本文作者:
字节,观远数据首席科学家.主导多个AI项目在世界500强的应用落地,多次斩获智能零售方向Hackathon冠军.曾就职于微策略,阿里云,拥有十多年的行业经验.
在之前的文章中,我们介绍过
The composition and construction of a cloud native machine learning platform
[1].在实际企业应用中,Machine learning platform relies heavily on the underlying enterprise data platform,虽然这两年 AI wave after wave of craze,But it is necessary to implement the algorithm application well,Very dependent on the infrastructure of the data platform.从
a16z Some analysis reports of
[2] 中也可以看出,Current data platform companies attracted very much of the market and the capital attention,也应运而生了
[3] 之类的概念.
Let's talk about what this article is the so-called cloud native data platform.
1. 发展历程
The earliest data platform comes from relational database(RDBMS)技术,from the outset to record business operations data OLTP 系统开始,Gradually developed to the business situation to do data analysis and further take decisions related to demand,也就是所谓的 OLAP 系统,Contains a lot of classic theory and technical methods.
在 1980 年代,The requirements to establish data warehouse system for data analysis(Data Warehouse)的设计方法,became the first generation“数据平台”系统.1992 年,著名的“数仓之父”Bill Inmon 出版了《Building the Data Warehouse》一书,Formed a set of methodology of top-down centralized to build enterprise series warehouse.另外一位大佬 Ralph Kimball 则在 1996 年出版了《The Datawarehouse Toolkit》一书,bottom-up based Data Mart concept to build enterprise-level data warehouse ideas.在上世纪 90 年代,The two bosses book practitioner is almost a required standard books,The concept of enterprise series storehouse also gradually began to spread,与 BI Analytical applications in a major enterprise wide adoption and deployment.The mainstream of the software system from each big commercial closed source software,如 IBM DB2,SQL Server,Teradata,Oracle 等.
到了 21 世纪初,The concept of the Internet began to rise,in data processing and analysis,“大数据”challenges also arise.The traditional number on the magnitude of the data warehouse technology is difficult to deal with the Internet age,Rapidly changing data structures,All kinds of semi-structured unstructured data storage and processing requirements.Three classic papers published from Google(MapReduce,GFS,BigTable)开始,The are different from the traditional relational database technology of distributed data system technology stack.This trend was later Hadoop Open source ecology flourishes,Formed a far-reaching influence in the industry for more than ten years.I remember going to various tech conferences,大家都在聊“数据湖”,NoSQL,SQL on Hadoop 等技术和理念,Internet companies have adopted data platform is mostly based on Hadoop This open source ecosystem(HDFS,Yarn,HBase,Hive 等)构建起来的.There are also famous Hadoop 三驾马车,Cloudera,Hortonworks 和 MapR.
随着 AWS Leading the rise of the cloud computing wave,大家越来越意识到 Hadoop Various issues with system architecture,Including storage and computing resource bindings,Very high difficulty and cost of operation and maintenance,Does not support streaming data processing well,交互式查询等.Cloud native era is a very big change everyone tends to reduce the cost of ownership of various system and operational cost,Professional services provided by cloud vendors.Another big trend is the extreme“弹性”The pursuit of ability,Such as now some cloud data warehouse can even be consumed by a single query computation rate.这些要求在 Hadoop Ecology is relatively difficult to achieve,So gradually emerged a new generation of the concept of cloud native data platform,It is also the main topic of this paper.
2. 数据平台架构
2.1 经典数仓架构
in the traditional perspective,The data platform is about equal to the data warehouse platform.所以只需要 ETL 工具,Load data from various data sources into data warehouses,然后用 SQL 做各种处理,转换,Build a data warehouse layered system,再通过 SQL The interface can provide external services:

traditional data platform
2.2 数据湖架构
但随着业务的发展,People gradually have more request for the ability of data platform,including the classic four V 中的几点:
Variaty,数据的多样性.
For example, it is necessary to store and process various semi-structured Json,Avro,ProtoBuf 类型的数据,or unstructured text,图像,音频,视频等.这些内容的处理,往往 SQL it will be more difficult to deal with.In addition, the demand side has become more diverse,除了 BI 类分析,AI Analytical Modeling Requirements for Classes,Business system on the results of the analysis of consumption are becoming more common, such as.
Volume,数据的量级.
As business goes online,数字化的转变,Data-driven thinking is gaining ground,Modern enterprises need to store and process data scale is becoming more and more big.Although the number of traditional commercial warehouse software can support scale,But often its architecture is bound to storage and computing,This results in a very huge cost.This is a very significant differences in modern data platform.
Velocity,The rate of change of data.
In some data application scenarios,Gradually began to appear the automated real-time decision-making needs.For example, after a user browses some products,System can get the new behavior data and real-time update user recommendations;Or in combination with the user in the last few minutes of an act of automatic control audit risk decision-making, etc.在这种情况下,传统的 T+1 Number in the form of warehouse operation obviously couldn't meet the demand.
Driven by these needs,Data platform architecture toward a more complex structure evolution,Also introduced many famous large data system components, such as Hadoop,Spark 等.其中比较知名的有 Storm 作者 Nathan Marz 提出的 Lambda Architecture:
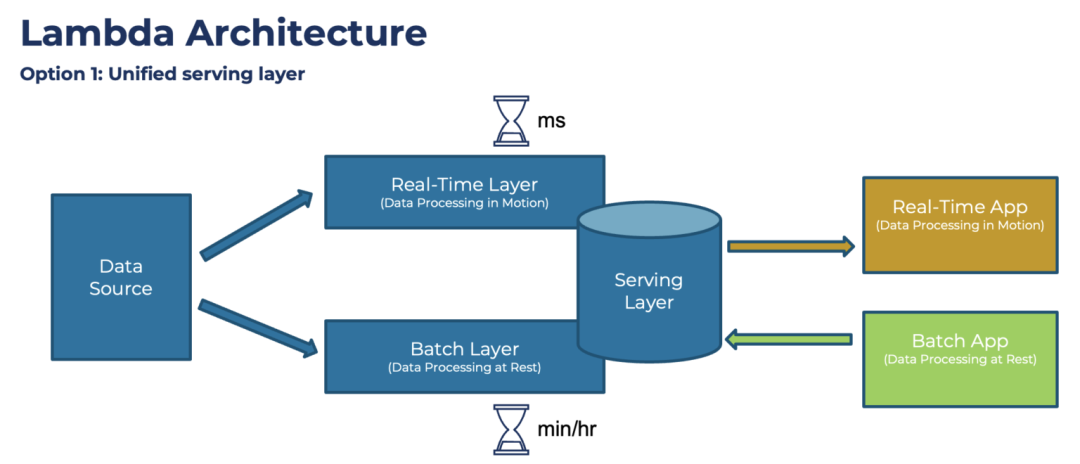
Lambda 架构
In this architecture design or after a lot of experience and thoughtful,The core is the batch processing of the full amount of data every day(Batch Layer),相比传统的基于 SQL 的数据转换,Can support more rich data types and treatment,同时借助 Hadoop The architecture can also support larger data volumes.同时为了支持“实时”需求,Added stream processing layer(Real-Time Layer),Finally when data is consumed,The two pieces of data can be combined(Serving Layer),形成最终的结果.However, this structure has also been criticized.,Especially the need to maintain batch and two sets of real-time computing framework,And to repeat the same processing logic twice,On the architecture complexity and development on the maintenance costs are less than.后续 Kafka 的作者 Jay Kreps 又提出了 Kappa 架构,Want to unify batch and real-time processing,有点“流批一体”的意思.

