当前位置:网站首页>Reading of denoising paper - [ridnet, iccv19] real image denoising with feature attention
Reading of denoising paper - [ridnet, iccv19] real image denoising with feature attention
2022-04-23 05:59:00 【umbrellalalalala】
Know that the account with the same name is published synchronously
Catalog
One 、 Detailed explanation of architecture parameters
This part starts with the architecture , The next part is about the key parts of the architecture motivation.
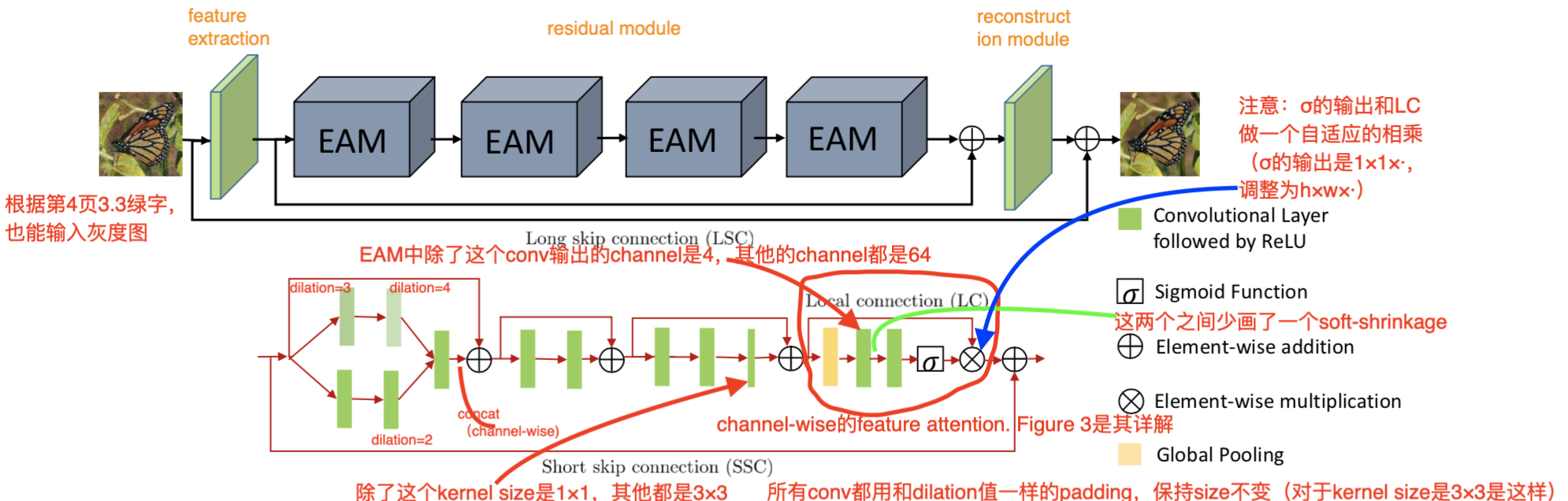
The details of the network architecture have been marked in the figure . The top half of the figure is the overall architecture , The lower half is a separate EAM The architecture of .
Input noisy image, Output noise-free image.
The author divides the architecture into three module:
- feature extraction: f 0 = M e ( x ) f_0=M_e(x) f0=Me(x), There is only one floor .
- feature learning residual module: f r = M f l ( f 0 ) f_r=M_{fl}(f_0) fr=Mfl(f0), By a number of EAM form .
- reconstruction module: y ^ = M r ( f r ) \hat{y}=M_r(f_r) y^=Mr(fr), There is only one floor .
loss function yes :
L ( w ) = 1 N ∑ i = 1 N ∣ ∣ R I D N e t ( x i ) − y i ∣ ∣ 1 = 1 N ∑ i = 1 N ∣ R I D N e t ( x i ) − y i ∣ L(w)=\frac{1}{N}\sum_{i=1}^{N}||RIDNet(x_i)-y_i||_1=\frac{1}{N}\sum_{i=1}^{N}|RIDNet(x_i)-y_i| L(w)=N1i=1∑N∣∣RIDNet(xi)−yi∣∣1=N1i=1∑N∣RIDNet(xi)−yi∣
kernel size Except for the finer convolution in the figure above is 1 × 1 1\times1 1×1, Everything else is 3 × 3 3\times3 3×3.
About channel, Almost all convolution layers are 64, In addition to the next layer in this structure, the lower sampling is 4:

