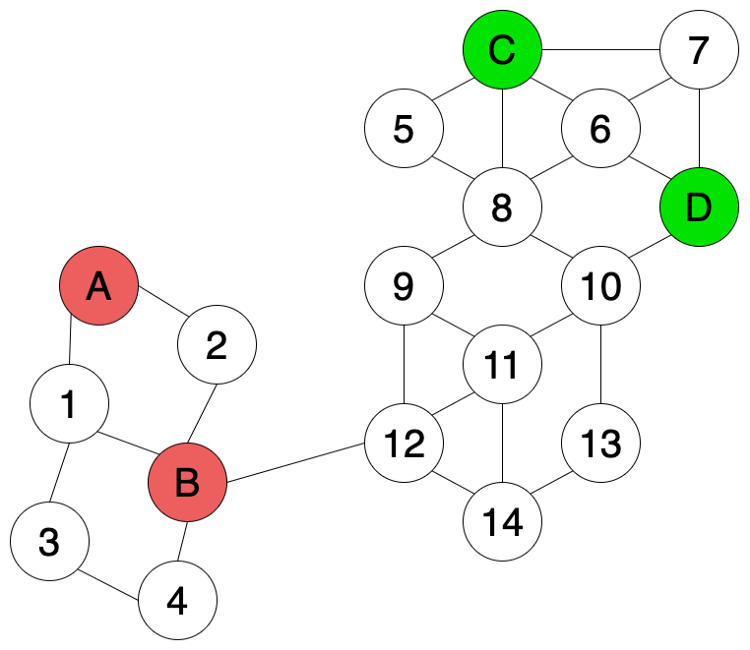
在transductive learning方法中,我们可以使用semi-supervised graph-based label propagation algorithm来标记未知数据,如图4所示。除了已知标签数据之外(A,B,C,D),无标签数据的特征信息(数据间的相似性)同样帮助了我们对标签进行预测。由于12和14两个数据点和绿色的数据连接的更多,所以我们推测12和14更有可能是绿色而不是红色。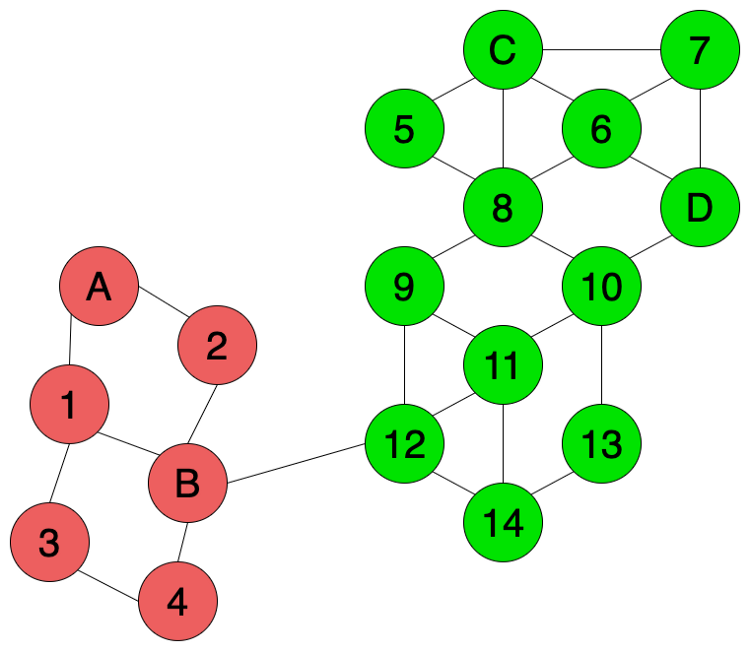
因此,如果我们已知训练数据和测试数据,我们可以使用transductive learning;如果我们只知道训练数据,我们不得不采用Inductive learning.