Kappa 架构
但个人感觉 Kappa The architecture is too ideal,即使到了 2022 年,Streaming data is far from mainstream.For the message flow data duplication,消息顺序,复杂计算(如实时 join)之类的支持,Support for various source data systems,数据 schema 的管理,Data storage cost control and other aspects,Haven't reached a very stable state of convenient and efficient.So to make the data of an enterprise run completely based on streaming data system,It's still unrealistic.So at this stage is the mainstream of data platform architecture is actually from the business requirements and the whole process system maturity,The batch system and real-time processing system in combination with.
2.3 云原生架构
Combination requirements for various components,伴随着云原生时代的到来,more and more direct“Assembly use”的 SaaS 数据产品.Compared with the previous deployment operation and maintenance Hadoop,Kafka 集群的复杂度,A new generation of cloud native products generally can be used directly managed services,按量付费,即开即用,For the Internet companies are very friendly.
So all the common data platform architecture began to introduce all kinds of the direction of product components
,Lots of interesting new ideas:
在数据处理层面,Will use different calculation engine to execute the batch processing or streaming processing tasks,But for the user interface,Hope as soon as possible,于是就有了所谓的“流批一体”.
In data storage and service level,曾经“数据湖”和“数据仓库”The two are at odds,But after a few years the development of the discovery and cannot replace each other.So the data lake camp has increased a lot SQL,Schema,Data governance supports these functions,A new species lakehouse.And data warehouses are also moving towards cloud-native,Very cloudy for warehouse also supports the use of their calculation engine directly to calculate the data files on the lake.“湖仓一体”also become a popular term.
The famous investment institutions a16z The unity of the given data architecture overview is representative:
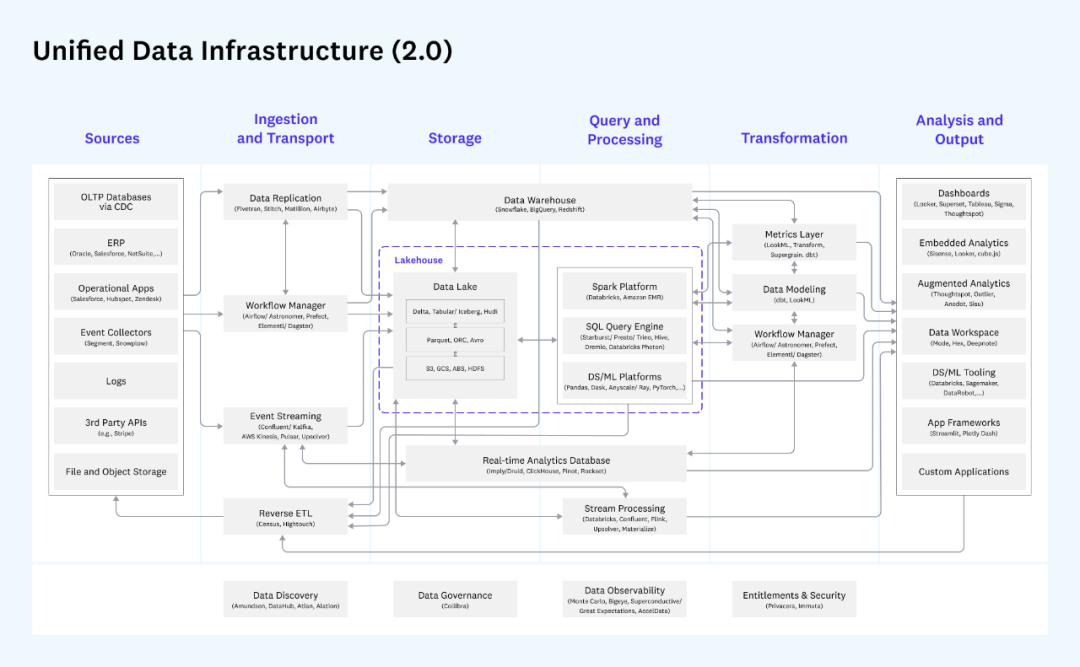
a16z unified data architecture
This picture is very detailed,Divide the entire data flow process into data sources(Generally not included in the data platform),Data acquisition and transmission,存储,查询处理,Data transformation and analysis output these large blocks,And each module in each block,Related products have done detailed annotations.
General enterprise can choose according to demand some of those components to deploy,For example if there is no need for streaming data,So don't need that part below the streaming data access and processing part.而跟 Lambda 架构不同的是,对于同一个业务场景,Generally do not need to make the same data through real-time processing link either,又在 T+1 do it twice when going through the batch link,A link to do but to choose the appropriate subsequent processing can be.
But the architecture diagram because of considering the different scene at different stages of different enterprises demand,It's a bit too complicated,personally prefer《Designing Cloud Data Platform》一书中,A relatively concise overview of the architecture given by the author:

