pytorch-retrainingTransfer Learning shootout for PyTorch's model zoo (torchvision).
Load any pretrained model with custom final layer (num_classes) from PyTorch's model zoo in one line
model_pretrained , diff = load_model_merged ('inception_v3' , num_classes )
Retrain minimal (as inferred on load) or a custom amount of layers on multiple GPUs. Optionally with Cyclical Learning Rate (Smith 2017) .
final_param_names = [d [0 ] for d in diff ]
stats = train_eval (model_pretrained , trainloader , testloader , final_params_names )
Chart training_time, evaluation_time (fps), top-1 accuracy for varying levels of retraining depth (shallow, deep and from scratch)
Transfer learning on example dataset Bee vs Ants with 2xV100 GPUs
Results on more elaborate Datasetnum_classes = 23, slightly unbalanced, high variance in rotation and motion blur artifacts with 1xGTX1080Ti
Constant LR with momentum
Cyclical Learning Rate
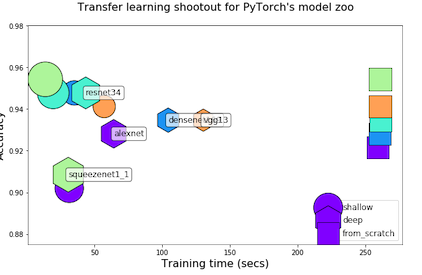
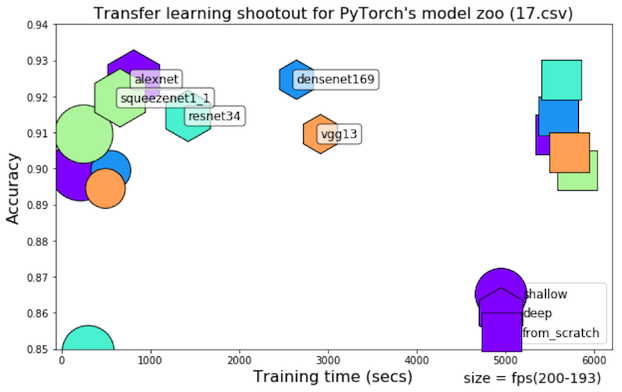
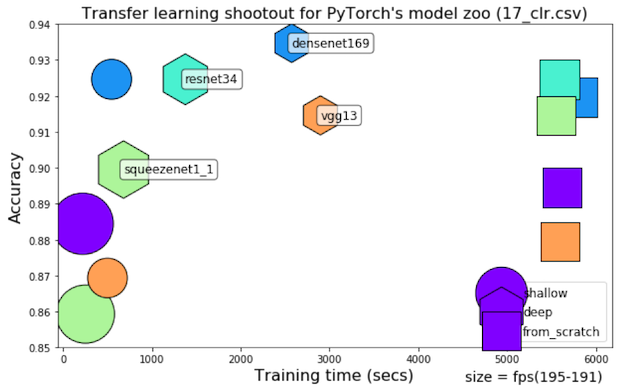

 221 Dec 31, 2022
221 Dec 31, 2022
 38 Dec 13, 2022
38 Dec 13, 2022
 2.3k Jan 02, 2023
2.3k Jan 02, 2023
 66 Dec 15, 2022
66 Dec 15, 2022
 43 Dec 29, 2022
43 Dec 29, 2022
 5 Nov 10, 2022
5 Nov 10, 2022
 3 Feb 15, 2022
3 Feb 15, 2022
 4.1k Jan 02, 2023
4.1k Jan 02, 2023
 56 Nov 24, 2022
56 Nov 24, 2022
 21 Dec 22, 2022
21 Dec 22, 2022
 55 Dec 21, 2022
55 Dec 21, 2022
 2.5k Jan 02, 2023
2.5k Jan 02, 2023
 15 Dec 02, 2022
15 Dec 02, 2022
 2 Dec 17, 2021
2 Dec 17, 2021
 190 Dec 29, 2022
190 Dec 29, 2022
 149 Jan 04, 2023
149 Jan 04, 2023
 12 Sep 08, 2022
12 Sep 08, 2022
 44 Jan 04, 2023
44 Jan 04, 2023
 2 May 05, 2022
2 May 05, 2022
 41 Oct 27, 2022
41 Oct 27, 2022