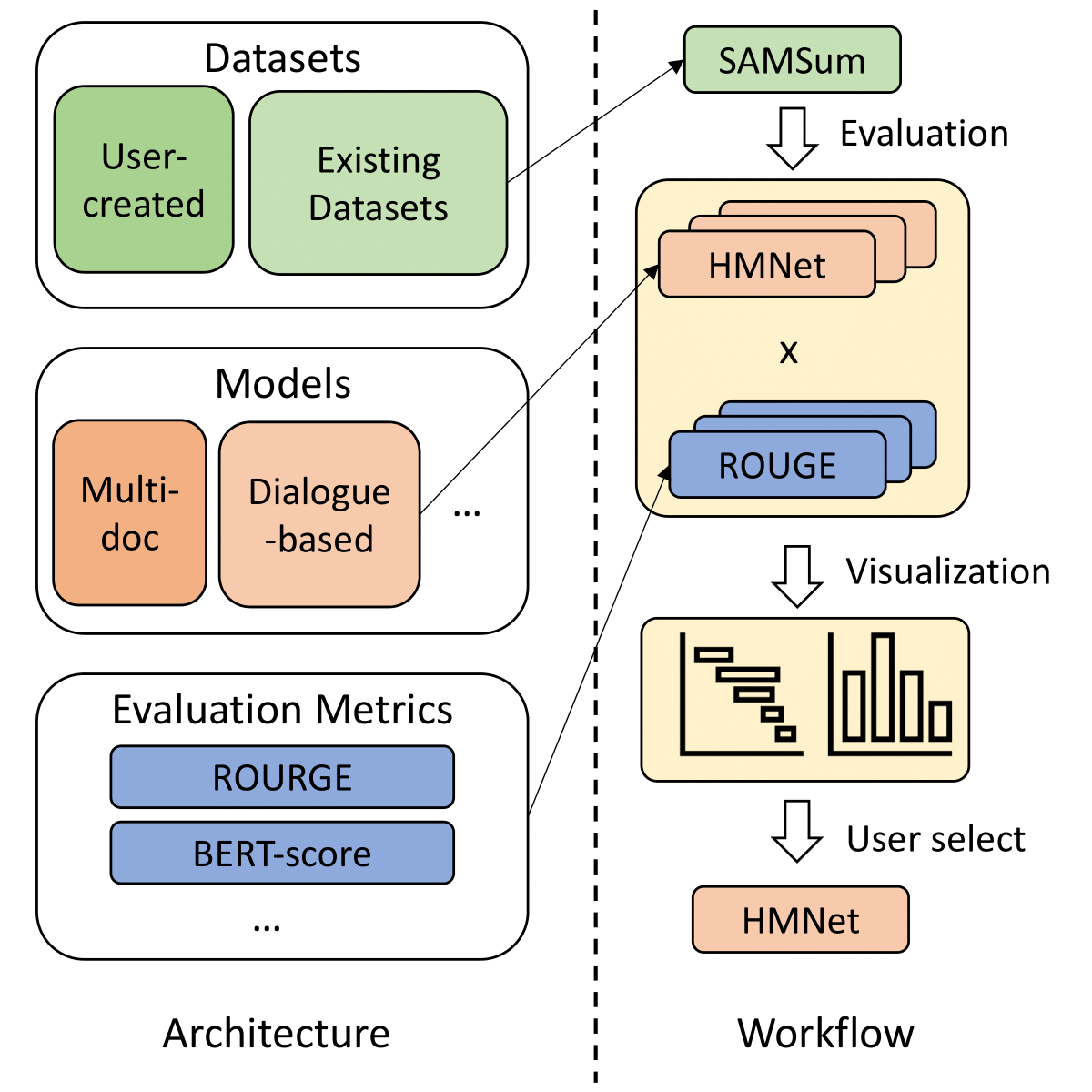
FactSumm: Factual Consistency Scorer for Abstractive Summarization


FactSumm is a toolkit that scores Factualy Consistency for Abstract Summarization
Without fine-tuning, you can simply apply a variety of downstream tasks to both the source article and the generated abstractive summary