Cloud Data Platform Architecture
At its core, this architecture is a16z The given architecture reference is basically the same,But in each layer On the design of split more clear some,Helps us understand and plan the entire data platform.
If each layer 之间的职责,接口定义清楚,Then for the standardization of data flow,The implementation of the component flexible replacement upgrades will be very good.Later we will according to the graphic description cloud data platform of various components of.
Overall data platform architecture the evolution of the trend in recent years mainly have two aspects,One is to meet diverse business needs,There are more and more system components in the platform as a whole,in a highly differentiated stage,but want to be transparent to the user;The second is the component of choice tend to choose various public cloud vendors or data SaaS Platform Manufacturer's Products,Under the condition of the structure is relatively complex did not improve too much maintenance cost,But the responsibilities between components are clear(松耦合)and interface standardization remains a challenge.
3. 数据获取
在数据获取方面,Platform must be able to support both bulk data and streaming data access.

All kinds of data access
3.1 批量获取
对于批处理数据,such as uploading files,ftp,Or other third party cannot support real-time consumption API 数据源.In fact, most enterprises now docking of various data sources and the basis of the enterprise internal data structure,Basically in the form of batch processing.The vast majority of the platform for the support was better.The typical approach is to trigger the task periodically,Through component to the data source for the whole amount or incremental updating data content,Stored in the data platform.If the task trigger is set more frequently,We can also obtain in batch mode a“准实时”Updated data content for subsequent analysis and use.
3.2 流式获取
Streaming data is very popular in recent years the trend direction,But there is relatively little applications outside the Internet company.大家对于“实时”understandings vary.For example, for analysis scenarios,大家普遍的认知是 T+1(The next day to see the situation as of the previous day)The data updates belong to batch processing,As long as there are multiple data updates in a day,就属于“实时”分析了.This kind of demand can completely by the aforementioned small batch update.And for some automatic decision-making scenarios,例如推荐系统,交易风控,Even if do minute level“小批量”更新,Its timeliness also does not meet the demand,Must interface with streaming data system.
An interesting scene is upstream business docking system database data.If batch access is used,General practice is through an update timestamp to timing query related data table,Then save the incremental data to the data platform.This seems to be fine,But actually if in the updated time window,The original data entry made multiple changes,例如用户在 5 Become a member in minutes,然后取消,通过批量查询的方式,May be two queries down users are members of the state,Lost intermediate state change information.That is why now there are more and more scenario will use CDC technology to capture real-time changes in business data,In the received data platform by means of streaming data to,avoid any loss of information.
This piece of advice for the construction of the path is to build stable first batch data access ability,Then the streaming data acquisition,The last is according to actual needs to consider streaming data processing and analysis(引入 Flink 这类).
3.3 needs and products
Component for data acquisition,The following requirements need to be met:
插件化架构,Support data access from multiple data sources,as different databases,文件,API,Streaming data sources, etc.,Supports flexible custom configuration.
可运维性,Because of the need to deal with all kinds of the third party system,Records of various information,Error of the screen is very important to the convenience of.
性能与稳定性,In order to cope with the large amount of data,Important to analysis the stable operation of the decision-making process,Enterprise-level platform quality assurance is required.
Data acquisition this can consider to use product also has a lot of:
Related services of the three major clouds,such as batch processing AWS Glue,Google Cloud Data Fusion,Azure Data Factory;streaming data AWS Kinesis,Google Cloud Pub/Sub,Azure Event Hubs 等.
第三方 SaaS 服务,如 a16z 提到的 Fivetran,Stitch,Matillion,Airbyte 等.
开源框架,如 Apache NiFi,Kafka,Pulsar,Debezium(CDC 工具) 等.
Note that cloud services are involved,第三方 SaaS 服务,When selecting open source or self-developed tools,You can refer to the following figure to make a trade-off evaluation.The closer to the right, the products of cloud manufacturers,The less operation and maintenance development investment required,But the controllability and portability are relatively weak(Unless it is compatible with the standards of open source frameworks API);The farther to the left, the opposite is true,Very flexible customization using open source products(But should pay attention to control the private branch magic ingredients instead)and deployment flexibility,However, the investment in R&D and operation and maintenance costs will be much higher.

Product selection trade-offs
4. 数据存储
In the after data acquisition,You need to save the data to the platform storage.In the previous data platform architecture diagram,We see that the author divides the storage into fast,slow 两块:

fast and slow storage
4.1 Slow Storage
这个 slow storage 相对比较好理解,In the digital warehouse era, it was warehouse storage part of the system,In the era of big data is the so-called data lake,The more popular HDFS Distributed file system,At present, it is developing more and more in the direction of separation of storage and calculation,Basic, chose the mainstream way of storing all kinds of object storage,如 S3,GCS,ABS 等.The storage form of the data lake is relatively free,数据质量,Enterprise management and other aspects are often difficult to guarantee,所以这两年 Databricks 又提出了 lakehouse 的概念,The storage on the underlying object storage and set up corresponding metadata and store agreement,能够支持 schema 管理,数据版本,事务支持等特性,我们之前也在
Data Lake System in Algorithm Platform
[4] 一文中有过介绍.
4.2 Fast Storage
这个 fast storage It may be easier to misunderstand.在 Lambda 架构和 a16z 的架构图中,fast storage Generally refers to the provision of ad hoc queries to data consumers,Storage system for real-time analytics services,For example we can use some high real-time performance analysis of the type of database(Presto,ClickHouse),Or targeted storage services such as KV 系统,RDBMS 等.And in this picture provided by the author,fast storage In fact, the meaning is simpler,Is the built-in storage streaming data system,如 Kafka,Pulsar The part where the system stores event messages.Is this feeling back to bind on the path of the computing and storage?所以现在 Kafka 跟 Pulsar 也都开始支持
[5] 了,Improve overall scalability,降低成本.

