当前位置:网站首页>Source code analysis of how to use jump table in redis
Source code analysis of how to use jump table in redis
2022-04-23 05:17:00 【Magic circle】
Preface
Alibaba cloud's spring school recruitment test this year , Interviewer asked Redis How to use the jump table in ? It's a headache for many students to arrive . Let's talk about it today .
Sorted Set Structure
redis An ordered collection of data types (sorted set) Very widely used , It has the function of collection , At the same time, it can support the collection with weight , And sort by weight . It can go through ZRANGEBYSCORE Returns a range of elements according to their weight , Or by ZSCORE Returns the weight value of an element . It can return the weight of the element with constant complexity , I believe many children's shoes can think of using hash table index . How to support range query ? Then we have to talk about today's key jump table . And think again , How do they combine ?
Let's have a look at sorted set Structure
typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset;
From the structure , It can be seen that the purpose of using jump table is to efficiently support range query ( such as ZRANGBYSCORE operation ), The efficient single point query uses hash structure ( such as ZCORE) operation . So let's see Redis How to implement the skip table of .
Design and implementation of skip table
Jump watch (skiplist) In fact, it is a multi-layer ordered linked list . The jump table is sorted from low to high , Lowest lower floor level0, Up there are level1,level2 etc. . Is in O(log(n)) Add... In time 、 Delete 、 The data structure of the search operation . It can be said to be an alternative structure of balanced tree , But unlike red and black trees , Its implementation of balanced tree is based on a randomized algorithm .
So let's see zskiplist The implementation of the
typedef struct zskiplistNode {
sds ele;
// The weight
double score;
// Back pointer
struct zskiplistNode *backward;
level Array
struct zskiplistLevel {
// Forward pointer
struct zskiplistNode *forward;
// span , Records span level0 Several nodes on
unsigned long span;
} level[];
} zskiplistNode;
because sorted set That is to save the data , Also save the weight value . So in zkiplistNode See... In the definition sds Variable of type ele, as well as double Variable of type score.ele Saved element ,score Saved weights . Besides , In order to facilitate searching from the tail node of the jump table , Each hop table node also saves pointers backward, It points to the previous node .
Besides , Just mentioned that the jump list itself is a multi-layer ordered linked list , Therefore, each layer is connected by multiple nodes through pointers . Therefore, a... Is also included in the structure zskiplistLevel Structure type level Array .level Each element in the array defines a forward pointer (forward) Connect with subsequent nodes . Span is used to record on a certain layer foward The pointer between the node and level0 Several nodes on . for instance , So let's take this picture