For example, by extracting fact triples from source articles and generated summaries, we can verify that generated summaries correctly reflect source-based facts ( See image above )
As you can guess, this PoC-ish project uses a lot of pre-trained modules that require super-duper computing resources
So don't blame me, just take it as a concept project
Installation
FactSumm requires Java to be installed in your environment to use Stanford OpenIE. With Java and Python 3, you can install factsumm simply using pip:
pip install factsumm
Or you can install FactSumm from source repository:
git clone https://github.com/huffon/factsumm
cd factsumm
pip install .
Usage
>>> from factsumm import FactSumm
>>> factsumm = FactSumm()
>>> article = "Lionel Andrés Messi (born 24 June 1987) is an Argentine professional footballer who plays as a forward and captains both Spanish club Barcelona and the Argentina national team. Often considered as the best player in the world and widely regarded as one of the greatest players of all time, Messi has won a record six Ballon d'Or awards, a record six European Golden Shoes, and in 2020 was named to the Ballon d'Or Dream Team."
>>> summary = "Lionel Andrés Messi (born 24 Aug 1997) is an Spanish professional footballer who plays as a forward and captains both Spanish club Barcelona and the Spanish national team."
>>> factsumm(article, summary, verbose=True)
SOURCE Entities
1: [('Lionel Andrés Messi', 'PERSON'), ('24 June 1987', 'DATE'), ('Argentine', 'NORP'), ('Spanish', 'NORP'), ('Barcelona',
'GPE'), ('Argentina', 'GPE')]
2: [('one', 'CARDINAL'), ('Messi', 'PERSON'), ('six', 'CARDINAL'), ('European Golden Shoes', 'WORK_OF_ART'), ('2020', 'DATE'),
("the Ballon d'Or Dream Team", 'ORG')]
SUMMARY Entities
1: [('Lionel Andrés Messi', 'PERSON'), ('24 Aug 1997', 'DATE'), ('Spanish', 'NORP'), ('Barcelona', 'ORG')]
SOURCE Facts
('Lionel Andrés Messi', 'per:origin', 'Argentine')
('Spanish', 'per:date_of_birth', '24 June 1987')
('Spanish', 'org:top_members/employees', 'Lionel Andrés Messi')
('Spanish', 'org:members', 'Barcelona')
('Lionel Andrés Messi', 'per:employee_of', 'Barcelona')
('Lionel Andrés Messi', 'per:date_of_birth', '24 June 1987')
('Barcelona', 'org:top_members/employees', 'Lionel Andrés Messi')
SUMMARY Facts
('Lionel Andrés Messi', 'per:origin', 'Spanish')
('Lionel Andrés Messi', 'per:date_of_birth', '24 Aug 1997')
('Spanish', 'per:date_of_birth', '24 Aug 1997')
('Spanish', 'org:top_members/employees', 'Lionel Andrés Messi')
('Spanish', 'org:members', 'Barcelona')
('Lionel Andrés Messi', 'per:employee_of', 'Barcelona')
('Barcelona', 'org:top_members/employees', 'Lionel Andrés Messi')
COMMON Facts
('Spanish', 'org:top_members/employees', 'Lionel Andrés Messi')
('Spanish', 'org:members', 'Barcelona')
('Lionel Andrés Messi', 'per:employee_of', 'Barcelona')
('Barcelona', 'org:top_members/employees', 'Lionel Andrés Messi')
DIFF Facts
('Lionel Andrés Messi', 'per:origin', 'Spanish')
('Lionel Andrés Messi', 'per:date_of_birth', '24 Aug 1997')
('Spanish', 'per:date_of_birth', '24 Aug 1997')
Fact Score: 0.5714285714285714
Answers based on SOURCE (Questions are generated from Summary)
[Q] Who is the captain of the Spanish national team? [Pred] <unanswerable>
[Q] When was Lionel Andrés Messi born? [Pred] 24 June 1987
[Q] Lionel Andrés Messi is a professional footballer of what nationality? [Pred] Argentine
[Q] Lionel Messi is a captain of which Spanish club? [Pred] Barcelona
Answers based on SUMMARY (Questions are generated from Summary)
[Q] Who is the captain of the Spanish national team? [Pred] Lionel Andrés Messi
[Q] When was Lionel Andrés Messi born? [Pred] 24 Aug 1997
[Q] Lionel Andrés Messi is a professional footballer of what nationality? [Pred] Spanish
[Q] Lionel Messi is a captain of which Spanish club? [Pred] Barcelona
QAGS Score: 0.3333333333333333
SOURCE Triples
('Messi', 'is', 'Argentine')
('Messi', 'is', 'professional')
SUMMARY Triples
('Messi', 'is', 'Spanish')
('Messi', 'is', 'professional')
Triple Score: 0.5
Avg. ROUGE-1: 0.4415584415584415
Avg. ROUGE-2: 0.3287671232876712
Avg. ROUGE-L: 0.4415584415584415
Sub-modules
From here, you can find various way to score Factual Consistency level with Unsupervised methods
Triple-based Module ( closed-scheme )
>>> from factsumm import FactSumm
>>> factsumm = FactSumm()
>>> factsumm.extract_facts(article, summary, verbose=True)
SOURCE Entities
1: [('Lionel Andrés Messi', 'PERSON'), ('24 June 1987', 'DATE'), ('Argentine', 'NORP'), ('Spanish', 'NORP'), ('Barcelona',
'GPE'), ('Argentina', 'GPE')]
2: [('one', 'CARDINAL'), ('Messi', 'PERSON'), ('six', 'CARDINAL'), ('European Golden Shoes', 'WORK_OF_ART'), ('2020', 'DATE'),
("the Ballon d'Or Dream Team", 'ORG')]
SUMMARY Entities
1: [('Lionel Andrés Messi', 'PERSON'), ('24 Aug 1997', 'DATE'), ('Spanish', 'NORP'), ('Barcelona', 'ORG')]
SOURCE Facts
('Lionel Andrés Messi', 'per:origin', 'Argentine')
('Spanish', 'per:date_of_birth', '24 June 1987')
('Spanish', 'org:top_members/employees', 'Lionel Andrés Messi')
('Spanish', 'org:members', 'Barcelona')
('Lionel Andrés Messi', 'per:employee_of', 'Barcelona')
('Lionel Andrés Messi', 'per:date_of_birth', '24 June 1987')
('Barcelona', 'org:top_members/employees', 'Lionel Andrés Messi')
SUMMARY Facts
('Lionel Andrés Messi', 'per:origin', 'Spanish')
('Lionel Andrés Messi', 'per:date_of_birth', '24 Aug 1997')
('Spanish', 'per:date_of_birth', '24 Aug 1997')
('Spanish', 'org:top_members/employees', 'Lionel Andrés Messi')
('Spanish', 'org:members', 'Barcelona')
('Lionel Andrés Messi', 'per:employee_of', 'Barcelona')
('Barcelona', 'org:top_members/employees', 'Lionel Andrés Messi')
COMMON Facts
('Spanish', 'org:top_members/employees', 'Lionel Andrés Messi')
('Spanish', 'org:members', 'Barcelona')
('Lionel Andrés Messi', 'per:employee_of', 'Barcelona')
('Barcelona', 'org:top_members/employees', 'Lionel Andrés Messi')
DIFF Facts
('Lionel Andrés Messi', 'per:origin', 'Spanish')
('Lionel Andrés Messi', 'per:date_of_birth', '24 Aug 1997')
('Spanish', 'per:date_of_birth', '24 Aug 1997')
Fact Score: 0.5714285714285714
The triple-based module counts the overlap of fact triples between the generated summary and the source document.
QA-based Module