Tiered Storage
4.3 Data access process
Data coming in from the data access layer,Generally, the raw data is directly stored in the slow storage 中,Follow-up is converted to follow-up through the processing of other scheduling needs to use in the form of,如 lakehouse The table or provides services in the number of storehouse.streaming data into fast storage 后,Components to obtain real-time processing analysis and consumption data of them,Finally trigger the downstream data update.At the same time general will through a real-time streaming data processing flow synchronization to save a copy of the original data to the slow storage 中,So that the follow-up there were other use requirements to flexible processing operation.real-time system fast storage 中的消息,Usually only for a while,Avoid high storage costs.这里可以看出 slow storage Need to store the basic is the amount of data,It will cost a lot,That is why now mainstream will generally choose cheap easy extension of the cause of the object storage system.
4.4 needs and products
For storage components,Some important feature requirements include:
性能,slow storage Need to have better throughput,Support concurrent large amount of data acquisition of consumers.而 fast storage Need to have very good response speed for small data volume read and write.
Cloud storage products manufacturers service should be the mainstream choice,After all, it is too complicated to build and maintain a storage cluster by yourself..There are some open source projects based on the cloud vendor object storage made some additional features(例如支持 POSIX)和优化,如
[6],
[7] 和
[8] 等(The latter two are national projects).
5. 数据处理
Data processing is more complex in the entire platform,Is also a variety of schools for the heated part.The most typical approach is to use two sets of calculation engine to support batch and flow processing respectively,Consistent with the data acquisition section.
The advantage is to target the business scenario select the most appropriate technology,And more able to play the advantages of the framework itself.Most companies are batch needs to give priority to,In that case there would be no need to introduce in the first place stream processing engines.
5.1 批处理
Batch processing is one of the most popular framework Apache Spark,As a veteran open source project,社区活跃,Development stage is more mature,Functionally very comprehensive,In addition to typical structured data processing,Can also support unstructured data,graph data etc..If it is mainly structured data,so old Hive,以及 Presto,Dremio Waiting for the new force is also very good SQL Compute Engine Selection.When doing huge amounts of data of the batch,There will also be a lot of optimization methods involved,如各种 join 方式的选择,Task parallelism adjustment,Data skew processing, etc.,这里就不具体展开了.
5.2 流处理
Domestic hear most definitely stream processing Apache Flink 了.此外像 Spark Streaming,Kafka Streams Also provides a corresponding flow processing capacity.For some complex calculation logic,The development threshold for stream computing is still quite high,And a lot of demand actually doesn't have to do the stream processing the complex calculation can be achieved.For example we can use simple data processing after the real-time written to real-time analytical database,如 ClickHouse,Pinot,Rockset,或者像 ElasticSearch,KV 存储,in-memory DB 之类的系统中,Can also provide a flow calculation most of the requirements to meet,We will introduce corresponding examples later.Streaming is the same as batch processing,Need to do a variety of performance,Scalable optimization work,For example, specifying partition logic,解决数据倾斜,checkpoint 调优等.
5.3 流批一体
In recent years, the concept of the integration of batches and batches has also become popular.,尤其是 Flink 社区,Think the batch just stream processing is a special form,It can be done completely using a unified framework.这跟前面提到的 Kappa Architecture is almost the same.Of course, there are also attempts to unify from the software level.,例如 Apache Beam,可以使用相同的 DSL 来做开发,Convert to Spark 或者 Flink Perform batch and stream processing separately on.

Flink 的流批一体

Beam 的流批一体
5.4 needs and products
For data processing components,The requirements to be met are:
The batch products in addition to the previously mentioned various open source framework,Cloud vendors also offer all kinds of managed service,包括我们耳熟能详的 AWS EMR,Google Dataproc 或 Cloud Dataflow(基于 Beam),Azure Databricks 等.
Stream processing products include those provided by cloud vendors AWS Kinesis Data Analytics,Google Cloud Dataflow,Azure Stream Analytics.In addition, there are some well-known SaaS 厂商,包括 Kafka 的“官方”公司
[9],
[10],
[11] 等.

Streaming Data Processing Company Materialize
6. 元数据
传统的 RDBMS After many years of industry application,产品打磨,In terms of metadata, it is still relatively complete..The cloud data platform has not yet become popular,In the process of companies internal structures, often overlooked.This part of the ability to actually as part of an enterprise mature product is vital.
6.1 平台元数据
During the operation of the platform, various information will be generated,Such as the configuration of all kinds of data sources,Execution of data acquisition,Execution of data processing,数据集的 schema、统计信息、血缘关系,系统的资源使用情况,Various log information, etc..通过这些信息,We can monitor platform for a variety of tasks and the alarm,When problems arise can also easily by the view of information screening process,Not login to the management of the various modules respectively console up to check one by one.
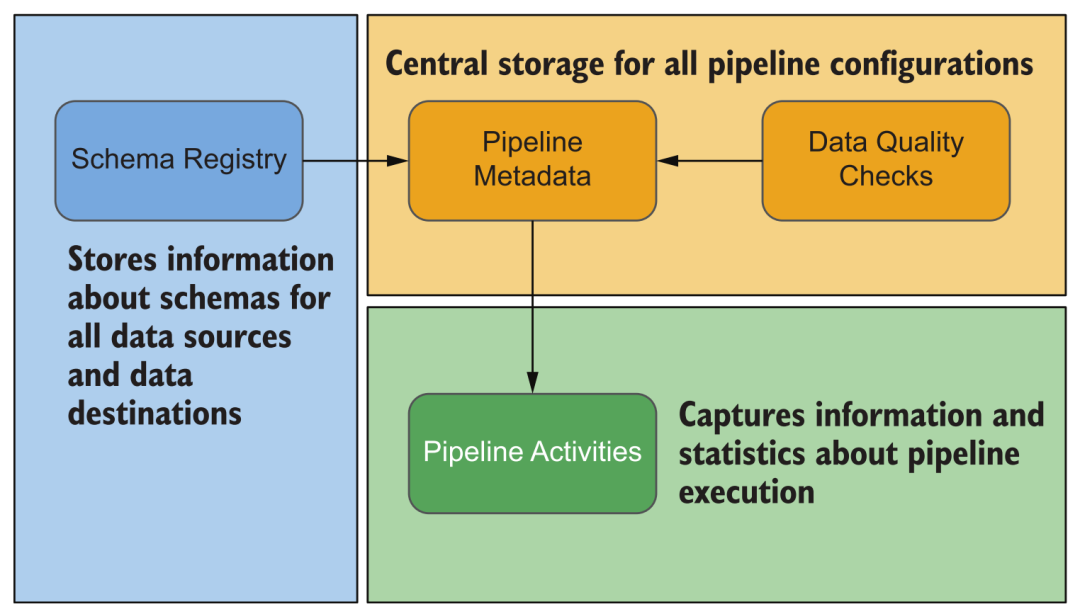
Platform metadata type
Schema This is a big topic.Relative to the number of warehouse system based on relational database technology for,Cloud data platform in flexible processing of data sets schema has certain advantages in terms of changes.Most cloud data warehouses are dealing with schema 变化时,will affect its services(For example, a lock table is required).而很多 lakehouse can better support schema evolution,例如 Delta 里的 mergeSchema 选项.Of course, this feature is not omnipotent.,在整个数据平台中,Involves the processing and transformation of various data,Each link of the interaction,Downstream systems such as warehouses,Real-time analysis of the changes to the database and other external systems consumption,我们必须对 schema Strict recording and management.