In this example, the node 30 Of level The array has three elements , They correspond to three layers level The pointer , Besides ,level2,level1,level0 The corresponding spans are 3、2、1. and , Because the nodes in the jump table are arranged in order , Therefore, it can be based on each node in forward The span on the pointer is accumulated . This cumulative value can be used to calculate the order of the node in the whole hop table .
Next , Understand the definition of the next hop table , The head node and tail node of the jump table are defined in the jump table structure , The length of the skip table and the maximum number of layers of the skip table . The definition is as follows :
typedef struct zskiplist {
// The head and tail nodes of the jump table
struct zskiplistNode *header, *tail;
// Maximum length
unsigned long length;
// Maximum number of layers
int level;
} zskiplist;
Because each node in the hop table is connected by a pointer , Therefore, we only need to obtain the head node and tail node of the linked list, and then we can query each node of the jump table through the node pointer .
Jump table query
that , Now the jump table has been defined , Is it still like querying an ordinary linked list from the beginning one by one ? Of course not. , You can use... In the node level Array accelerated query .
When querying a node , The jump table will find the next node from the top of the node , Because the elements and weights are saved in the node , Therefore, when comparing nodes, the two should be compared .
1. When the weight of the node to be searched is smaller than that of the node to be searched , Then it will continue to access the next node of the layer .
2. When the weight of the node to be searched is equal to the weight of the node to be searched , Then continue to compare their values , If the search node data is smaller than the node data to be searched , The skip table will still access the next node of the layer .
When neither of these conditions is met , You will visit level The next pointer to the array , Then continue to find along the next pointer . It's equivalent to going to the next level and continuing to find . The specific code is as follows :
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--) {
...
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
{
...
x = x->level[i].forward;
}
The number of nodes in each layer of the hop table is about half that of the next layer , The advantage of this is that the search process is similar to binary search , Time complexity comes from O(n) Down to O(logN), But this method also has negative problems , That is, once there is a node to insert and delete . Then the nodes to be inserted and deleted and the layers of the nodes behind them need to be adjusted, resulting in additional overhead .
Here's an example
Suppose the current skip table has 4 Nodes ,1、7、13、21.
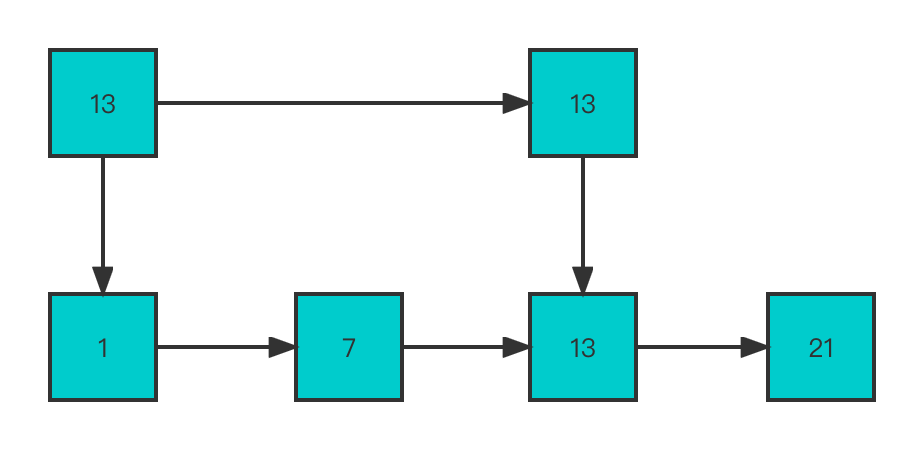
Then, if you insert multiple nodes , As shown in the figure below
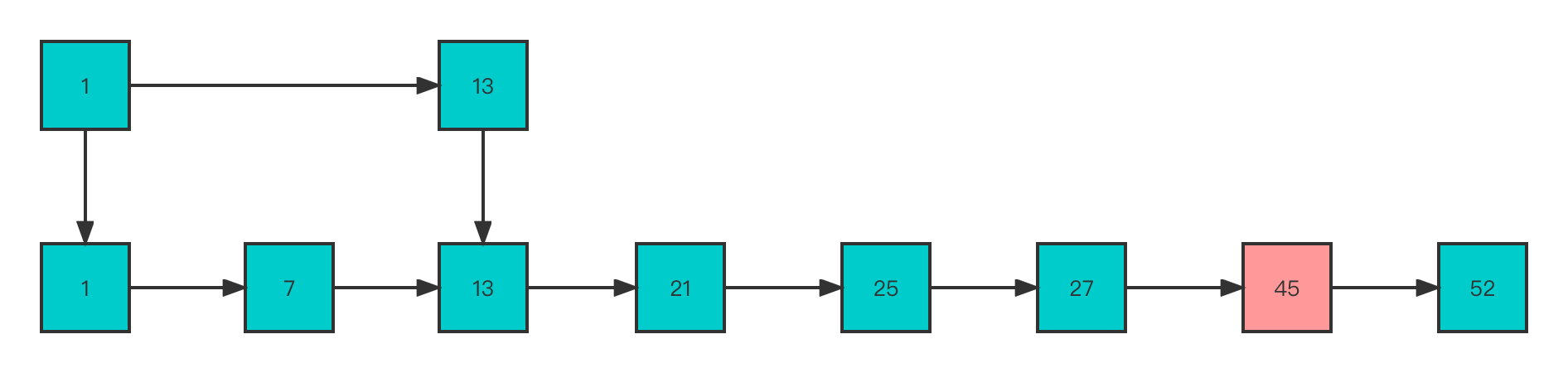
You can see that when multiple nodes are inserted , If it's looking for 45 This node needs to be in level 0 Search the nodes in order , The complexity is O(N) 了 . Now, in order to maintain the relationship between the number of adjacent nodes, it is modified as follows
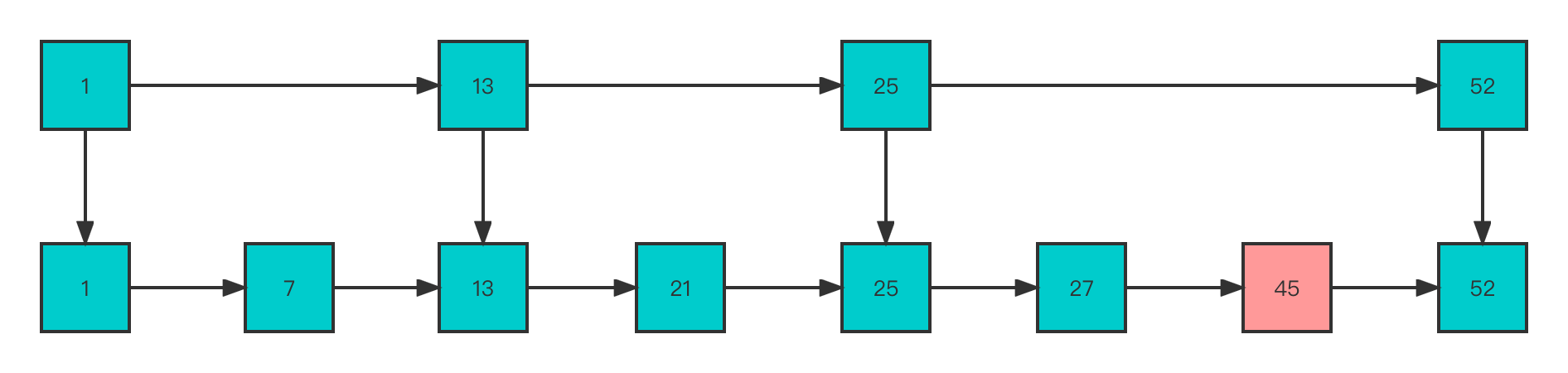
Find it like this 45 The time complexity is reduced , But it also brings additional costs . To avoid the above problems , When creating a node, the jump table , The method of randomly generating the number of node layers is adopted . At this time, the adjacent layers are not strictly in accordance with 2:1 The way , In this case , When inserting a new node , Just modify the pointer of the front and back nodes , The number of layers of other nodes does not need to be changed , This reduces the complexity of the insertion operation .
In the source code , The number of jump table node layers is determined by zslRandomLevel Function to determine . The code is as follows
int zslRandomLevel(void) {
static const int threshold = ZSKIPLIST_P*RAND_MAX;
int level = 1;
while (random() < threshold)
level += 1;
return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}
You can see zslRandomLevel The function initializes the number of layers to 1, This is also the minimum number of layers of nodes . And then generate random numbers , If the random number is less than ZSKIPLIST_P.ZSKIPLIST_P The definition is as follows
#define ZSKIPLIST_P 0.25
It represents the probability of increasing the number of layers by skipping the table , Then the number of layers increases 1 layer . Because the value of random number is [0,0.25) The probability within the range will not exceed 25%, So it also shows that the probability of adding one layer will not exceed 25%.
# summary
This article introduces Sorted Set The underlying implementation of data types .Sorted Set In order to support the query according to the weight range at the same time , And single point query for element weight , And single point query for element weight , In the bottom structure, the combination method of using jump table and hash table is designed .
A jump list is a multi-layer ordered linked list , When querying the jump table , It starts from the highest level , The higher the number of layers, the fewer nodes , If the high-level directly finds the node to be checked, it will directly return . If the first node larger than the element to be queried is found, the query will continue to the next level , Then continue to query in more nodes on the next layer . This design method of jump table saves query overhead , meanwhile , The skip table uses a random method to determine the number of layers of each node , This can avoid adding nodes , The chain reaction that causes other nodes to increase the number of layers .
版权声明
本文为[Magic circle]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204230510044916.html
边栏推荐
- 【openh264】cmake: msopenh264-static
- 如何在Word中添加漂亮的代码块 | 很全的方法整理和比较
- Pandas to_ SQL function pit avoidance guide "with correct code to run"
- Graphics.FromImage报错“Graphics object cannot be created from an image that has an indexed pixel ...”
- mysql5. 7. X data authorization leads to 1141
- 使用 Kears 实现ResNet-34 CNN
- Restful toolkit of idea plug-in
- Redis lost key and bigkey
- 了解 DevOps,必读这十本书!
- C. Tree infection (simulation + greed)
猜你喜欢