If you ask questions about the summary and the source document, you will get a similar answer if the summary realistically matches the source document
>>> from factsumm import FactSumm
>>> factsumm = FactSumm()
>>> factsumm.extract_qas(article, summary, verbose=True)
Answers based on SOURCE (Questions are generated from Summary)
[Q] Who is the captain of the Spanish national team? [Pred] <unanswerable>
[Q] When was Lionel Andrés Messi born? [Pred] 24 June 1987
[Q] Lionel Andrés Messi is a professional footballer of what nationality? [Pred] Argentine
[Q] Lionel Messi is a captain of which Spanish club? [Pred] Barcelona
Answers based on SUMMARY (Questions are generated from Summary)
[Q] Who is the captain of the Spanish national team? [Pred] Lionel Andrés Messi
[Q] When was Lionel Andrés Messi born? [Pred] 24 Aug 1997
[Q] Lionel Andrés Messi is a professional footballer of what nationality? [Pred] Spanish
[Q] Lionel Messi is a captain of which Spanish club? [Pred] Barcelona
QAGS Score: 0.3333333333333333
OpenIE-based Module ( open-scheme )
>>> from factsumm import FactSumm
>>> factsumm = FactSumm()
>>> factsumm.extract_triples(article, summary, verbose=True)
SOURCE Triples
('Messi', 'is', 'Argentine')
('Messi', 'is', 'professional')
SUMMARY Triples
('Messi', 'is', 'Spanish')
('Messi', 'is', 'professional')
Triple Score: 0.5
Stanford OpenIE can extract relationships from raw strings. But it's important to note that it's based on the open scheme, not the closed scheme (like Triple-based Module).
For example, from "Obama was born in Hawaii", OpenIE extracts (Obama, born in Hawaii). However, from "Hawaii is the birthplace of Obama", it extracts (Hawaii, is the birthplace of, Obama). In common sense, the triples extracted from the two sentences should be identical, but OpenIE can't recognize that they are the same since it is based on an open scheme.
So the score for this module may be unstable.
ROUGE-based Module
>>> from factsumm import FactSumm
>>> factsumm = FactSumm()
>>> factsumm.calculate_rouge(article, summary)
Avg. ROUGE-1: 0.4415584415584415
Avg. ROUGE-2: 0.3287671232876712
Avg. ROUGE-L: 0.4415584415584415
Simple but effective word-level overlap ROUGE score
Citation
If you apply this library to any project, please cite:
@misc{factsumm,
author = {Heo, Hoon},
title = {FactSumm: Factual Consistency Scorer for Abstractive Summarization},
howpublished = {\url{https://github.com/Huffon/factsumm}},
year = {2021},
}
References
- The Factual Inconsistency Problem in Abstractive Text Summarization: A Survey
- Assessing The Factual Accuracy of Generated Text
- Asking and Answering Questions to Evaluate the Factual Consistency of Summaries
- FEQA: A Question Answering Evaluation Framework for Faithfulness Assessment in Abstractive Summarization