元数据中的 Schema Registry
Another category is a very important piece of metadata data quality.随着企业数字化进程的推进,More and more data sources are involved,Within the various data processing conversion is becoming more and more complex,And of all kinds enterprise decision is more and more dependent on the data content and the corresponding analysis result,How to ensure that we still in the process of the whole complexity rising guarantee“数据产品”quality and overall iterative operation and maintenance efficiency,has become a very important issue.Such demands drive the so-called DataOps production of movement,借鉴 DevOps how to sustain enterprise development,交付,Experience in operating and maintaining complex software,Apply it to the field of data products.

DataOps Cycle
This among them very important one annulus is the continuous monitoring of test data quality checks,and applied to the data stream CI/CD,and data management,Data discovery, etc..This has also spawned a new class of products,称为“Data Observability”,Very vividly expressed the insight data platform in the whole data health goals.
6.2 业务元数据
In addition to technical metadata,Also in our business related metadata management and use of the demand.For example, after there are more platform datasets,Management and search will be more complex,Basic folder structure may be difficult to meet requirements,So we need to support the description of the dataset,打 tag,搜索等功能,Help business users to quickly find the right business data information.所谓的 Data Discovery,Data Catalog Products are generally designed to meet such needs.
In addition, depending on the company's business,Appropriate data compliance requirements also need to be followed,such as privacy protection of personal information,Support users' various data rights and freedoms, etc..This ability also need special metadata management and data control(governance)支持.A typical company has Collibra 等.
6.3 needs and products
for metadata components,Conventional demand must still need to ensure high availability and extension performance,When the platform is large,The magnitude of the metadata will also be very impressive.In addition is an important part of the flexibility and extensibility,For example, support for user-defined metadata content,通过开放 API to provide external services, etc..在数据处理,Process orchestration execution,and subsequent data consumption and other modules,need to deal with various metadata,So a well-designed metadata service is becoming more and more attention by all of us.
This field is relatively new,Cloud vendors provide products can not meet the demand of all,如 AWS Glue Data Catalog,Google Data Catalog,Azure Data Catalog.
There are also some open source vendors that provide related services,Relatively little in terms of platform metadata,比较有代表性的是
[12] .In the business metadata level or some more comprehensive,有
[13],
[14],
[15],
[16],
[17] 等.

Atlan 功能介绍
对于 Data Observability 这块,There are also many open source tools and products that we are familiar with,例如 AWS 开源的基于 Spark 的
[18],“碰瓷”狄更斯的
[19],
[20],
[21] 等.

BigEye
7. 数据消费
Data platform of foreign services compared to the number warehouse also enriched many times,In addition to typical data analysis applications,Began to emerge streaming data consumption and scientific,Machine learning application requirements.为了满足不同的需求,Cloud data platform can under the loose coupling, modular design idea,Introduce or connect various special data systems,Flexible expansion of its service capabilities.

Various data consumption needs
7.1 分析查询
对于 BI data analysis requirements,The vast majority of applications are SQL for data query.Due to the rise of self-service data analysis needs,Flexibility for queries,Timeliness of interaction(Need the second level to the second level response),And the requirements for processing large amounts of data are getting higher and higher,传统的 Hive,Spark Query due to the problem of response time always can't meet the demand.In this context also appeared a lot of corresponding solution:
云数仓,as the three major manufacturers BigQuery,Redshift,Azure Synapse,或者第三方的 Snowflake 等.In the case of structured data processing needs,Even these systems can be directly at the core,Replacing traditional data warehouses to build an entire data platform.
Lakehouse,例如 Spark The commercial version of the computing engine Photon,或者 Presto,Dremio 等技术,Based on some data lakes open format(Delta,Hudi,Iceberg)Do efficient query processing.
7.2 数据科学
在数据科学,机器学习领域,The most important ecology at present is based on Python 构建的,Its typical mode of operation would be through notebook,Python 脚本等方式,Directly from the data storage layer to obtain large quantities of data to unity and used for subsequent model training and so on,Less need to pass through SQL to perform complex queries.在这种情况下,如果可以直接访问 slow storage original file in,The natural is the lowest cost overhead.Of course, it also have its downside,such as data management,Permissions, etc. will be difficult to guarantee.
In addition, if you consider the development of the entire machine learning,部署,监控全流程,Then another big lump will be introduced MLOps 相关的需求,Among them, requirements like data involve Feature Store,The difference between batch and real-time feature request pattern inside,Also discuss with us the data platform of batch access and single point query demand of corresponding,Whether can consider when building can reuse deployment component.