This is channel-wise Of feature attention, Here's what it looks like after unfolding :
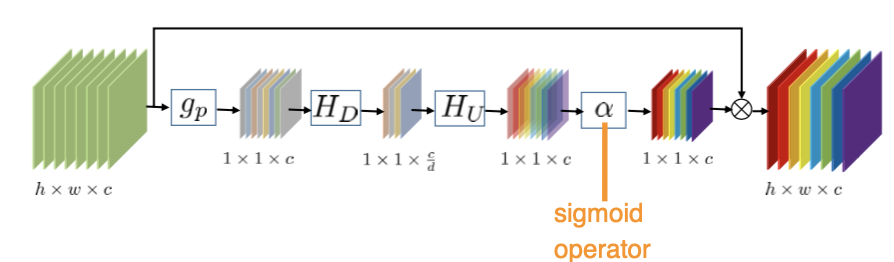
( Notice that the picture above is missing soft-shrinkage, The author in H D H_D HD Then I used it )
In the picture above d, The author uses 16, So it leads to H D H_D HD Then I got the only one channel by 4 Of feature map, Of all other layers channel All are 64 Of .
️ Be careful : The last multiplication is element-wise Of , Because of the size Different , Therefore, we need to carry out adaptive multiplication first , the 1 × 1 × c 1 \times 1 \times c 1×1×c The part of is expanded to h × w × c h \times w \times c h×w×c(adaptively rescaled), The expansion method is replication .
In the paper notation And abbreviations have a lot of , among ERB(enhanced residual block) Refers to :
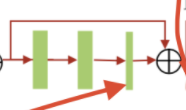
The thin convolution layer in the figure above is the only one in the whole architecture 1 × 1 1\times1 1×1 The convolution of layer , All other convolutions are 3 × 3 3\times3 3×3 Of .
other notation And abbreviations are mostly marked in the figure above , What is not marked is also relatively simple , Don't say .
Two 、Contribution&innovation
Let's talk about it briefly , Then to important places , In the next part, I'll talk about .
The authors say their contribution as follows :
- Is the first to use in denoising feature attention Model of ;
- The existing model Increasing depth may not improve performance, And cause the gradient to disappear ;
- This is a one stage model( contrast CBDNet yes two stage model), There is only one stage of speech denoising ( contrast CBDNet There is estimated noise 、 There are two stages of denoising ).
Say that the second increase in depth does not increase performance , The author also said :
simple cascading the residual modules will not achieve better performance.
Compare the author's method : increase EAM The number of modules , Can improve performance,EAM It also includes residual learning Thought .
3、 ... and 、feature attention
( As a reminder g p g_p gp yes global pooling)
Or this structure , It is a feature attention Structure , According to the first part , It's a change feature map Different from channel The weight of . Of course, this can't be regarded as the originality of this work , The author said they were referring to :
Squeeze-and-excitation networks.
Of course, a little change has been made , Among the things above H D H_D HD In the heel ReLU, And the author follows soft-shrinkage.
The author's original words are also put here :
The feature attention mechanism for selecting the essential features.
Four 、 Data sets & Training details & Ablation Experiment
1, Training data set :
- synthetic image: BSD500,DIV2K,MIT-Adobe FiveK Generate ;
- real-world image: Yes SIDD,Poly,RENOIR Generate .
(paper I didn't say how to synthesize the noise map , Check the code , It should be to join directly Gaussion noise; For real noise maps , Look up the SIDD, It's with ground-truth Of noisy image dataset)
2, Data enhancement method :
- random rotation of 90°, 180°, 270°;
- flipping horizontally
3, Test data set :
- 4 A real noise image data set RNI15,DND,Nam,SIDD.
- 3 A synthetic noise image data set :widely-used 12 classical images,BSD68 color and gray 68 images.
4, Training details :
- batchsize=32,patchsize by 80 × 80 80\times80 80×80
5, Ablation Experiment :
- When LSC,SSC,LC Three connections (skip connection) When it's all used , The effect is the best ( These three connections are shown in the figure at the beginning of the article ), Remove the use of any connection , The effect will decrease .
️ Be careful : If you don't use these connections , Then increase the of the network depth Will not be raised performance. - Yes feature attention Better than nothing .

版权声明
本文为[umbrellalalalala]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204230543474335.html
边栏推荐
- Pytorch学习记录(十):数据预处理+Batch Normalization批处理(BN)
- ValueError: loaded state dict contains a parameter group that doesn‘t match the size of optimizer‘s
- PyQy5学习(二):QMainWindow+QWidget+QLabel
- PyTorch笔记——实现线性回归完整代码&手动或自动计算梯度代码对比
- Gaussian processes of sklearn
- PyQy5学习(四):QAbstractButton+QRadioButton+QCheckBox
- 你不能访问此共享文件夹,因为你组织的安全策略阻止未经身份验证的来宾访问
- 如何利用对比学习做无监督——[CVPR22]Deraining&[ECCV20]Image Translation
- Filebrowser realizes private network disk
- PyTorch笔记——观察DataLoader&用torch构建LeNet处理CIFAR-10完整代码
猜你喜欢

Pytorch learning record (XI): data enhancement, torchvision Explanation of various functions of transforms

线性代数第二章-矩阵及其运算

Pyqt5 learning (I): Layout Management + signal and slot association + menu bar and toolbar + packaging resource package

Automatic control (Han min version)

多线程与高并发(1)——线程的基本知识(实现,常用方法,状态)

Fundamentals of digital image processing (Gonzalez) II: gray transformation and spatial filtering

JVM family (4) -- memory overflow (OOM)

Pytorch learning record (7): skills in processing data and training models

Pyqy5 learning (4): qabstractbutton + qradiobutton + qcheckbox
PyQy5学习(二):QMainWindow+QWidget+QLabel
随机推荐
一文读懂当前常用的加密技术体系(对称、非对称、信息摘要、数字签名、数字证书、公钥体系)
图像恢复论文简记——Uformer: A General U-Shaped Transformer for Image Restoration
Conda 虚拟环境管理(创建、删除、克隆、重命名、导出和导入)
JVM family (4) -- memory overflow (OOM)
container
JSP syntax and JSTL tag
PyQy5学习(二):QMainWindow+QWidget+QLabel
容器
创建企业邮箱账户命令
在Jupyter notebook中用matplotlib.pyplot出现服务器挂掉、崩溃的问题
创建线程的三种方式
治療TensorFlow後遺症——簡單例子記錄torch.utils.data.dataset.Dataset重寫時的圖片維度問題
Manually delete registered services on Eureka
Pytorch学习记录(十三):循环神经网络((Recurrent Neural Network)
Kingdee EAS "general ledger" system calls "de posting" button
sklearn之 Gaussian Processes
深入理解去噪论文——FFDNet和CBDNet中noise level与噪声方差之间的关系探索
自动控制(韩敏版)
Pytorch学习记录(九):Pytorch中卷积神经网络
事实最终变量与最终变量