 137 Feb 1, 2021
137 Feb 1, 2021
 72 Dec 7, 2022
72 Dec 7, 2022

 1.2k Dec 30, 2022
1.2k Dec 30, 2022
 21 Nov 24, 2022
21 Nov 24, 2022
 6 Jun 4, 2021
6 Jun 4, 2021

 39 Dec 14, 2022
39 Dec 14, 2022
 213 Jan 4, 2023
213 Jan 4, 2023

 3 Aug 10, 2022
3 Aug 10, 2022

 9 Oct 14, 2022
9 Oct 14, 2022



 1 Feb 14, 2022
1 Feb 14, 2022
 7 Sep 17, 2022
7 Sep 17, 2022
 0 Jul 29, 2021
0 Jul 29, 2021
 415 Jan 06, 2023
415 Jan 06, 2023
 105 Jan 08, 2022
105 Jan 08, 2022
 2.3k Jan 05, 2023
2.3k Jan 05, 2023
 32 Jan 03, 2023
32 Jan 03, 2023
 0 Dec 11, 2022
0 Dec 11, 2022
 29 Nov 26, 2022
29 Nov 26, 2022
 3 Dec 28, 2021
3 Dec 28, 2021
 395 Nov 21, 2022
395 Nov 21, 2022
 23 Sep 22, 2022
23 Sep 22, 2022
 159 Dec 30, 2022
159 Dec 30, 2022
 14 Jul 23, 2022
14 Jul 23, 2022
 20 Oct 11, 2022
20 Oct 11, 2022
 1.5k Dec 26, 2022
1.5k Dec 26, 2022
 177 Dec 27, 2022
177 Dec 27, 2022
 85 Dec 26, 2022
85 Dec 26, 2022
 858 Dec 27, 2022
858 Dec 27, 2022
 40 Dec 11, 2022
40 Dec 11, 2022