机器学习相关 Infra
关于 MLOps 相关的讨论,You can also refer to my previous article
[24].
7.3 实时消费
最后,Results for streaming and analytics,There will also be corresponding applications for real-time consumption.Can be pushed with real-time results,写入关系型数据库,KV 存储,缓存系统(如 Redis),搜索系统(如 ElasticSearch)来对外提供服务.Many streaming systems such as Flink Also supports real-time query,can develop specific API to provide data results directly from streaming systems.
7.4 权限与安全
在企业级应用中,用户权限的控制,Auditing and monitoring of various operational records,包括数据脱敏,The need for things like encryption is critical.In addition to the platform itself should attach great importance to the support of this ability,We also can consider to use all kinds of relevant cloud services,例如 Azure Active Directory,
[25] authentication services such as,Immuta data security company,and various cloud vendors VPC,VPN Related to network security services.
7.5 Service Tier Products
In addition to the aforementioned cloud data warehouse,lakehouse And the analysis of real-time database,也有类似 Metric Store 之类的产品,Built on top of various data sources,对外提供统一的服务.如
[26],
[27],
[28] 等.

Metric Store
8process orchestration and ETL
8.1 流程编排
In the traditional data warehouse architecture,Orchestration tools are also an extremely important part,in cloud data platform,相关的 pipeline Process execution scheduling will be more complex.For example we need by or regularly API way to trigger the data acquisition process,And then to run the various trigger and scheduling of the cascade task.When there are problems or failures in task execution,Retry and recovery can be automated,Or prompt the user to intervene.

Process choreography
For example in the figure above is one of the most simple task dependencies indicated,任务 2 The trigger depends on the task 1 The prerequisite for the successful completion of the batch task,At this moment we need layout tools to support this type of work.
8.2 ETL
The specific tasks performed in the orchestration process,Generally all kinds of data access,数据转换操作,也就是我们俗称的 ETL 了.除了通过 SQL or computational engine SDK(如 PySpark)to develop business logic,There are also many products on the market that support no-code/low-code way to develop,Greatly reduces the threshold for users.
For example, we look far SmartETL Is this a good product,Loved by many business people.

观远 SmartETL
8.3 needs and products
Tools for process orchestration,The main system requirements are:
稳定性,Stability and high availability must be guaranteed,Once the process orchestration ability is paralyzed,Equivalent to the entire platform core ability of data processing are stalled state.
可观测,可运维,Execution status of various tasks,日志,System resources expenses need to be recorded and convenient to view,Facilitate operation and maintenance and troubleshooting.
DataOps 支持,即使提供了 no-code drag-and-drop development,The bottom layer should still be well supported DataOps 的需求,例如 pipeline Logic versioning management,测试与发布(CI/CD),支持 API Invoke to automate processes etc..
It can be noticed that in fact a lot of data acquisition,Bring some data processing tools ETL or the ability to orchestrate.Cloud vendor product basic data acquisition tool is that a few,包括 AWS Glue,Google Cloud Composer(托管版的 Airflow),Google Cloud Data Fusion,Azure Data Factory.
Open source tools,Layout tools,Airflow Probably the most famous one,Later, with the field of machine learning workflow Huge demand for orchestration,There are also many rising stars,如 Dagster,Prefect,Flyte,Cadence,Argo(KubeFlow Pipeline) 等.Also like a Chinese
[29] is also quite well-known.ETL The open source tools are not very useful,talend 并不是完全开源的,The most famous are mainly
[30] 和
[31] Two open source projects with a long history.
SaaS Vendor aspects can reference data acquisition part of the manufacturer,如 Airbyte,Fivetran,Stitch,Rivery 等,Mentioned above a lot of orchestration tools open source project also have the corresponding commercial companies provide hosting service.Also, it has to be mentioned that it is very popular right now
[32],Almost every company in the use of data conversion tool,A good reference to the many best practices in the field of software engineering,可以说是对于 DataOps A very good product that needs support.
9. 最佳实践
9.1 数据分层
When we are building the enterprise data warehouse system,Some classic best practices are generally followed,For example about the data table model,There are design methods such as star schema and snowflake model;From the point of view of the flow of data,There is a very classic data warehouse layering mode:
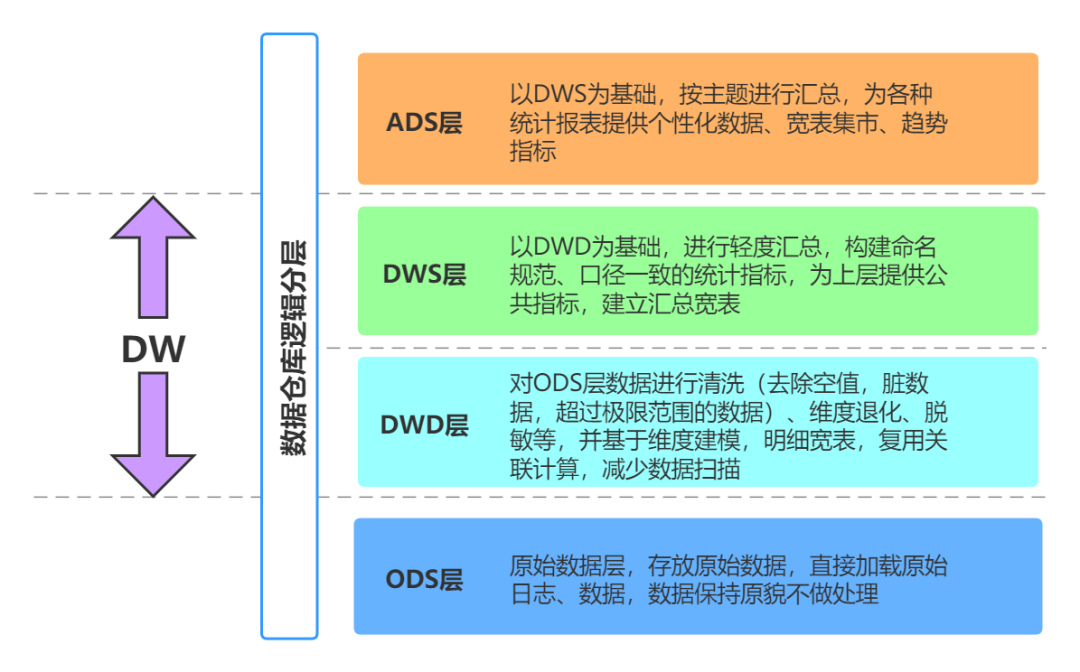
数仓分层
In cloud data platform,We can also learn from this idea.例如 Databricks 设计的 lakehouse The data in the process is to keep up with the number of warehouse are similar in layered:
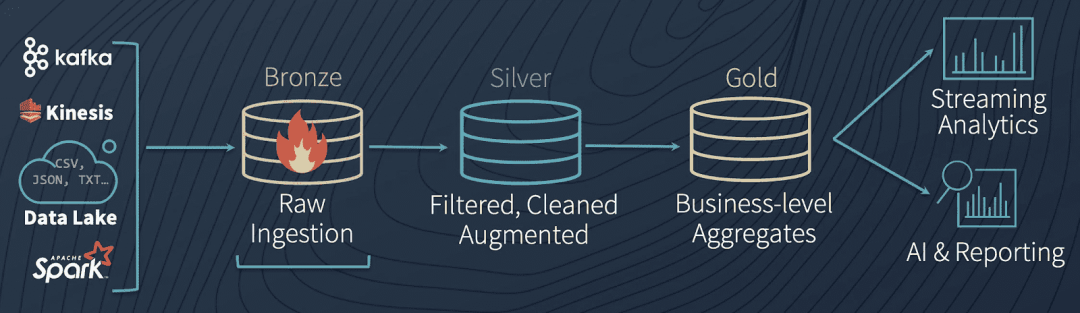
Lakehouse 数据架构
具体流程步骤如下:
Usually by data acquisition into the cloud data platform,try to keep the original data(can be in raw format or Avro 格式)存放在 landing(bronze) 区域,Note in the overall architecture,Only the data access layer tools can write this area.
Raw data will be carried out in the next some common quality inspection,去重,清洗转换,进入到 staging(silver) 区域.From here it is more recommended to use something like parquet 的列式存储格式.
At the same time, the original data will be copied to archive 区域,for subsequent reprocessing,流程 debug,or make a new pipeline Test, etc.
Data Processing Layer Tools,会从 staging area read data,In the processing of all kinds of business logic,聚合等,最终形成 production(golden) 数据,提供数据服务.
Staging Area also can not do data processing,bypass 到 production area and eventually flow into the warehouse,This part is equivalent to the original data,Data can, in some cases, help consumers to do the alignment and positioning related issues.
Different data processing logic will form different business subject oriented,应用场景的“数据产品”,在 production 区域提供 batch 消费服务(Especially algorithm scenarios),Provide or load the number of positions SQL 查询服务.
在 staging,production 流转过程中,If the data processing layer encounters any errors,可以将数据保存到 failed 区域,After the investigation is resolved,put the data back landing 区域,Retrigger the whole process.