低代码和无代码的注意事项

Transaction isolation level of MySQL transactions

Servlet3 0 + event driven for high performance long polling

What are the reasons for the failure of digital transformation?
MySQL memo (for your own query)

看板快速启动指南

开源规则引擎——ice:致力于解决灵活繁复的硬编码问题

JSP-----JSP简介

Three 之 three.js (webgl)旋转属性函数的简单整理,以及基于此实现绕轴旋转的简单案例

了解 DevOps,必读这十本书!
随机推荐
了解 DevOps,必读这十本书!
Using PHP post temporary file mechanism to upload arbitrary files
Minimum spanning tree -- unblocked project hdu1863
To understand Devops, you must read these ten books!
The difference between static pipeline and dynamic pipeline
Good simple recursive problem, string recursive training
Publish your own wheel - pypi packaging upload practice
API slow interface analysis
My old programmer's perception of the dangers and opportunities of the times?
学习笔记:Unity CustomSRP-10-Point and Spot Shadows
【openh264】cmake: msopenh264-static
Deep learning notes - object detection and dataset + anchor box
MySQL memo (for your own query)
Harmonious dormitory (linear DP / interval DP)
DevOps生命周期,你想知道的全都在这里了!
好的测试数据管理,到底要怎么做?
Chapter II project scope management of information system project manager summary
Data security has become a hidden danger. Let's see how vivo can make "user data" armor again
Using MySQL with Oracle
如何在Word中添加漂亮的代码块 | 很全的方法整理和比较