参考:
[1] Inductive vs. Transductive Learning
[2] 理解直推式学习和归纳式学习
边栏推荐
猜你喜欢




随机推荐
arcgis填坑_3
SECURITY DAY02 (Zabbix alarm mechanism, Zabbix advanced operation and monitoring case)
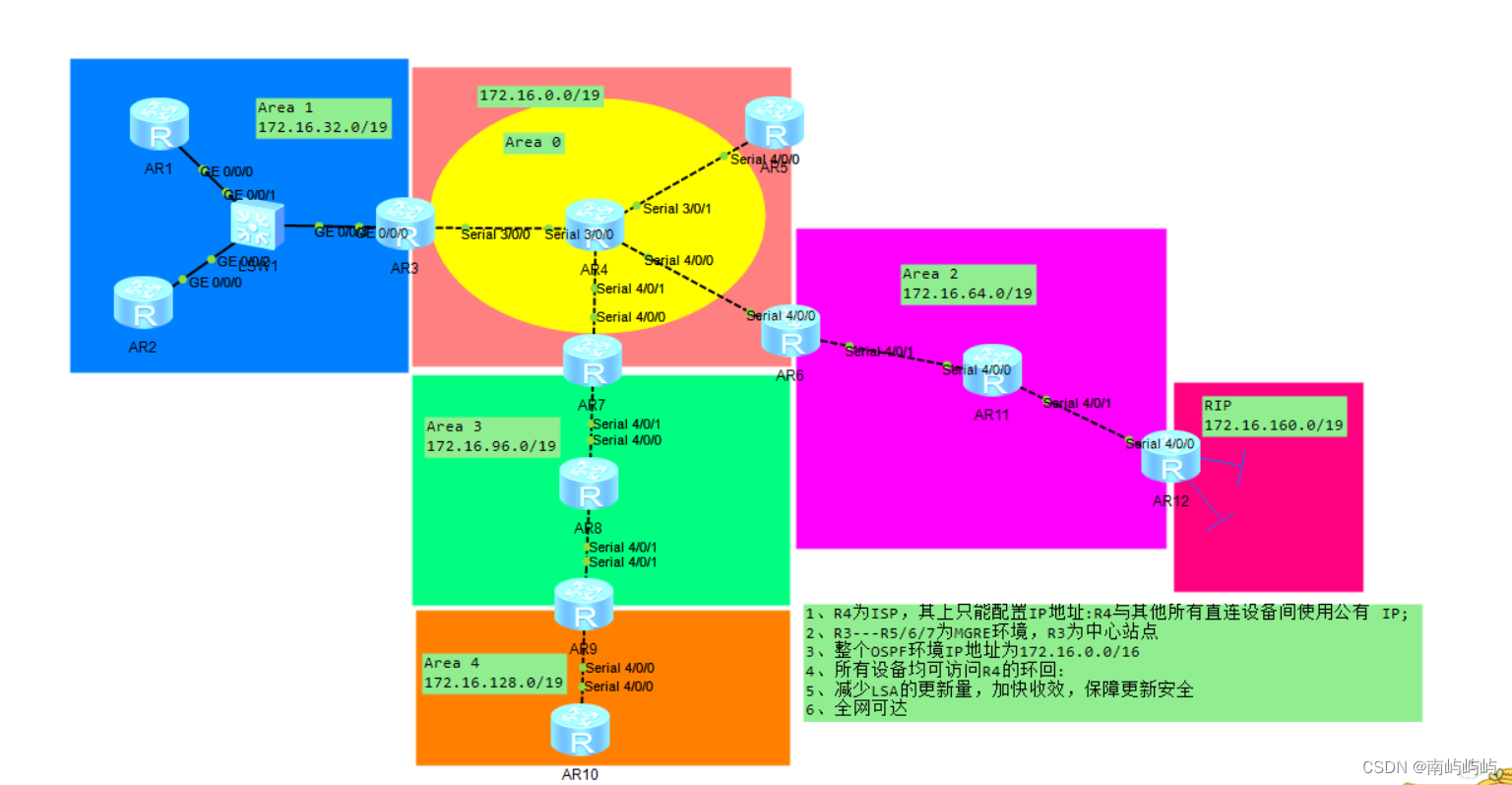
HCIP实验(pap、chap、HDLC、MGRE、RIP)
安装cuda10.2下paddlepaddle的安装
OA项目之我的会议(会议排座&送审)
升级到Window11体验
buildroot setup dhcp
(2) Software Testing Theory (*Key Use Case Method Writing)
CLUSTER DAY01 (Introduction to cluster and LVS, LVS-NAT cluster, LVS-DR cluster)
华为防火墙会话 session table
HCIP-生成树(802.1D ,标准生成树/802.1W : RSTP 快速生成树/802.1S : MST 多生成树)
vnc remote desktop installation (available for personal testing on 2021-10-20)
iptables的状态
华为防火墙-4-安全策略
HCIP BGP neighbor building, federation, and aggregation experiments
记录一个刚写的Makefile
uboot设置默认的bootdelay
CLUSTER DAY02( Keepalived热备 、 Keepalived+LVS 、 HAProxy服务器 )
The ramdisk practice 1: the root file system integrated into the kernel
HCIP OSPF/MGRE综合实验