Data Process Best Practices
These areas divided by the concept of typical object storage,如“桶”或者“文件夹”来进行划分.Can also read and write according to different pattern to determine the different layer Module access control,And the design of the hot and cold storage to save cost.Streaming data processing process also can be reference to similar logic,But in data deduplication,质量检查,数据增强,schema There will be more challenges in management, etc..
9.2 Distinguishing Streaming Acquisition and Streaming Analysis Requirements
我们经常听到 BI Analytical clients have“实时数据分析”的需求.但仔细分析来看,Users don’t stare at all the time BI Analytical Kanban to do“实时分析”,Overall open kanban is a certain time interval.Every time we only need to make sure that the customer open the analysis kanban data is the latest you can see,Therefore, the following architecture can be used to satisfy:

Streaming Data Acquisition Architecture
Here we need only through the order data real-time streaming data acquisition system to cloud several positions can be,When the user opens the report every so often,triggering a number of positions SQL 查询,Show the latest results.
But consider another scenario,在某个游戏中,We want to show real-time action data of users,Such as the exp gain since online statistics.这个时候,If we still use the above“流式获取”The architecture may not be appropriate.Because at this time every player is a real“实时”Staring at his statistics,must be high frequency,Big concurrent query support.General cloud the response time of number of storehouse and concurrent service ability is difficult to meet the,That's when it really comes to“实时分析”的需求.We need to stream the user's new data after,Perform streaming statistical analysis operations,and store the results in some device that can support high concurrency,Database for low latency queries/缓存系统中,To support massive data online gamers demand.

Streaming Data Analysis Architecture
9.3 Control cloud computing overhead
云原生时代,When we use all kinds of components to fit the threshold low a lot,开箱即用,弹性伸缩,Free operation and maintenance brings a lot of convenience to developers,It is also quietly changing our thinking.In the era of self-built systems,Our resource overhead for each component,The whole cluster utilization have more fine understanding and further optimization of.But now various systems are designed trade-off Allocate from a limited pool of resources,Turning to the cost-performance trade-off,Instead of reducing the cost of each component resources optimization consciousness.Including cloud vendors themselves sometimes will have intention to not intentional of“摆烂”,Another recent article
[33] Dedicated to discussing cloud vendors auto-scaling The economics of the problem.
Therefore, as a developer of a cloud data platform,Still need a deep understanding of various cloud computing components,product architecture,收费模式,And practice corresponding resource monitoring,优化手段.Typical examples include control of network overhead(Reduce cross-cloud transfers),Design of hot and cold storage,Data partition optimization to improve data processing efficiency and so on.
9.4 避免紧耦合
As can be seen from the previous complex architecture diagram,Cloud data platform of components which would by very much,And the technology of ecological changes are also changing.Usually for this kind of complex system,We'll take a step-by-step approach,will continue to increase,Replace or retire some component products,So have to use the experience of the loosely coupled software engineering principles,Avoid a specific product/Interfaces have tight dependencies.Although sometimes direct access to the underlying storage approach seems to reduce the intermediate steps, such as high efficiency,But also let us later want to do to expand and change encountered big trouble.Ideally we should be as clear as possible components between the boundary and the interface,Encapsulation of different products so as to provide a relative standard interface interaction and service.
10. 数据平台建设
10.1 业务价值
最后值得一提的是,Complex cloud data platform construction not only from the perspective of technology to promote.must from business(商业)to initiate and plan the entire project.
Typical values of data platforms include:
开源,Support marketing optimization,Customer experience optimization and other scenarios,Boost company revenue.
创新,Through excellent product capabilities,Self-service data analysis and decision-making to support business,Quickly explore new growth points.
We should clear business demands,Corresponding design strategy and the construction of data platform planning data.How technology strategy serves business goals,也可以参考这篇
The road to senior engineer:技术战略
[34],这里就不详细展开了.
10.2 建设路径
As seen from the previous architecture diagram,The composition of the entire platform is quite complex,General need after a few years time to set up and perfect gradually.This online and the enterprise itself,数字化,The intelligent evolution route needs to be consistent,Instead of ignoring the status quo of enterprise data,Develop and deploy streaming data platform,Newer-looking technologies like machine learning platforms.
View of our long established early deep thinking and put forward the data analysis and intelligent decision-making in enterprise
[35],Including from self-service analysis,To the scene,,自动化,Augmentation that ultimately automates decision-making 5 个步骤.
Corresponding to the construction of the data platform,Can also refer to a similar policy framework,例如:
场景化,通过 metric layer 和 BI Product in the application market,Form the best practices for every business scenario,让更多的用户知道“怎么看数据”.
自动化,Requires the platform to have certain orchestration capabilities,Connect various analysis results with business systems,Automatically push results(反向 ETL),数据预警等,达到“数据追人”的效果.
增强化,在分析的基础上,进一步加入 AI Modeling and forecasting capabilities,Requires platform to support algorithmic data processing and consumption(such as unstructured data,notebook),实现“洞见未来”.
行动化,Finally we hope that we can in the prediction on the basis of further,from analytical AI extended to mobile AI,The platform needs to provide more comprehensive external service capabilities(API,实时数据,AB Test 等),Combined with some low code tools to build data-driven business application,有望实现“自动决策”.

Data Analytics Maturity Journey
10.3 用户推广
In addition to the evolutionary methodology from the technical architecture level,How the business level to propaganda and promotion platform is an important subject.There are too many data platform project is lack of thorough understanding of business communication,In the absence of consistent cognition on both sides,Advance complex projects,The construction period is very long,ultimately lead to failure in the middle.We should be through some small projects quickly reflect platform more value,enhance mutual understanding,获取用户的信任,And gradually extended to more organizational departments;after more applications,will also drive the scene,Demand for rich,, in turn, can guide and promote the construction and development of the platform itself,进入一个良性循环.This is what we continue to explore and practice.“让业务用起来”the route method.
One last little ad,
We view data in the aforementioned product technology level and enterprise service,Very rich experience in business promotion.通过 Universe,Galaxy,Atlas 产品线,Can support various data analysis maturity stage of the enterprise data platform,BI + AI 分析决策需求.
Head customers in some industries,Our products have also successfully achieved 20000 More active data analysts and decision user milestone,Can imagine such enterprises in the fierce market competition can be reflected in the decision making efficiency and the quality of the huge advantage.Welcome interested friends to a communication is discussed in this paper,Seek opportunities for cooperation :)
参考资料
[1] The composition and construction of a cloud native machine learning platform:
https://zhuanlan.zhihu.com/p/383528646
[2] a16z Some analysis reports of:
https://future.com/data50/
[3] modern data stack:
https://www.moderndatastack.xyz/
[4] Data Lake System in Algorithm Platform:
https://zhuanlan.zhihu.com/p/400012723
[5] tiered storage:
https://www.confluent.io/blog/infinite-kafka-storage-in-confluent-platform/
[6] lakeFS:
https://github.com/treeverse/lakeFS
[7] JuiceFS:
https://github.com/juicedata/juicefs
[8] SeaseedFS:
https://github.com/chrislusf/seaweedfs
[9] Confluent:
https://www.confluent.io/
[10] Upsolver:
https://www.upsolver.com/
[11] Materialize:
https://materialize.com/
[12] Marquez:
https://github.com/MarquezProject/marquez
[13] Apache Atlas:
https://atlas.apache.org/
[14] Amundsen:
https://www.amundsen.io/
[15] DataHub:
https://datahubproject.io/
[16] Atlan:
https://atlan.com/
[17] Alation:
https://www.alation.com/
[18] Deequ:
https://github.com/awslabs/deequ
[19] Great Expectations:
https://github.com/great-expectations/great_expectations
[20] Monte Carlo:
https://www.montecarlodata.com/
[21] BigEye:
https://www.bigeye.com/
[22] Apache Doris:
https://doris.apache.org/
[23] Databend:
https://databend.rs/
[24] MLOps 简介:
https://zhuanlan.zhihu.com/p/357897337
[25] Auth0:
https://auth0.com/
[26] LookML:
https://www.looker.com/platform/data-modeling/
[27] Transform:
https://transform.co/
[28] Metlo:
https://blog.metlo.com/
[29] DolphinScheduler:
https://github.com/apache/dolphinscheduler
[30] Apache NiFi:
https://github.com/apache/nifi
[31] OpenRefine:
https://github.com/OpenRefine/OpenRefine
[32] dbt:
https://www.getdbt.com/
[33] The Non-Expert Tax:
https://dl.acm.org/doi/10.1145/3530050.3532925
[34] The road to senior engineer:技术战略:
https://zhuanlan.zhihu.com/p/498475916
[35] 5A 落地路径方法论:
https://zhuanlan.zhihu.com/p/43515719
原网站版权声明
本文为[InfoQ]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/222/202208101613477660.html

![PC软件问题二[Win10系统将UltraEdit添加到右键菜单的方法]](/img/4f/f3856e135302bcf5902bf987b7ed4d.png)